CS 208 s20 — Introduction; Binary & Hexadecimal
Table of Contents
1 Themes of the Course
To begin, I want to introduce some of the major themes of the course. These will illustrate and motivate aspects of computer systems we will tackle in the coming weeks.
1.1 Memory is Finite
It may seem like an obvious statement, but the physical limits on how much data can be stored in memory have far-reaching consequences. Computer systems employ all sorts of creative strategies and technical solutions to deal with these limits. Finite memory has perhaps surprising consequences when it comes to representing numbers. Consider this simple Java program:
/* int_test.java */ class IntTest { public static void main(String[] args){ int a = 200 * 300 * 400 * 500; System.out.println(a); } }
It goes without saying that we expect the product of four positive numbers to be positive as well. Unfortunately, when compiled and run this code prints a large negative number!
$ javac int_test.java $ java IntTest -884901888
Why in the world does this happen?
The answer is that Java, like C and many other programming languages, uses a finite amount of memory to represent a quantity of type int.
The product we compute requires more memory to represent that is available for a, and so it overflows.
As a programmer you don't want to be surprised by this kind of phenomenon (it can result in hard-to-find and catastrophic errors), so it's important to understand!
A similarly surprising result occurs when dealing with floating point numbers (non-integers).
Mathematically, multiplication is associative, meaning we can reorder multiplication operations with parentheses and expect the same result.
For example, we might expect the Java code below to print 0.375 twice followed by true.
/* float_test.java */ class FloatTest { public static void main(String[] args){ double x = (2.5 * 0.1) * 1.5; double a = 2.5 * (0.1 * 1.5); System.out.println(x); System.out.println(a); System.out.println(x == a); } }
Again the principle of finite memory strikes! There are many fractions a computer system can only approximate when using a finite amount of memory to represent an infinitely repeating decimal. Thus, we get the following output:
$ javac float_test.java $ java FloatTest 0.375 0.37500000000000006 false
The error in the approximation is very small—only 60 quintillionths—but that's enough to violate our assumption of associativity. A good programmer must always be aware of these limitations when working with floating point numbers.
1.2 Constant Factors Matter
In many areas of computer science, we deliberately ignore constant factors in order to focus on theoretical analysis. This is incredibly useful in understanding algorithms and data structures on a fundamental level. In practice, however, constant factors can have a tremendous impact on performance. The following two examples will illustrate this.
First, operations you may think of as having no cost actually create overhead for a program. Consider two ways of computing a factorial in Java: with a loop and with a recursive function. In both cases, the number of arithmetic operations is the same, so the difference between these two approaches might appear to be one of style rather than substance.
/* excerpt from factorial_test.java */ static int fact_iter(int n) { int acc = 1; for (int i = 2; i < n + 1; i++) { acc *= i; } return acc; } static int fact_rec(int n) { if (n < 2) { return 1; } return fact_rec(n - 1) * n; }
Testing the performance of each function reveals otherwise.
On my computer, computing the factorials for n 0 to 20,000 takes fact_iter 185 milliseconds and fact_rec 716ms.
That makes fact_rec almost four times slower than the iterative equivalent!
It turns out that making a function call isn't free—there are a number of steps involved that create a lot of extra overhead for the system when a function like fact_rec makes 1000s or 10000s of recursive calls.
What are these steps? We'll get deep into that in week 5 of the course.
An even more dramatic example of constant factors involves features of computer systems designed to make programs faster. The catch is that these features are (a) invisible to the programmer and (b) depend on code being structured in a specific way. Here's the scenario: we have a large two-dimensional array in Java that we fill with random values
/* except from loops_test.java */ int ARR_DIM = 10000; double[][] arr = new double[ARR_DIM][ARR_DIM]; for (int i = 0; i < ARR_DIM; i++) { for (int j = 0; j < ARR_DIM; j++) { arr[i][j] = Math.random(); } }
and our task is to sum up the values of the array. Now compare these two ways of computing the sum—can you spot the difference?
/* excerpt from loops_test.java */ // approach A double acc = 0; for (int i = 0; i < ARR_DIM; i++) { for (int j = 0; j < ARR_DIM; j++) { acc += arr[i][j]; } } // approach B acc = 0; for (int j = 0; j < ARR_DIM; j++) { for (int i = 0; i < ARR_DIM; i++) { acc += arr[i][j]; } }
The only difference is that the loops have been switched: approach A loops over j inside a loop over i while approach B does the reverse.
Big-O analysis tells use that these approaches are equivalent, but timing them tells a different story.
On my computer, approach A takes 98 milliseconds, while approach B takes a whopping 3863 milliseconds!
