CS 332 w22 — Advanced Scheduling
Table of Contents
1 Scheduling Sequential Tasks on a Multiprocessor
- What would happen if we used MFQ on a multiprocessor?
- Contention for scheduler spinlock
- Cache slowdown due to ready list data structure pinging from one CPU to another
- Limited cache reuse: thread's data from last time it ran is often still in its old cache
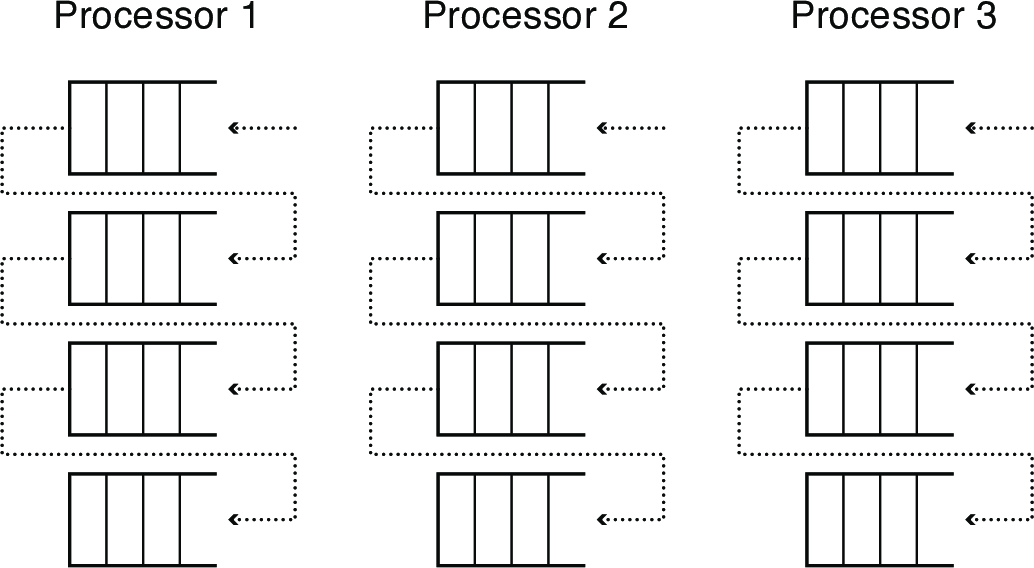
1.1 Solution: Per-Processor Afinity Scheduling
- Each processor has its own scheduler
- Protected by a per-processor spinlock
- Put threads back on the ready list where it had most recently run
- Ex: when I/O completes, or on Condition->signal
- Idle processors can steal work from other processors
- Decreased lock contention and better cache performance
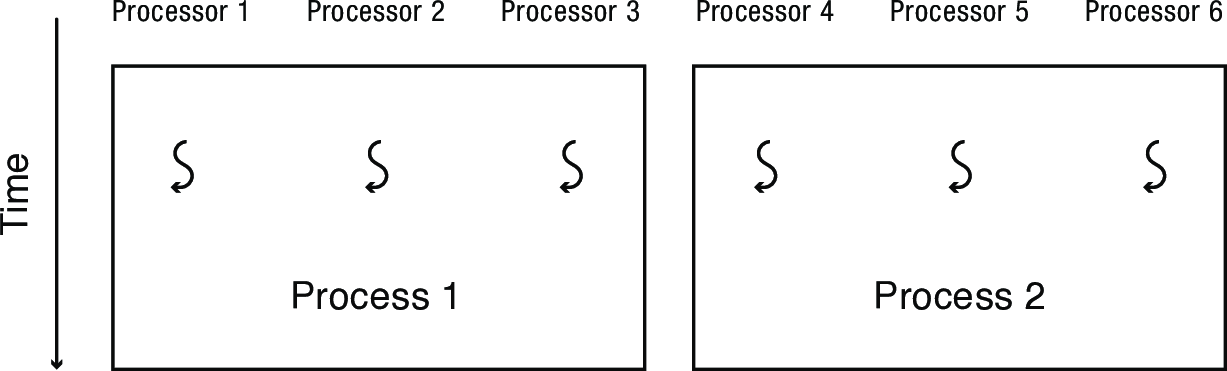
2 Scheduling Parallel Programs
- What happens if one thread gets time-sliced while other threads from the same program are still running?
