Topological Sort and Graph Search
Table of Contents
1 Reading
Read Bailey sections 16.4.1 and 16.4.2
2 Video
Here is a video lecture for today's lesson.
The video contains sections on
- Topological sort intro (0:25)
- A first algorithm for topological sort (4:23)
- Analyzing topological sort (9:31)
- Dense vs sparse graphs (16:32)
- Topological sort take 2 (20:27)
- Graph traversal (25:02)
- Breadth-first and depth-first search (35:18)
- Shortest paths with BFS (40:20)
- BFS vs DFS (46:50)
- Shortest paths on a weighted graph (48:26)
The Panopto viewer has table of contents entries for these sections: https://carleton.hosted.panopto.com/Panopto/Pages/Viewer.aspx?id=e61f48cb-f8d8-4b0c-9b06-acd9017bfa11
3 Learning Goals
After this lesson you will be able to
- Perform three classic graph algorithms: topological sort, breadth-first search, and depth-first search
- Analyze the running time of graph algorithms
4 Topological Sort1
Problem: Given a DAG (directed acyclic graph) \(G=(V,E)\), output all vertices in an order such that no vertex appears before another vertex that has an edge to it.
Example input:
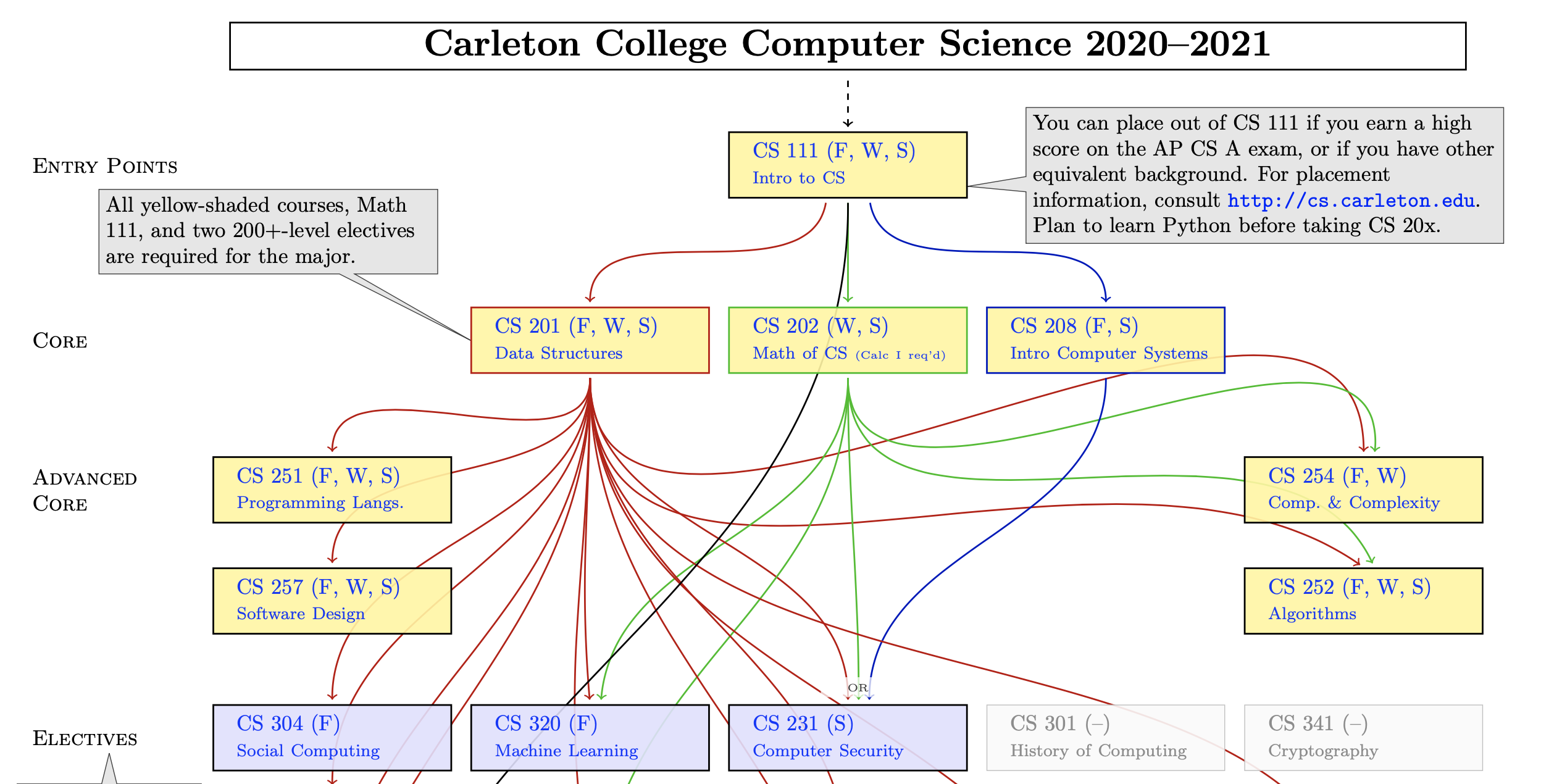
Example output: 111, 202, 201, 252, 304, 208, 251, 254, 320, 257, 231
- Why do we perform topological sorts only on DAGs?
