CS 208 s20 — Dynamic Memory Allocation: Free Lists
Table of Contents
1 Video
Here is a video lecture for the material outlined below. It covers CSPP section 9.9.6 through 9.9.14 (p. 847–865). It contains sections on
- introduction (0:05)
- implicit free list concept (2:11)
- minimum block size (12:36)
- epilogue block (14:05)
- basic spreadsheet example (15:14)
- placement policy (19:41)
- quick checks (25:07)
- splitting (28:21)
- false fragmentation (30:14)
- coalescing (32:18)
- boundary tags (37:15)
- coalescing: four cases (39:01)
- when the heap runs out of space (44:55)
- implicit free list implementation (47:18)
- explicit free list (52:27)
- segmented free lists (56:46)
- summary (57:39)
The Panopto viewer has table of contents entries for these sections. Link to the Panopto viewer: https://carleton.hosted.panopto.com/Panopto/Pages/Viewer.aspx?id=b4e87fb0-1367-467a-8add-abc800fe155c
2 Introduction
Implementation questions:
- freeing: how much do we free given just a pointer?
- free block organization: how to keep track of them
- placement: which free block should we choose to fulfill a request
- splitting: what do we do with the remainder of a free block after part of it is allocated
- coalescing: what do we do when a block is freed
3 Implicit Free List
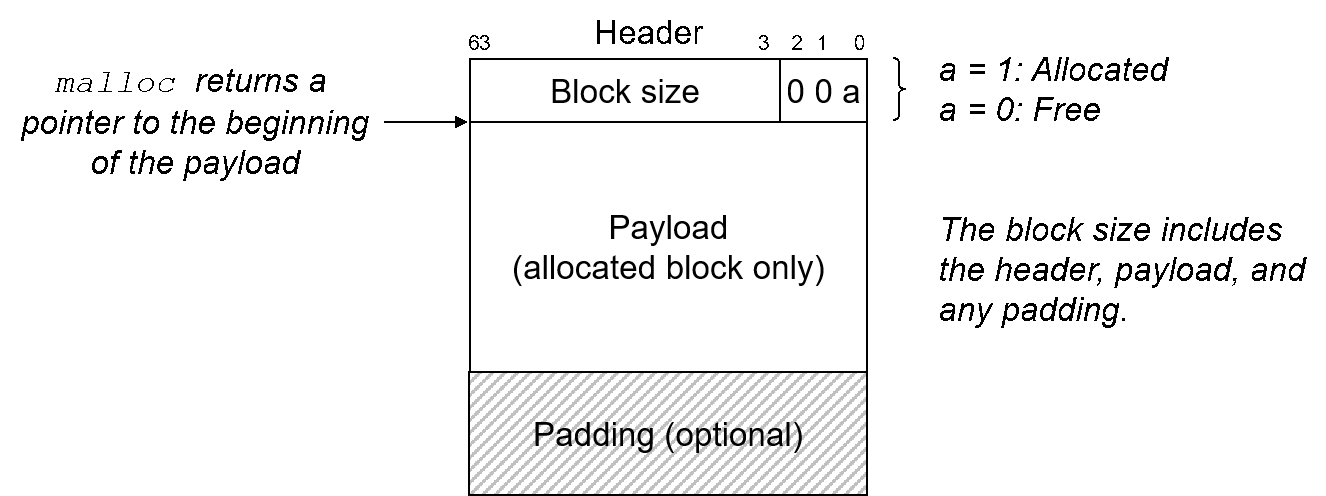
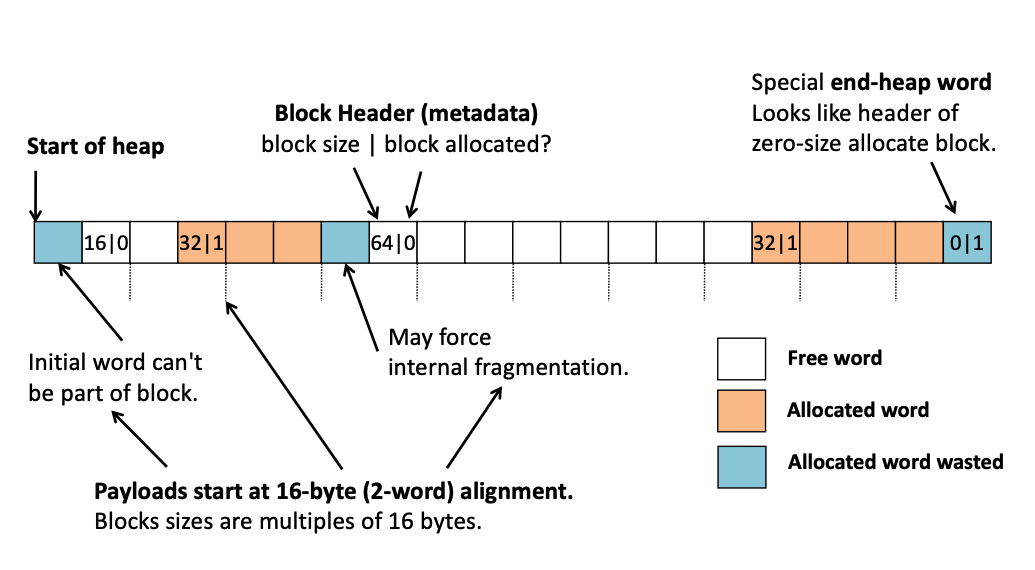
- since block size will always be a multiple of 16 due to alignment, the four lower order bits of the size will always be 0
- we can make efficient use of the header by using these four bits to indicate if the block is allocated or free
- the block size includes the payload and any padding, and is thus an implicit pointer to the start of the next block
- we will need some special block to mark the end of the free list (e.g, allocated bit, size 0)
- implicit free list is simple, but operations are linear in the number of blocks since we have to traverse the list
- alignment combined with block format impose a minimum block size
- https://docs.google.com/spreadsheets/d/1Tj8LTKBBqLodX5K8GbqCVUSWOFur6KzXZshQhx0bF4E/edit?usp=sharing
3.1 Placing Allocated Blocks
- an allocator's placement policy determines the choice of free block to fulfill allocation
- first fit: take the first free block that's big enough
- end up with lots of small "splinters" near the start of the list, large blocks near the end
- next fit: like first fit, but start search where the previous one left off
- unclear if this is better than first fit in practice
- best fit: choose the smallest free block that fits
- better memory utilization, but requires exhaustive search
- first fit: take the first free block that's big enough
- if the fit is not good, an allocator might opt to split the free block into two parts
- if necessary, an allocate will ask the kernel for additional heap memory, inserting a new free block into the list
3.1.1 Quick Checks
Which allocation strategy and requests remove external fragmentation in this heap?1 B3 was the last fulfilled request.