- Assuming program uses locks and condition variables, it will still be correct
- What about performance?
- The overall program performance may be limited by the slowdown of one thread on one processor
- Multiply this by numerous parallel programs running at the same time, and the system slows to a crawl
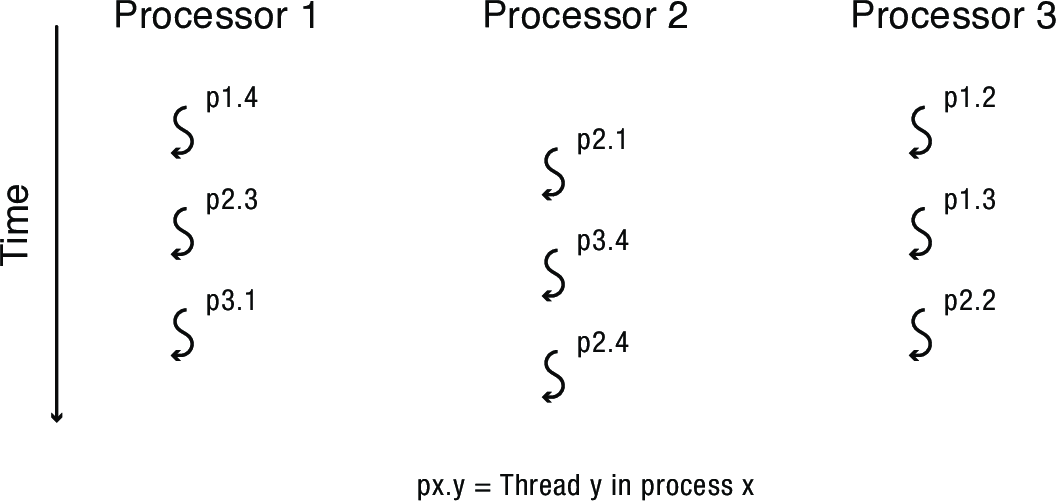
2.1 Oblivious Scheduling
Oblivious Scheduling: each processor time-slices its ready list independently of the other processors, with no coordination to run threads belonging to the same process at the same time
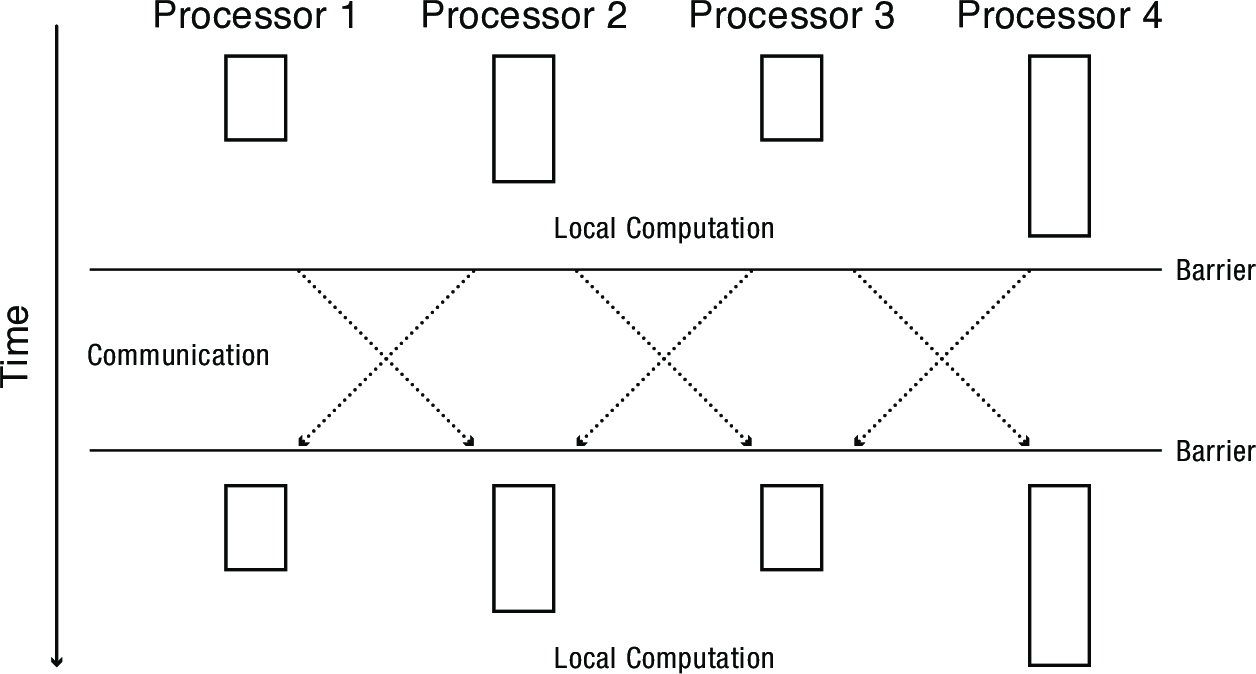
2.1.1 Bulk Synchronous Delay
- Bulk Synchronous Parallelism is a commonly used technique
- Split work up into equal-sized chunks
- Loop at each processor:
- Compute on local data (in parallel)
- Barrier (synchronize)
- Send (selected) data to other processors (in parallel)
- Barrier (synchronize)
- Examples:
- MapReduce
- Fluid flow over a wing