- Because a cycle means there is no correct answer
- Is there always a unique answer?
- No, there can be 1 or more answers; depends on the graph
Graph with 5 topological orders:
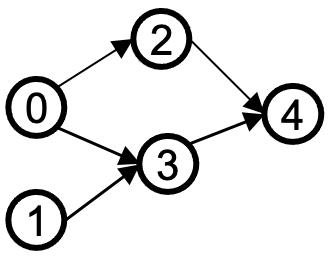
- Do some DAGs have exactly 1 answer?
- Yes, including all lists
- Uses:
- Figuring out how to graduate
- Computing an order in which to recompute cells in a spreadsheet
- Determining an order to compile files using a Makefile
- In general, taking a dependency graph and finding an order of execution
- …
4.1 A First Algorithm for Topological Sort
- Label (mark) each vertex with its in-degree
- Think "write in a field in the vertex"
- Could also do this via a data structure (e.g., array) on the side
- While there are vertices not yet output:
- Choose a vertex \(v\) with labeled with in-degree of 0
- Output \(v\) and conceptually remove it from the graph
- For each vertex \(u\) adjacent to \(v\) (i.e. \(u\) such that \((v,u)\) in \(E\)), decrement the in-degree of \(u\)
Step 1
| Node | 111 | 201 | 202 | 208 | 231 | 251 | 252 | 254 | 257 | 304 | 320 |
| Removed? | |||||||||||
| In-degree | 0 | 1 | 1 | 1 | 3 | 1 | 2 | 2 | 1 | 1 | 2 |
Step 2 (output: 111)
| Node | 111 | 201 | 202 | 208 | 231 | 251 | 252 | 254 | 257 | 304 | 320 |
| Removed? | y | ||||||||||
| In-degree | 0 | 0 | 0 | 0 | 3 | 1 | 2 | 2 | 1 | 1 | 2 |
Step 3 (output: 111 202)
| Node | 111 | 201 | 202 | 208 | 231 | 251 | 252 | 254 | 257 | 304 | 320 |
| Removed? | y | y | |||||||||
| In-degree | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 1 | 1 | 1 | 1 |
Step 4 (output: 111 202 208)
| Node | 111 | 201 | 202 | 208 | 231 | 251 | 252 | 254 | 257 | 304 | 320 |
| Removed? | y | y | y | ||||||||
| In-degree | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
Step 5 (output: 111 202 208 201)
| Node | 111 | 201 | 202 | 208 | 231 | 251 | 252 | 254 | 257 | 304 | 320 |
| Removed? | y | y | y | y | |||||||
| In-degree | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
At this point the remaining nodes can be processes in any order, as they all have degree 0.
- Needed a vertex with in-degree 0 to start
- Will always have at least 1 because no cycles
- Ties among vertices with in-degrees of 0 can be broken arbitrarily
- Can be more than one correct answer, by definition, depending on the graph
4.1.1 Running Time
labelEachVertexWithItsInDegree();
for(ctr = 0; ctr < numVertices; ctr++) {
v = findNewVertexOfDegreeZero();
put v next in output
for each w adjacent to v
w.indegree--;
}
- What is the worst-case running time?