Swapping a single pair of loops made summing the array 39 times slower.
This is a huge deal in any context where efficiency matters.
The underlying reason for this difference relates to the idea of caches and how they are used by modern computer systems.
We'll leave the details until week 7—the lesson right now is that it can be really important to understand what's going on underneath the surface when a computer runs your code.
1.3 Layers of Abstraction
The final major theme I want to introduce is the idea that computer systems are made up of layers of abstraction. For example, say that I'm streaming music from Spotify and writing code at the same time on my laptop—what tasks does it have to perform?
- Spotify needs to send, receive, and process network packets (units of data sent over the Internet)
- Spotify needs to continuously send data to an audio device
- Spotify, the text editor, the terminal, and the operating system itself all need to update the screen
- When I save a file, the text editor needs to write to write information to the disk
- When I compile my code, the compiler needs to read source code off the disk and write out the executable file, probably producing command line output as well
- etc., etc.
How are all these simultaneous and potentially conflicting operations all being effectively coordinated? It's the role of the operating system to abstract these messy details and provide clean, usable interfaces to applications like Spotify and the text editor. This way, each program operates under the convenient illusion that it is the only one using these resources. Application developers don't have to care about handling all the complicated coordination. Furthermore, no application can accidentally (or deliberately) mess around with data in memory belonging to another application. In the background, it's the operating system and the system hardware protecting applications from each other and handling the rapid switching between all of these tasks to give a smooth real-time appearance.
CS 208 will focus on the hardware/software interface from a programmer's perspective. This lives within the Instruction Set Architecture, Operating System, and Compiler/Interpreter in this diagram of computer system layers.
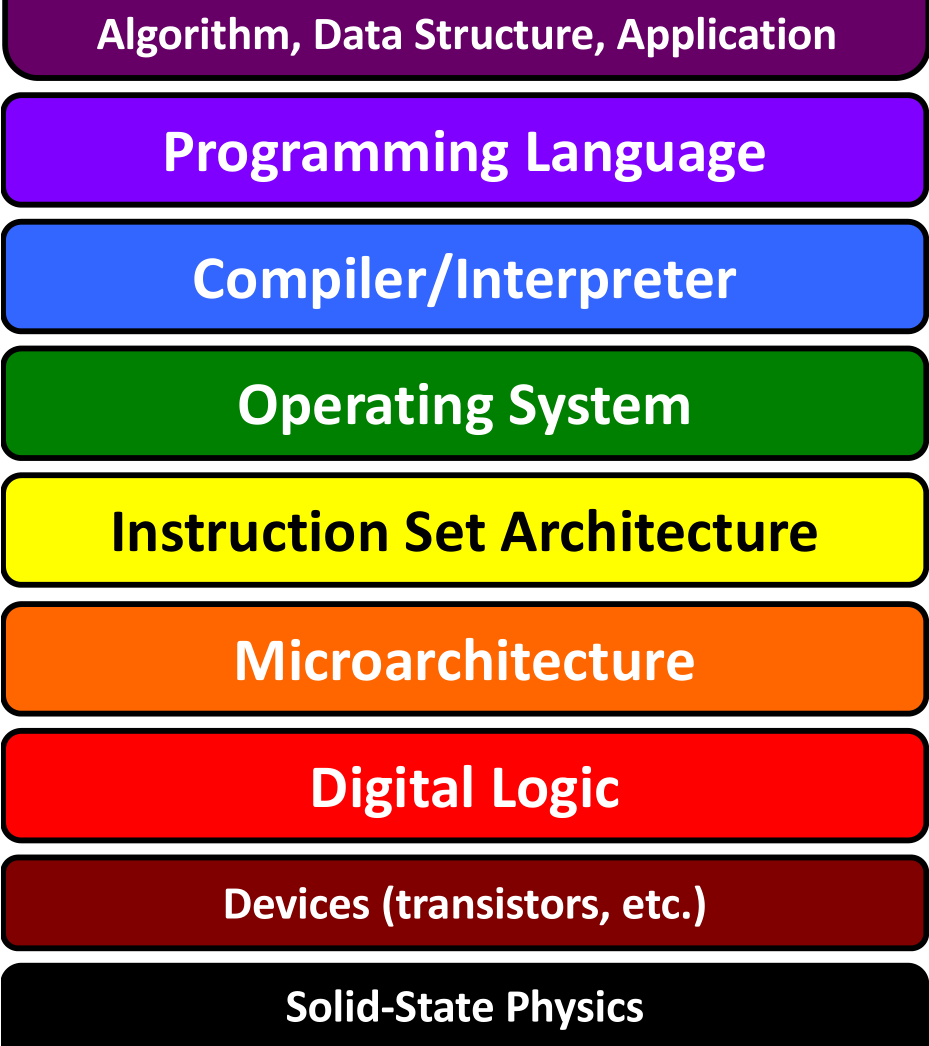
2 Reading: Hardware Organization
Please read section 1.4.1 in the CSPP textbook (p. 8-10). A basic familiarity with the primary hardware components of a computer system will be important background for many parts of this course. The whole of chapter 1 is a worthwhile preview of many of the topics we'll cover (and more), but this section is the essential piece.
