Hashing I
Table of Contents
1 Reading
Read Sections 15.4.3 and 15.4.4 of Bailey. Ignore figures 15.11 and 15.12, those relate to the the performance analysis section that will be reading for next class.
2 Why Hash Tables?
For a Map with \(n\) key-value pairs:
| Data structure | put |
contains |
remove |
|---|---|---|---|
| Unsorted linked list | \(O(n)\) | \(O(n)\) | \(O(n)\) |
| Unsorted array | \(O(n)\) | \(O(n)\) | \(O(n)\) |
| Sorted linked list | \(O(n)\) | \(O(n)\) | \(O(n)\) |
| Sorted array | \(O(n)\) | \(O(\log n)\) | \(O(n)\) |
| (SPOILERS) Balanced tree | \(O(\log n)\) | \(O(\log n)\) | \(O(\log n)\) |
| Magic array | \(O(1)\) | \(O(1)\) | \(O(1)\) |
- Sufficient magic:
- Remove the requirement that elements are ordered [easy]
- Use key to compute array index for an item in \(O(1)\) time [doable]
- Have a different index for every item [magic]
2.1 Turn Key Into Array Index
- Aim for constant time
put,get,contains, andremove- On average under some often-reasonable assumptions
- A hash table is an array of some fixed size
Basic idea:
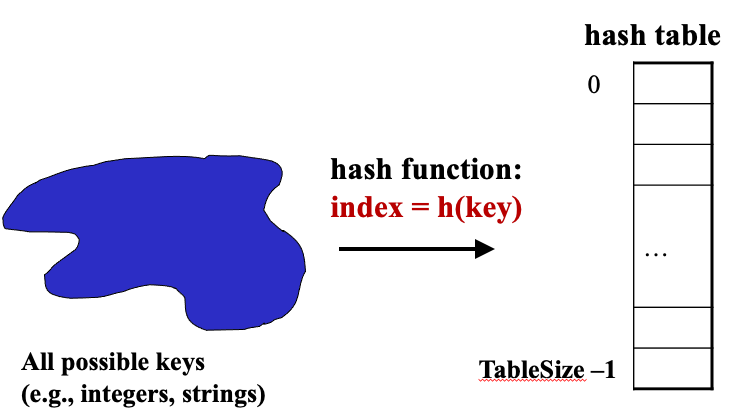
- An ideal hash function:
- Fast to compute
- Rarely hashes two used keys to the same index
- Often impossible in theory but easy in practice
- We will handle collisions next class
2.2 Example: Hashing Intgers
- Simple hash function:
- \(h(k) = k\; \%\; \mathrm{TableSize}\)
- Fairly fast and natural
- Example:
- TableSize = 10
- Insert 7, 18, 41, 34, 10
- (ignoring the values of these key-value pairs—we’ll think of these as data along for the ride)
index 0 1 2 3 4 5 6 7 8 9
+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| 10 | 41 | | | 34 | | | 7 | 18 | |
+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+
2.3 Other Kinds of Keys
- If keys aren't ints, they need to be converted to ints
- Trade-off: speed versus distinct keys hashing to distinct ints
- Very important example: Strings
- Possible keys are strings of the form \(k = s_0s_1s_2s...s_{m-1}\)
- (where \(s_i\) are chars: between 0 to 65,535, inclusive)
- Possible keys are strings of the form \(k = s_0s_1s_2s...s_{m-1}\)
- Some choices: Which approach will be the most likely to give us unique ints?
- i.e., avoid hashing two different strings to the same array index
- \(h(k) = s_0\; \%\; \mathrm{TableSize}\)
- \(h(k) = (s_0 + s_1 + … s_{m-1})\; \%\; \mathrm{TableSize}\)
- \(h(k) = (s_0 + s_1 * 31 + s_2 * 31^2 + … s_{m-1} * 31^{m-1})\; \%\; \mathrm{TableSize}\)
(I'll demonstrate this is what Java does)
public class HashTest { public static void main(String[] args) { System.out.println("a".hashCode()); System.out.println("aa".hashCode()); System.out.println("aaa".hashCode()); System.out.println(); System.out.println(97 + 97 * 31); System.out.println(97 + 97 * 31 + 97 * 31 * 31); } }
2.4 Analysis
So, assuming a good hash function (fast and rarely hashes different keys to the same number), what is the efficiency of put, get, contains, and remove?
- Our data structure will have an internal array of key-value pairs (
Association) calledtable put(K key, V value)- use
int index = key.hashCode() % table.lengthto get array index, \(O(1)\) - use
table[index] = new Association(key, value)to store the new key value pair at that index, \(O(1)\)- Will replace whatever was there before
- So
putis \(O(1)\)
- use
get(K key)- use
int index = key.hashCode() % table.lengthto get array index, \(O(1)\) return table[index].getValue(), \(O(1)\)- So
getis \(O(1)\)
- use
contains(K key)- use
int index = key.hashCode() % table.lengthto get array index, \(O(1)\) return table[index] != null, \(O(1)\)- So
containsis \(O(1)\)
- use
remove(K key)- use
int index = key.hashCode() % table.lengthto get array index, \(O(1)\) - use
table[index] = nullto remove the key-value pair from the array, \(O(1)\) - So
removeis \(O(1)\)
- use
Unresolved issues (next class!):
- How big do we make
table? - What happens when two keys hash to the same index?