- Initialization \(O(|V|+|E|)\)
- Sum of all find-new-vertex \(O(|V|^2)\) (because each \(O(|V|)\))
- Sum of all decrements \(O(|E|)\)
- So total is \(O(|V|^2)\)
- Is \(O(|V|^2)\) good or bad? It depends on the kind of graph we're dealing with
5 Aside: Dense vs Sparse
- Recall: In an undirected graph, \(0 \le |E| < |V|^2\)
- Recall: In a directed graph: \(0 \le |E| \le |V|^2\)
- So for any graph, \(O(|E|+|V|^2)\) is \(O(|V|^2)\)
- Another fact: If an undirected graph is connected, then \(|V|-1 \le |E|\)
- Because \(|E|\) is often much smaller than its maximum size, we do not always approximate \(|E|\) as \(O(|V|^2)\)
- This is a technically correct upper bound, it just is often not tight (i.e., a lower upper bound would be more appropriate)
- If it is tight, we say the graph is dense
- Less precisely, dense means lots of edges
- If \(|E|\) is \(O(|V|)\) we say the graph is sparse
- Less precisely, sparse means most possible edges missing
So, the \(O(|V|^2)\) running time of our topological sort is fine for dense graphs, but poor performance for a sparse graph
6 A Better Topological Sort
- The trick is to avoid searching for a zero-degree node every time!
- Keep the pending zero-degree nodes in a list, stack, queue, or something
- Order we process them affects output but not correctness or efficiency provided add/remove are both \(O(1)\)
Using a queue:
- Label each vertex with its in-degree, enqueue 0-degree nodes
- While queue is not empty
- v = queue.remove()
- Output v and remove it from the graph
- For each vertex u adjacent to v (i.e. u such that (v,u) in E), decrement the in-degree of u, if new degree is 0, add it to the queue
labelAllAndEnqueueZeros();
for(ctr = 0; ctr < numVertices; ctr++){
v = queue.remove();
put v next in output
for each w adjacent to v {
w.indegree--;
if (w.indegree == 0)
queue.add(v);
}
}
- What is the worst-case running time?
- Initialization: \(O(|V|+|E|)\)