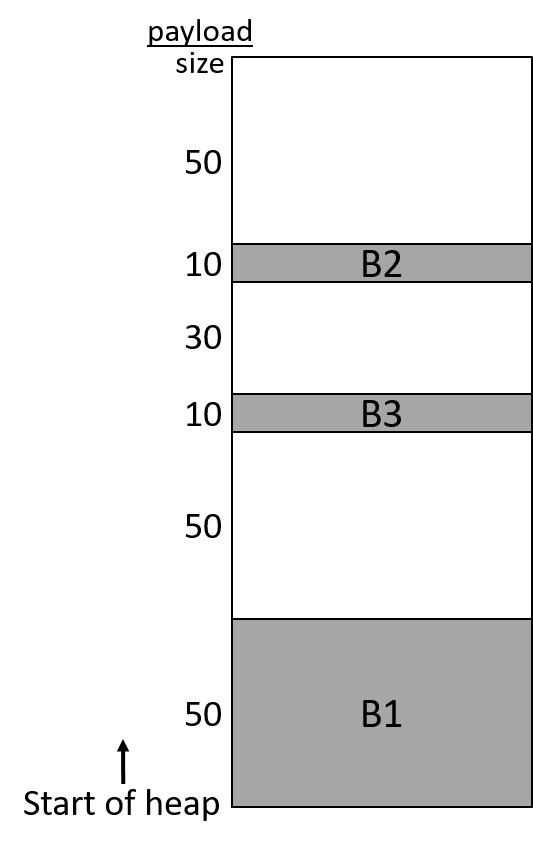
- best-fit: malloc(50), malloc(50)
- first-fit: malloc(50), malloc(30)
- next-fit: malloc(30), malloc(50)
- next-fit: malloc(50), malloc(30)
What is the relationship between throughput and memory utilization?2
3.2 Coalescing Free Blocks
- adjacent free blocks cause false fragmentation—free memory chopped up into many small unusable free blocks
- to address this an allocator must merge (coalesce) adjacent free blocks
- immediate coalescing: merge blocks whenever one is freed
- simple, constant time
- can lead to a form of thrashing where a block is coaslesced and split repeatedly
- deferred coalescing: wait and coaslesce at a later time (e.g., scan the hope when a request fails)
- often the more efficient choice
- immediate coalescing: merge blocks whenever one is freed
3.2.1 Boundary Tags
- with a simple header containing the block size, we can reach the next block, but what about the previous block?
- we'd have to traverse the free list until we reached the current block
- instead, add a footer to each block that's the same as the header
- together, the header and footer form boundary tags
- if we go back one word from the header, we get to the footer of the previous block

- four cases for coalescing:
- previous and next blocks are both allocated
- previous block is allocated, next block is free
- previous block is free, next block is allocated
- previous and next blocks are both free
- https://docs.google.com/spreadsheets/d/1Tj8LTKBBqLodX5K8GbqCVUSWOFur6KzXZshQhx0bF4E/edit?usp=sharing
- boundary tags can introduce significant memory overhead in the case of many small blocks
- fortunately, we only need to have footers in free blocks, since we only care about the size of the previous block when it is free and we want to merge it