- What happens when
tablegets full?
These constant-time operations depend on good solutions to these questions.
3 Practice Problems1
- What is hashing, and why is hashing a good way of implementing a map?
- Is it possible for a hash table to have two entries with equal keys?
- Is it possible for a hash table to have two entries with equal values?
For Java strings consisting of only one character,
hashCodesimply returns the value of thatchar. Suppose we have a hash table with an array of length 20. What will the array look like after the following keys have beenput: "s", "a", "n", "d", "w", "o", "r", "m"? For reference here is a table ofcharvalues in Java:Dec = Decimal Value Char = Character '5' has the int value 53 if we write '5'-'0' it evaluates to 53-48, or the int 5 if we write char c = 'B'+32; then c stores 'b' Dec Char Dec Char Dec Char Dec Char --------- --------- --------- ---------- 0 NUL (null) 32 SPACE 64 @ 96 ` 1 SOH (start of heading) 33 ! 65 A 97 a 2 STX (start of text) 34 " 66 B 98 b 3 ETX (end of text) 35 # 67 C 99 c 4 EOT (end of transmission) 36 $ 68 D 100 d 5 ENQ (enquiry) 37 % 69 E 101 e 6 ACK (acknowledge) 38 & 70 F 102 f 7 BEL (bell) 39 ' 71 G 103 g 8 BS (backspace) 40 ( 72 H 104 h 9 TAB (horizontal tab) 41 ) 73 I 105 i 10 LF (NL line feed, new line) 42 * 74 J 106 j 11 VT (vertical tab) 43 + 75 K 107 k 12 FF (NP form feed, new page) 44 , 76 L 108 l 13 CR (carriage return) 45 - 77 M 109 m 14 SO (shift out) 46 . 78 N 110 n 15 SI (shift in) 47 / 79 O 111 o 16 DLE (data link escape) 48 0 80 P 112 p 17 DC1 (device control 1) 49 1 81 Q 113 q 18 DC2 (device control 2) 50 2 82 R 114 r 19 DC3 (device control 3) 51 3 83 S 115 s 20 DC4 (device control 4) 52 4 84 T 116 t 21 NAK (negative acknowledge) 53 5 85 U 117 u 22 SYN (synchronous idle) 54 6 86 V 118 v 23 ETB (end of trans. block) 55 7 87 W 119 w 24 CAN (cancel) 56 8 88 X 120 x 25 EM (end of medium) 57 9 89 Y 121 y 26 SUB (substitute) 58 : 90 Z 122 z 27 ESC (escape) 59 ; 91 [ 123 { 28 FS (file separator) 60 < 92 \ 124 | 29 GS (group separator) 61 = 93 ] 125 } 30 RS (record separator) 62 > 94 ^ 126 ~ 31 US (unit separator) 63 ? 95 _ 127 DEL- For each of the following possible
hashCodeimplementations: Is the following a legalhashCodemethod for aPointclass, according to the requirement that equivalent points should have the same hash code? Does it distribute the hash codes well between objects? Why or why not?public int hashCode() { return x * y; }
public int hashCode() { return 42; }
public int hashCode() { Random rng = new Random(); return rng.nextInt(); }
- Write a
hashCodemethod for aDateclass, whose fields are a year, month, and day, as integers. Follow the general requirement that equivalent objects should have the same hash code. - Write a
hashCodemethod for aStudentclass, whose fields are a name (a string), age (an integer), student ID number (an integer), and favorite data structure (a string). Follow the general requirement that equivalent objects should have the same hash code.
Footnotes:
Solutions:
- Hashing is a process of mapping element values to integer indexes and storing the elements at those indexes in an array. Hashing is a good way of implementing a map because it provides theoretically O(1) runtime for adding, removing, and searching a set.
- No. If the keys were equal, the second key inserted would have found the first (i.e., been hashed to the same index), and thus not have been inserted.
- Yes, there is no restriction that values must be unique. Many keys can be associated with the same values.
internal array: +---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+ |"d"| | | | | | | | |"m"|"n"|"o"| | |"r"|"s"| |"a"| |"w"| +---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <--- index
- This is a legal hashCode implementation, according to the requirement. It distributes hash codes somewhat well, but it has certain groups of points that will collide with each other unnecessarily (for example, every point with an x-coordinate or y-coordinate of 0 will have the same hash code).
- This is a legal hashCode implementation, according to the requirement. But it distributes hash codes extremely poorly; literally it could not be worse in that respect, because every point has the same hash code. It's important to note that it is still a technically correct implementation, though it works very poorly in terms of hash table performance.
- This is not a legal hashCode implementation, according to the contract. It does not consistently return the same hash code for the same point object state.
hashCodemethod for aDateclass (the constant multipliers for each component are somewhat arbitrary):public int hashCode() { return 31 * year + 31 * 31 * month + day; }
hashCodemethod for aStudentclass (the constant multipliers for each component are somewhat arbitrary):public int hashCode() { int result = 17; result = result * 31 + name.hashCode(); result = result * 31 + age; result = result * 31 + studentID; result = result * 31 + favorite.hashCode(); return result; }