- Sum of all enqueues and dequeues: \(O(|V|)\)
- Sum of all decrements: \(O(|E|)\)
- So total is \(O(|V| + |E|)\) — much better for sparse graph!
7 Graph Search
- Next problem: For an arbitrary graph and a starting node \(v\), find all nodes reachable from \(v\) (i.e., there exists a path from \(v\))
- Possibly do something for each node
- Examples: print to output, set a field, etc.
- Basic idea:
- Keep following nodes
- But mark nodes after visiting them, so the traversal terminates and processes each reachable node exactly once
traverseGraph(Node start) {
Set pending = emptySet()
pending.add(start)
mark start as visited
while(pending is not empty) {
next = pending.remove()
for each node u adjacent to next
if(u is not marked) {
mark u
pending.add(u)
}
}
}
- Assuming add and remove are \(O(1)\), entire traversal is \(O(|V| + |E|)\)
- The order we traverse depends entirely on \(add\) and \(remove\)
- Popular choice: a stack depth-first graph search (DFS)
- Popular choice: a queue breadth-first graph search (BFS)
- DFS and BFS are big ideas in computer science
- Depth: recursively explore one part before going back to the other parts not yet explored
- Breadth: explore areas closer to the start node first
7.1 Examples
A tree is a graph and DFS and BFS are particularly easy to "see"
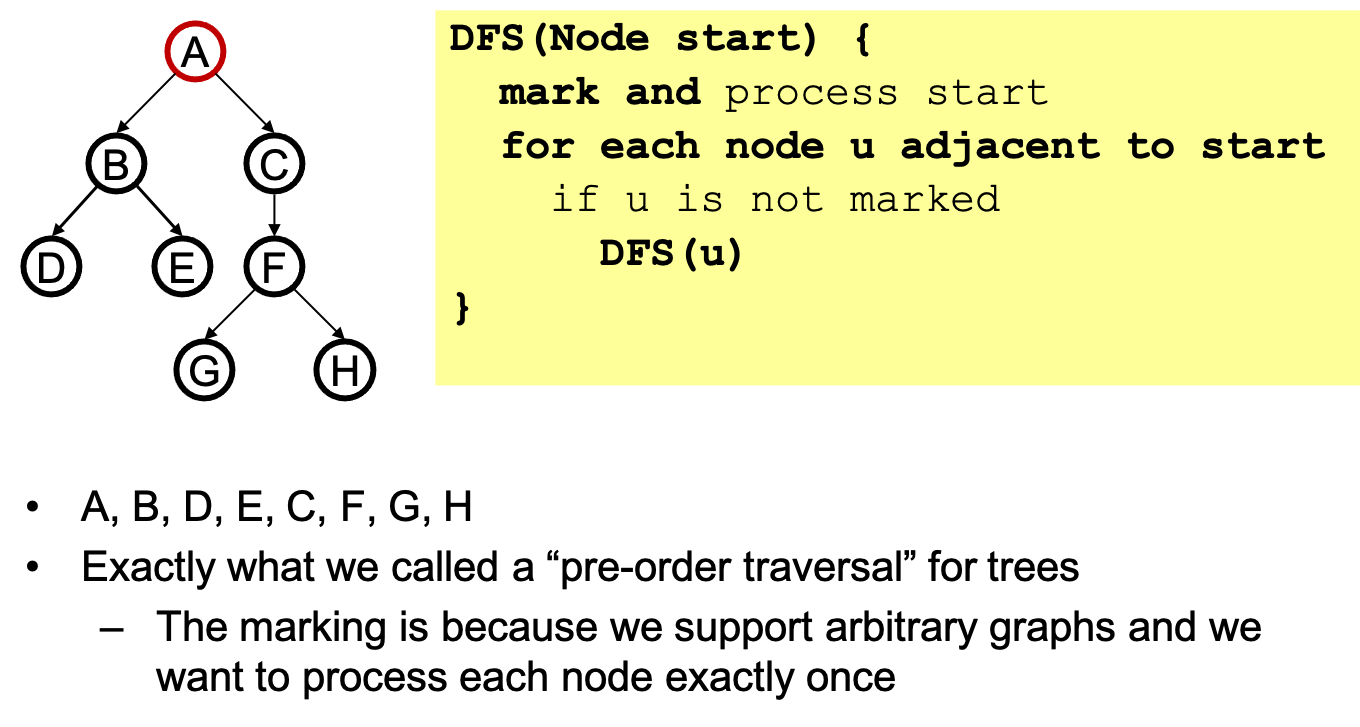


BFS useful for:
- Driving directions
- Cheap flight itineraries
- Network routing
- Critical paths in project management
7.2 Comparison
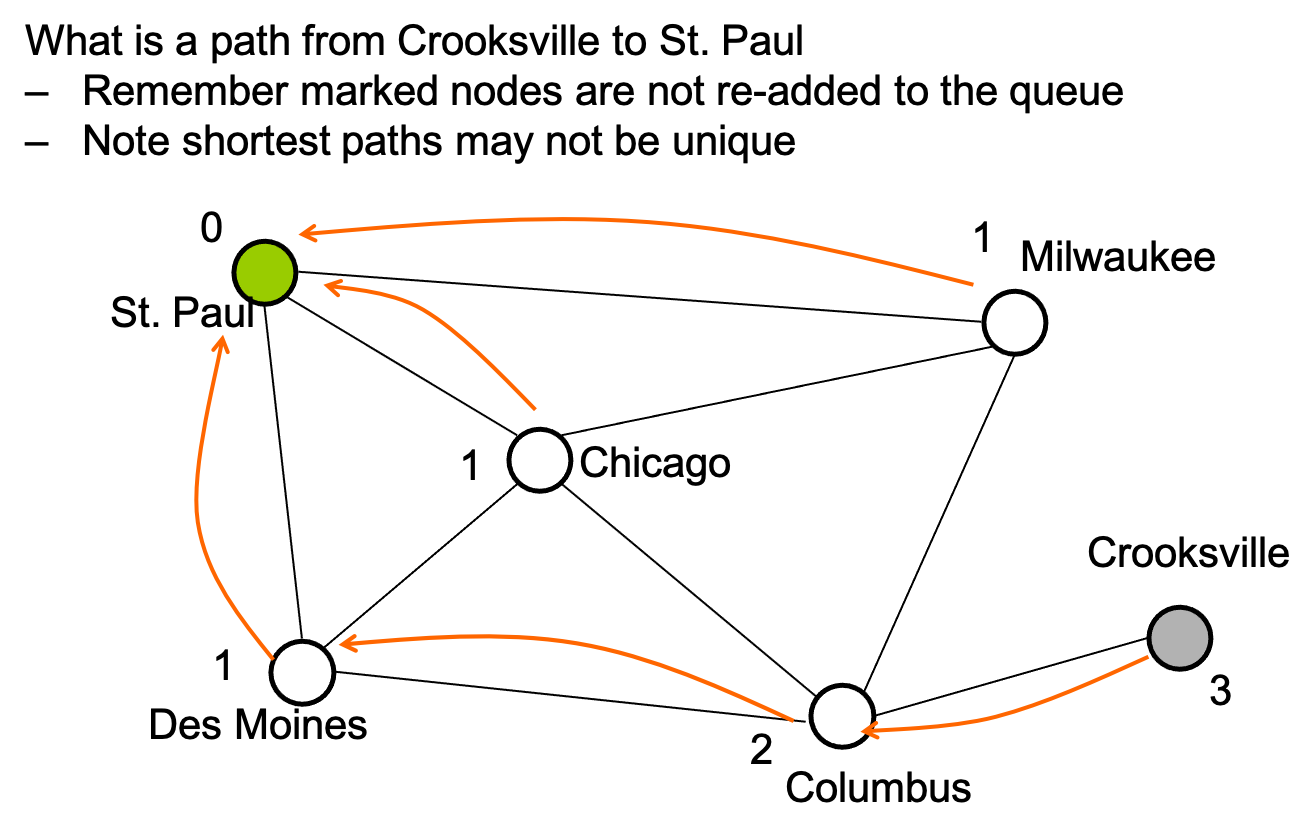
- Breadth-first always finds shortest paths, i.e., "optimal solutions"
- Better for "what is the shortest path from x to y"
- BFS to find the minimum path length from \(v\) to \(u\) in \(O(|E|+|V|)\)
- Actually, can find the minimum path length from \(v\) to every node
- Still \(O(|E|+|V|)\)
- No faster way for a specific destination in the worst-case
- But depth-first can use less space in finding a path