- we still need a way to tell if the previous block is allocated, so we'll add that information to one of the unused low-order bits of the header
3.3 Implementation
- section 9.9.12 walks through an implementation of an implicit free list
- beware it is in 32-bit, and your will need to be in 64-bit (generally involves changing constants)
- pay more attention to the text descriptions than the code
- use macros or helper functions like these for pointer manipulation
- make sure you understand why these work/are necessary before you start coding
/* Round up size to the nearest multiple of 16 */ #define ALIGN(size) (((size) + (0xf)) & ~0xf) #define WSIZE 8 #define DSIZE 16 /* Given block ptr bp, compute address of its header and footer (block pointer points to beginning of payload) */ #define HDRP(bp) ((char *)(bp) - WSIZE) #define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE) /* Given block ptr bp, compute address of next and previous blocks */ #define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp))) #define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE)))
4 More Sophisticated Free Lists
4.1 Explicit Free Lists
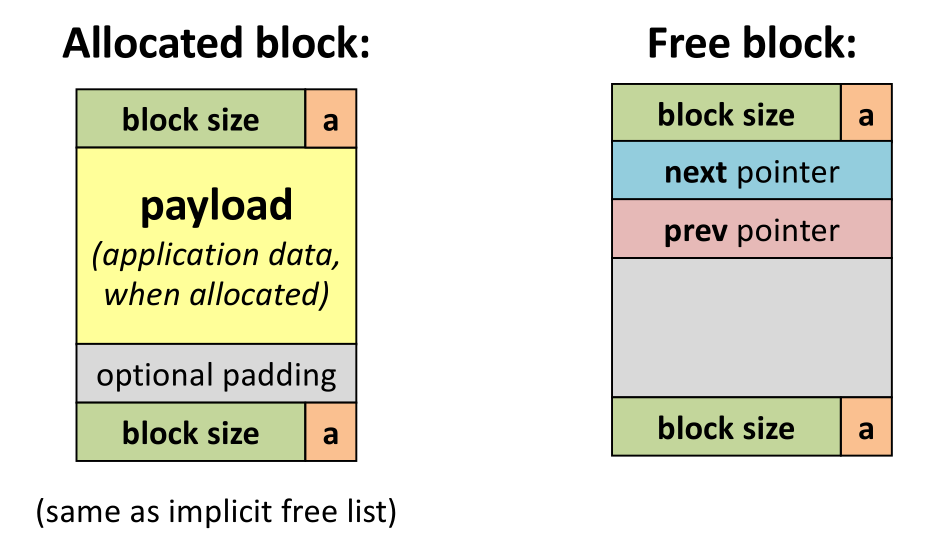
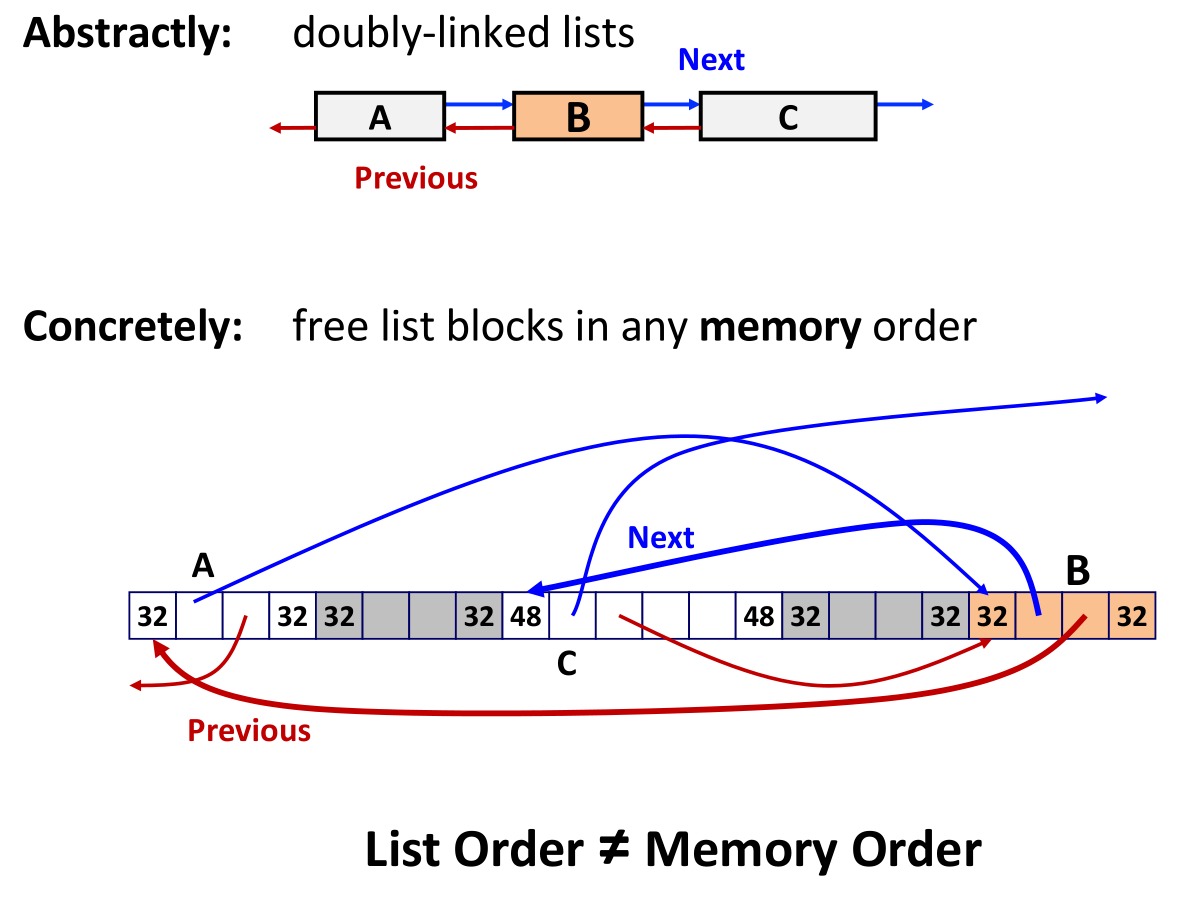
- organize free list as a doubly-linked list using the payload of free blocks (by definition unused) to store the pointers
- now placement is linear in the number of free blocks instead of the total number of blocks
- assuming a first-fit policy:
- if list uses last-in first-out by inserting new free blocks at the head, freeing a block is constant time
- better memory utilization can be achieved if free blocks are maintained in address order
