CS 208 s21 — Data Structure Representation: structs
Table of Contents
1 Video
Here is a video lecture for the material outlined below. It covers CSPP section 3.9.1 and 3.9.3 (p. 265–267, 273–275). It contains sections on
- multi-level arrays (0:27)
- spreadsheet visualization (2:41)
- assembly for multi-level array access (5:12)
- struct basics (13:40)
- accessing struct fields (18:59)
- size of a struct (22:05)
- assembly for struct access (24:22)
- data alignment (29:41)
- alignment for structs (36:28)
The Panopto viewer has table of contents entries for these sections. Link to the Panopto viewer: https://carleton.hosted.panopto.com/Panopto/Pages/Viewer.aspx?id=d44ba1b1-cdb0-4cb4-b6e6-ac500113c492
2 Multilevel Arrays
- is this multi-dimensional array equivalent to previous
sea?
int sea0[5] = {9, 8, 1, 9, 5}; int sea1[5] = {9, 8, 1, 0, 5}; int sea2[5] = {9, 8, 1, 0, 3}; int sea3[5] = {9, 8, 1, 1, 5}; int *sea_m[4] = {sea0, sea1, sea2, sea3};
- it contains the same 20 ints
- however, each of the four elements of
sea_mis a pointer—none of the elements ofseawere pointers - within each of the rows (
sea0,sea1,sea2,sea3), the 5 ints are allocated as a contiguous block of memory, but each row could be put anywhere - see the difference visually in this spreadsheet
- the C code for
get_sea_m_digitis the same asget_sea_digitfor 2D arrays
int get_sea_m_digit (int index, int digit) { return sea_m[index][digit]; }
- but the assembly for accessing an element will be different
get_sea_digit: leaq (%rdi,%rdi,4), %rax # 5 * index addl %rax, %rsi # 5 * index + digit movl sea(,%rsi,4), %eax # *(sea + 4 * (5 * index + digit)) ret get_sea_m_digit: salq $2, %rsi # rsi = 4*digit addq sea_m(,%rdi,8), %rsi # p = sea_m[index] + 4*digit movl (%rsi), %eax # return *p ret
- accessing an element now requies two memory accesses
- the benefit of this multilevel structure is that the rows can be different lengths
- array access looks the same
sea[3][2]andsea_m[3][2], but underneath- Mem[
sea + 20*index + 4*digit] vs Mem[ Mem[sea_m + 8*index]+ 4*digit]
- Mem[
3 Structures
Two ways to create data types in C: structures (struct) and unions (union) (we won't worry about unions in this course)
// a way of combining different types of data together struct song { char *title; int length_in_seconds; int year_released; }; struct song song1; song1.title = "What is Urinetown?"; song1.length_in_seconds = 213; song1.year_released = 2001;
- variable declarations like any other type:
struct name name1;struct name *pn;struct name name_ar[3];
- common to use
typedefto give the struct type a more concise aliastypedef struct song song_t;makes it so we can usesong_tanywhere we would need to usestruct song
- access fields with
.or->in the case of the pointer (p->fieldis shorthand for(*p).field) - like arrays, struct elements are stored in a contiguous region with a pointer to the first byte
- what will
sizeof(struct song)return? (sizeofis a built-in operator that returns the size, in bytes, of a type)- 16 bytes
- compiler maintains the byte offset information needed to access additional fields (e.g.,
length_in_secondsis 8 bytes from the start of the struct) - can find offset of individual fields using
offsetof(type, member)
- what will
3.1 Examples
struct rec { int a[4]; long i; struct rec *next; };
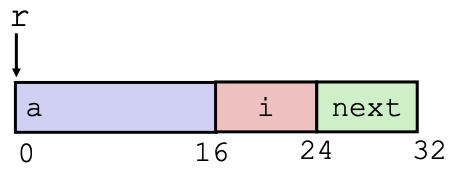
- fields are laid out in memory in same order in which they were declared
- machine code knows nothing about structures, all just byte offsets from a pointer
long get_i(struct rec *r) { return r->i; }
- the compiler knows the field
iis always 16 bytes (the size of the array of 4 intsa) from the start of the struct:
get_i: movq 16(%rdi), %rax ret
long* addr_of_i(struct rec *r) { return &(r->i); }
- note to get the address of the
ifield, we useleato add 16 to the address of the struct
addr_of_i: leaq 16(%rdi), %rax ret
struct rec** addr_of_next(struct rec *r) { return &(r->next); }
- the
nextfield is 24 bytes from the start of the struct (16 fora+ 8 fori)
addr_of_next: leaq 24(%rdi), %rax ret
int get_array_elem (struct rec *r, long index) { return r->a[index]; }
- since
ais located at the start of the struct, accessing an element requires no offset, just normal array indexing
get_array_elem: movl (%rdi, %rsi, 4), %eax ret
3.2 Data Alignment
- suppose a processor always fetches 8 bytes from an address that must be a multiple of 8
- if every
doubleis guaranteed to have a memory address that is a multiple of 8, then it's guaranteed to take only a single operation to read - otherwise, it would take two operations if a
doublewere split across two 8-byte blocks
- if every
- this kind of behavior is typical of hardware interfacing between the processor and memory
- hence, systems institute alignment restrictions to improve memory performance
- Intel recommends data alignment to improve performance
- x86-64 alignment principle: any primitive object of \(K\) bytes must have an address that is a multiple of \(K\)
- this means for structures, the compiler sometimes must insert gaps between fields to maintain alignment (internal fragmentation)
- even if this padding isn't required within a structure, it sometimes must be added to the end to ensure an array of structures is aligned (external fragmentation)
- each structure has alignment requirement \(K_{max}\) = largest alignment of any element
- counts array elements individually as elements
- even if this padding isn't required within a structure, it sometimes must be added to the end to ensure an array of structures is aligned (external fragmentation)