- If longest path in the graph is \(p\) and highest out-degree is \(d\) then DFS stack never has more than \(d \times p\) elements
- But a queue for BFS may hold \(O(|V|)\) nodes
7.3 Saving the Path
- Our graph searches can answer the reachability question:
- Is there a path from node x to node y?
- But what if we want to actually output the path?
- Like getting driving directions rather than just knowing it's possible to get there!
- How to do it:
- Instead of just marking a node, store the previous node along the path (when processing \(u\) causes us to add \(v\) to the search, record that \(u\) comes before \(v\))
- When you reach the goal, follow path fields back to where you started (and then reverse the answer)
- If just wanted path length, could put the integer distance at each node instead
7.4 Shortest Path on Weighted Graphs?
Given a weighted graph and node v, find the minimum-cost path from v to every node. BFS doesn't work!
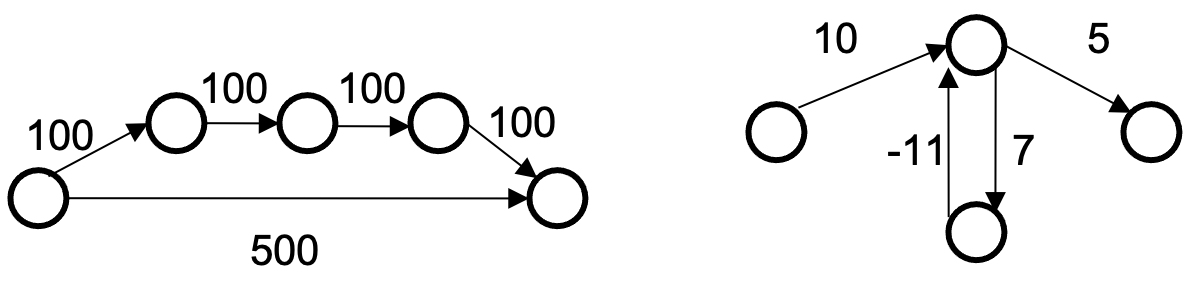
We will need a different algorithm that takes into account the weights of the edges.
8 Practice Problems2
- Under what conditions is a topological sort of the vertices of a graph possible?
- Implement a Java version of the breadth-first search pseudocode given above. It should be a method
public int[] bfs(Graph G, int source)whereGraphis the Graph class provided by algs4. In this class, ints are used to represent the vertices, so thesourceparameter is the vertex from which to begin the search. The method should return an array of integers of lengthG.V()(i.e., one entry for each vertex) where the entry at indexiis the vertex that comes before vertexion the shortest path fromsource. You will need a similar, separate array of booleans to keep track of which vertices the search has visited. - Is the depth-first search animation at https://visualgo.net/en/dfsbfs a recursive or stack-based implementation of DFS?