- Most parallel algorithms can be recast in BSP
- Sacrificing a small constant factor in performance
- However, the slowest processor will become a bottleneck
2.1.2 Producer-Consumer Delay
We've also discussed producer-consumer patterns—the results of one thread are fed to the next thread.

Preempting a thread in the middle of the chain can stall all of the processors in the chain.
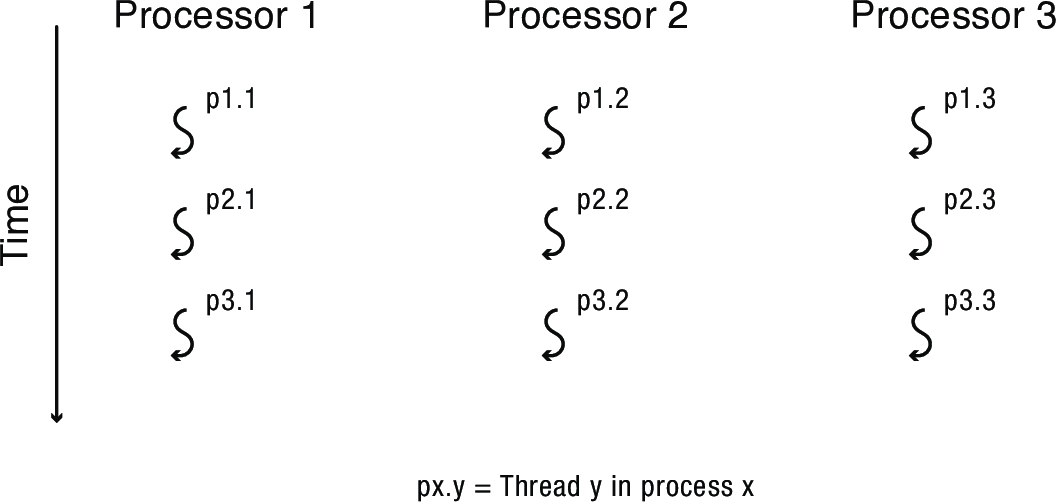
2.2 Solution: Gang Scheduling
- Designate set of threads that must run together
- e.g., all the threads from one process
- Modern OSes have mechanisms for this
- Works well when there's one primary application that should take priority
- A single-purpose web server
- A database needing precise control over thread assignment
- Suffers when trying to share reserved sets of processors across multiple applications
- Especially when not all applications can take advantage of using all the processors at once