- minimum block size must increase to accomodate list pointers, potentially increasing internal fragmentation
- splitting, boundary tags, coalescing are general to all allocators
- free blocks still coalesce with those adjacent in memory
- remove from list, reinsert at the head
- list can hold blocks in any order, regardless of memory address
- free blocks still coalesce with those adjacent in memory
4.2 Segregated Free Lists
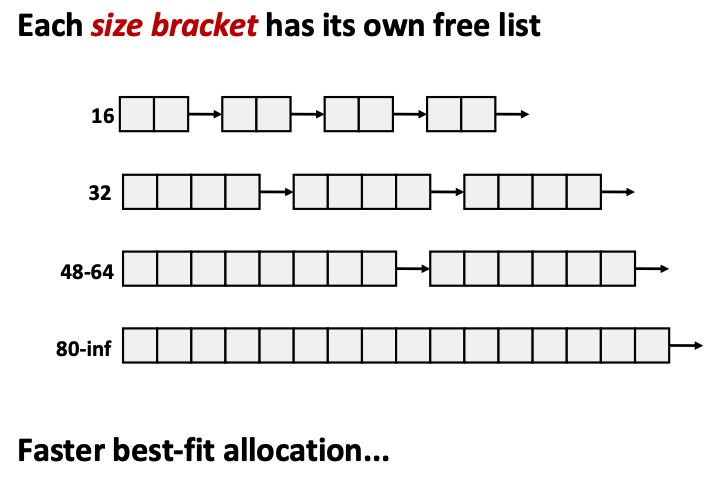
- maintain multiple free lists that group blocks by size classes
- i.e., all free blocks in a particular list are roughly the same size
- could partition by powers of two: {1}, {2}, {3, 4}, {5–8}, …, {1025–2028}, {2049–4096}, {4097--\infinity}
- keep an array of free lists ordered by increasing size
- allocator searches free list corresponding to request size
- if no block found, seaches the next larger list
5 Summary
- Allocator Policies
- All policies offer trade-offs in fragmentation and throughput.
- Placement policy:
- First-fit, next-fit, best-fit, etc.
- Seglists approximate best-fit in low time
- Splitting policy:
- Always? Sometimes? Size bound?
- Coalescing policy:
- Immediate vs. deferred
6 Homework
- CSPP practice problem 9.7 (p. 852, 854)
- Lab 4 due 9pm tonight, May 27
- The week 7 quiz due 9pm tonight, May 27
- Lab 5 posted tonight, due at the end of exams (9pm, June 8)
- no late days can be used!
Footnotes:
2. first-fit: malloc(50), malloc(30) will fill in the gaps between allocated blocks, removing external fragmentation.
- will leave a gap of 30 between B3 and B2,
- will leave the gap of 50 between B1 and B3,
and 4. will leave a gap of 20 between B1 and B3 and a gap of 30 between B3 and B2
There's a trade-off between processing a request faster and finding a better choice of block