Give all possible topological sorts for the following graph:
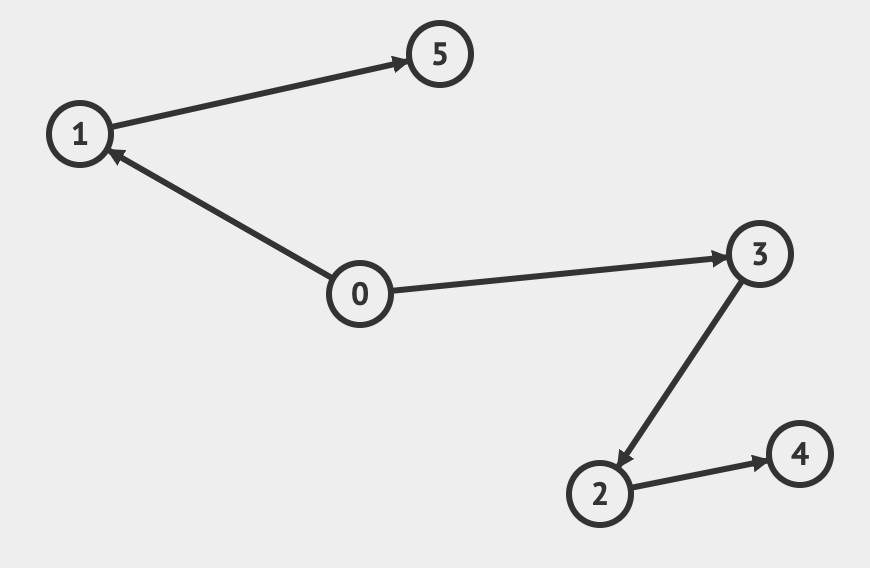
9 Learning Block
- Summary
- Topological sort takes a directed acyclic graph (DAG) and processes the nodes in an order that follows the dependency information encoded in the graph
- Used a queue of pending nodes to efficiently implement the algorithm
- Dense graph = lots of edges (\(|E|\) is \(O(|V|)\)), sparse graph = many potential edges missing (\(|E|\) is \(O(|V|)\))
- Graph traversal similarly kept track of nodes to explore
- Each time a node was removed from the set to explore, all of its unvisted neighbors were added
- If we use a queue to hold the nodes to explore, we get breadth-first search
- If we use a stack, we get depth-first search
- Saw several examples of how these searches played out
- Discussed how BFS can be used to find the shortest paths in a graph
- Topological sort takes a directed acyclic graph (DAG) and processes the nodes in an order that follows the dependency information encoded in the graph
- Questions?
- Form questions
- Go over
bfscode - Lab work time
Footnotes:
Disclaimer: do not use this for advising purposes!
Solutions:
- The graph must be directed and acyclic.
public int[] bfs(Graph G, int source) { int[] edges = new int[G.V()]; boolean[] marked = new boolean[G.V()]; Queue<Integer> toExplore = new LinkedList<>(); toExplore.add(source); marked[source] = true; while (!toExplore.isEmpty()) { // while we have unexplored nodes int cur = toExplore.remove(); // get a node to explore next from the queue for (int v : G.adj(cur)) { // for each of its neighbors if (!marked[v]) { // if we haven't visted neighbor v before marked[v] = true; // visit it edges[v] = cur; // record that cur comes before v on the path from source toExplore.add(v); // add v to our queue of nodes to explore } } } return edges; }
It uses a recursive implementation:
DFS(u): for each neighbor v of u if v is unvisited, tree edge, DFS(v) else if v is explored, bidirectional/back edge else if v is visited, forward/cross edge- 0, 1, 5, 3, 2, 4
- 0, 1, 3, 5, 2, 4
- 0, 1, 3, 2, 5, 4
- 0, 1, 3, 2, 4, 5
- 0, 3, 1, 5, 2, 4
- 0, 3, 1, 2, 5, 4
- 0, 3, 1, 2, 4, 5
- 0, 3, 2, 1, 5, 4
- 0, 3, 2, 1, 4, 5
- 0, 3, 2, 4, 1, 5