- Implication: usually more efficient to run two parallel programs each with half the processors than to time slice them onto all the processors
2.3 Solution: Space Sharing
- Assign processors to specific programs
- Use scheduler activations (calls from kernel to user program) to inform program of available processors
- The kernel sends an asynchronous signal to a process to inform it when a processor is added to its allocation or taken away
3 Energy-Aware Scheduling
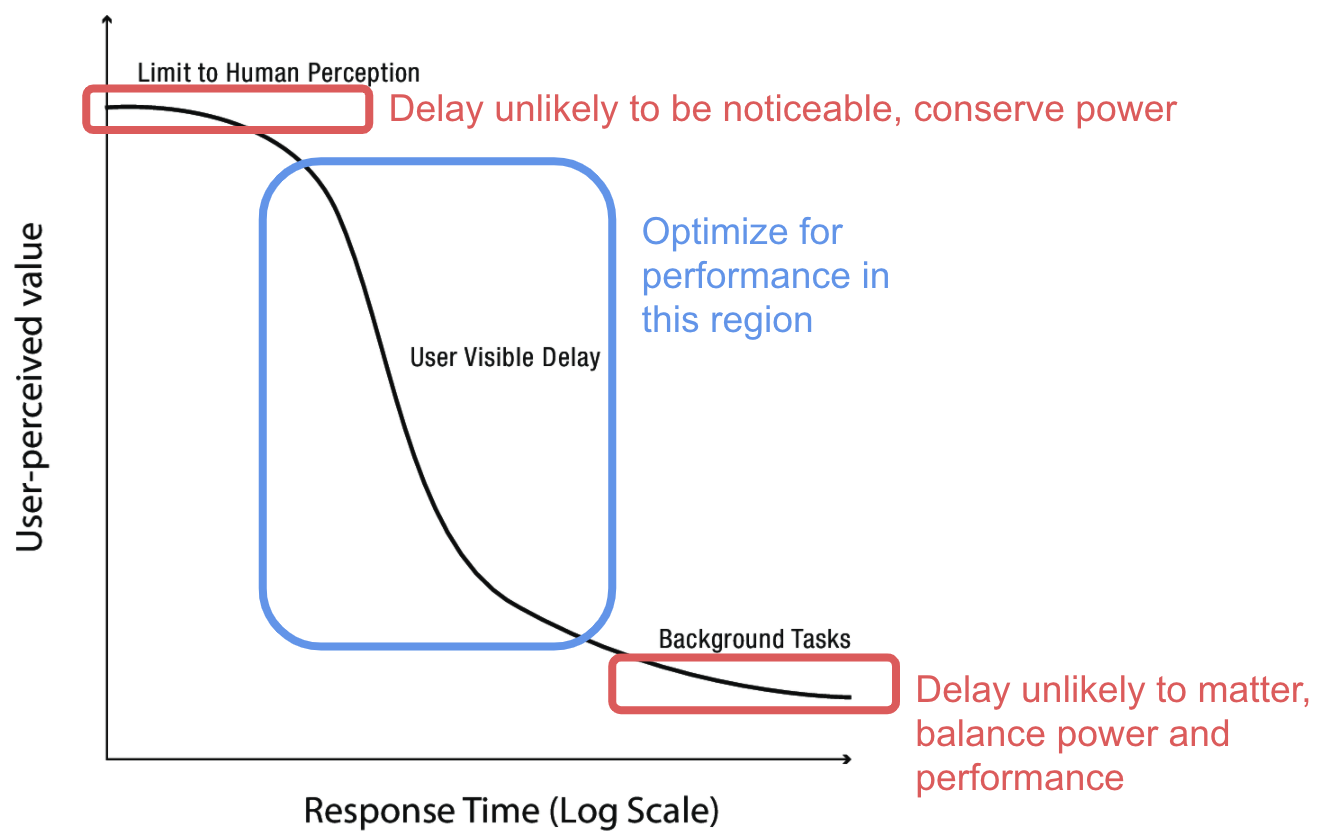
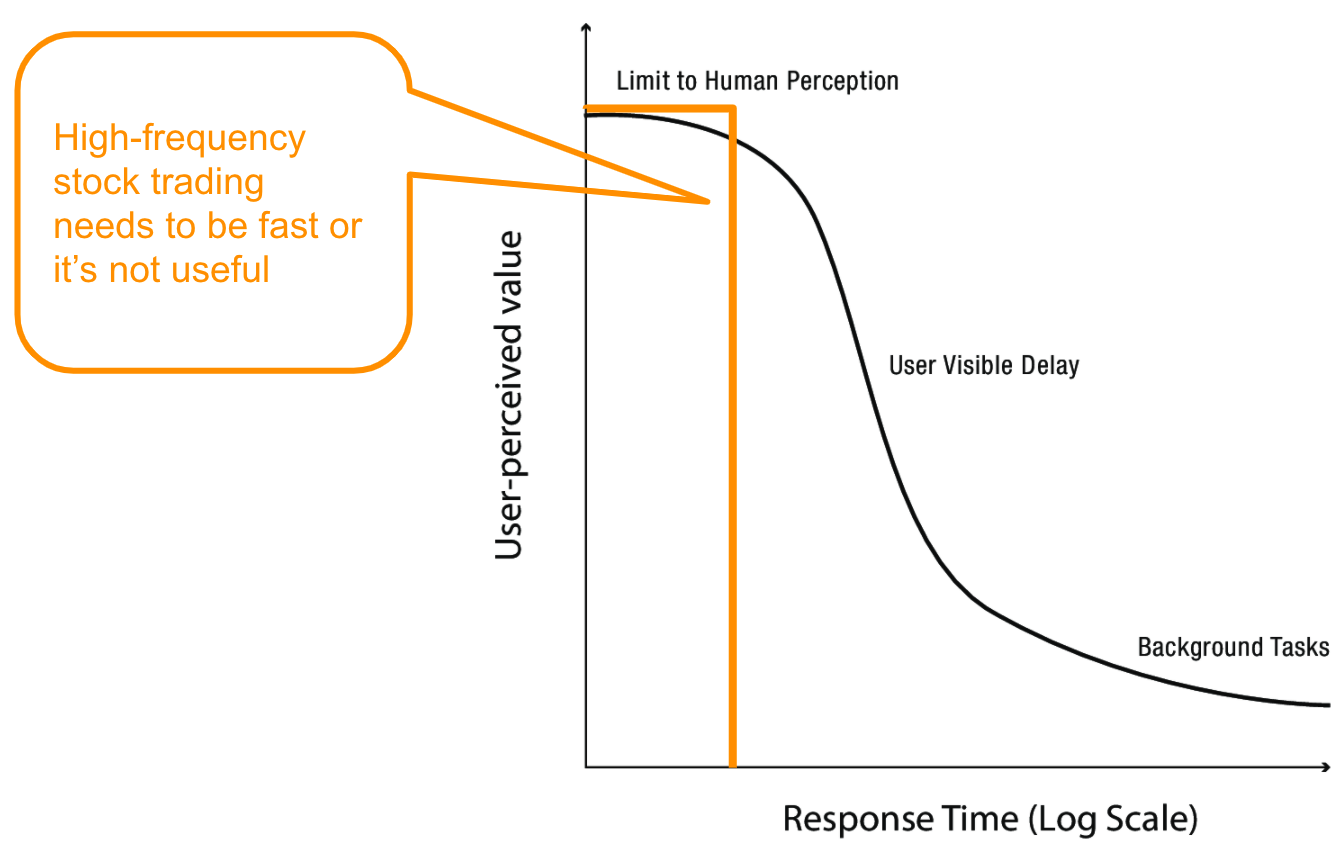
- When battery life becomes a critical resource (modern phones, laptops, etc.), no longer assume processor works at a fixed speed with fixed energy needs
- Put performance-energy tradeoff under OS control by including two processors: fast, high-power and slow, low-power
- Scheduler can take power into account when deciding which to use for a given task
- Turn off/leave idle cores and I/O devices we don't need at the moment
- Ex. wifi is very energy intensive, many embedded systems only activate it at specific times or default to a (low-power) passive listening mode
4 Linux Completely Fair Scheduler (CFS)
- CFS is not based on queues, instead it implements fair-share scheduling
- One of several Linux scheduling algorithms, BSD's ULE scheduler does use queues
- Each task t has a weight, \(w(t)\)
- Each runnable task \(t\) should acquire CPU time at rate \(\frac{w(t)}{\sum w(j)}\) for all \(j\)
- Keep track of accumulated weighted runtime vs. fair share amount
- Over a fixed interval, try to run each runnable task at least once
- Set time slice according to its fair share of interval, based on weights
- The next task to run is the one whose accumulated runtime is most behind its fair share
- Since we aren't just taking the first item in a queue like MFQ, need an efficient data structure for finding the next task to run
- Red-black tree, a balanced binary tree