3 Binary & hexadecimal
Many parts of this course will involve thinking about data storage and manipulation at a very low level.
- binary = base 2
- base 10 (regular decimal numbers) has a 1s, 10s, 100s digit, etc.
- the number 23 is \(2\times 10 + 3 \times 1\)
- 1s, 10s, 100s, … can be written as \(10^0\), \(10^1\), \(10^2\), …
- hence base 10 numbers
- binary just substitutes a base of 2 for a base of 10
- \(2^0\), \(2^1\), \(2^2\), …
- 1s, 2s, 4s, …
- the binary number 11 is \(1\times 2 + 1\times 1\) or 3 in base 10
- the base of a numbering system also indicates how many unique digits it has
- base 10 has the digits 0–9, after 9 we carry over to the next larger place
- base 2 has two digits, 0 and 1
- why use base 2 for computing? It's a natural fit with presence/absence of electric current or high vs low voltage
- a single binary digit is called a bit, the fundamental unit of digital data
- it's also very common to talk about data in terms of bytes (8 bits to a byte)
- QUICK CHECK: how many bits do you need to represent the base 10 number 17? (answer below)
- QUICK CHECK: how many different values can 6 bits represent? (answer below)
- base 10 (regular decimal numbers) has a 1s, 10s, 100s digit, etc.
- hexadecimal = base 16
- same principle as before
- \(16^0\), \(16^1\), \(16^2\), … \(\rightarrow\) 1s, 16s, 256s
- but why base 16?
- first, base 10 doesn't place nice with binary since 10 isn't a power of 2
- 16 is \(2^4\), giving it the nice property of 4 bits to represent each digit, 2 hex digits to a byte
- a single hex digit, or 4 bits, is called a nybble (little bit of computer scientist humor for you there)
- speaking of hex digits, the 0 to 9 we're used to aren't enough
0x10(hex numbers indicated with 0x prefix) is 16 in base 10, we need digits for 10–15- use the letters a–f
- same principle as before
| base 10 | base 2 | base 16 |
|---|---|---|
| 0 | 0b0000 |
0x0 |
| 1 | 0b0001 |
0x1 |
| 2 | 0b0010 |
0x2 |
| 3 | 0b0011 |
0x3 |
| 4 | 0b0100 |
0x4 |
| 5 | 0b0101 |
0x5 |
| 6 | 0b0110 |
0x6 |
| 7 | 0b0111 |
0x7 |
| 8 | 0b1000 |
0x8 |
| 9 | 0b1001 |
0x9 |
| 10 | 0b1010 |
0xa |
| 11 | 0b1011 |
0xb |
| 12 | 0b1100 |
0xc |
| 13 | 0b1101 |
0xd |
| 14 | 0b1110 |
0xe |
| 15 | 0b1111 |
0xf |
| 16 | 0b10000 |
0x10 |
- the table above shows how hexadecimal counts up to
0xfbefore carrying over to0x10 - QUICK CHECK: what is
0xafin binary and decimal? What would0xaf + 0x1be in hexadecimal? (answers below)
4 Everything is bits!
An important minor theme of CS 208 is that all data stored on a computer system is just bits.
What matters is how those bits are interpreted.
In fact, the same bits can take on completely different and equally valid meanings under different interpretations.
For example, consider 0x4e6f21, what does it mean?
- base 10 integer 5140257
- the characters "No!" (http://www.asciitable.com)
- a nice olive green color (check it out)
- the real number \(7.20303424\times 10^{-39}\)
It's up to the program/programmer to interpret what any sequence of bits actually represents.
5 Homework
It will be well worth your time to get comfortable with binary and hexadecimal now. When we start working with memory addresses, it will be a lot harder if you're still confused about doing arithmetic in base 16. Work through practice problems 2.3 and 2.4 in the CSPP book (on p. 38 and 39). Also very much worth your time: Flippy Bit and the Attack of the Hexadecimals From Base 16