CS 332 w22 — File System Implementation
Table of Contents
1 Introduction
Having covered the general file system abstraction and played around with the file system API, now it's time to take a look at what's going on underneath. We know that persistent storage disks are block devices, meaning we read from and write to them in fixed-size blocks. Meanwhile, the operating system lets users jump to arbitrary points within a file and start reading and writing away. Clearly there must be some machinery to bridge the gap between device interface and system call. This material should emphasize that careful data structure design plays a significant part in building an operating system.
2 Reading: File System Implementation
Read this part of the OSPP chapter on file system implementation. Don't worry about the details of directory internals on p. 6, the takeaway is the choice of data structures is a big part of file system design. Important terms to make sure you understand after you're finished:
- inode
- data block
- direct pointer
- indirect pointer
3 Overview
- Primary Roles of the OS for the file system
- Hide hardware specific interface
- Allocate disk blocks
- Check permissions
- Understand directory file structure
- Maintain metadata
- Performance
- Flexibility
- The concept of a file system is simple
- the implementation of the abstraction for secondary storage
- abstraction = files
- logical organization of files into directories
- the directory hierarchy
- sharing of data among processes, people and machines
- access control, consistency, …
- the implementation of the abstraction for secondary storage
4 File Access
- Some file systems provide different access methods that specify ways the application will access data
- sequential access
- read bytes in order
- direct access
- random access given a block/byte number
- record access
- file is array of fixed- or variable-sized records
- indexed access
- file system contains an index to a particular field of each record in a file
- apps can find a file based on value in that record (similar to a database)
- sequential access
- Why do we care about distinguishing sequential from direct access?
- what might the file system do differently in these cases?1
5 What is a Directory?
- A directory is typically just a file that happens to contain special metadata
- directory = list of (name of file, file attributes)
- attributes include such things as:
- size, protection, location on disk, creation time, access time, …
- the directory list is usually unordered (effectively random)
- when you type
ls, thelscommand sorts the results for you
- when you type
6 Path Translation
- Let's say you want to open "/one/two/three"
fd = open("/one/two/three", O_RDWR);
- What goes on inside the file system?
- open directory "/" (well known, can always find)
- search the directory for "one", get location of "one"
- open directory "one", search for "two", get location of "two"
- open directory "two", search for "three", get location of "three"
- open file "three"
- (of course, permissions are checked at each step)
- File system spends lots of time walking down directory paths
- this is why open is separate from read/write
- to preserve the location, etc. of a file between individual reads and writes (session state)
- OS will cache prefix lookups to enhance performance
- /a/b, /a/bb, /a/bbb all share the "/a" prefix
- this is why open is separate from read/write
7 File protection
- File system must implement some kind of protection system
- to control who can access a file (user)
- to control how they can access it (e.g., read, write, or exec)
- More generally:
- generalize files to objects (the "what")
- generalize users to principals (the "who", user or program)
- generalize read/write to actions (the "how", or operations)
- A protection system dictates whether a given action performed by a given principal on a given object should be allowed
- e.g., you can read or write your files, but others cannot
- e.g., your can read /etc/motd but you cannot write to it
7.1 Models for Representing Protection
- Two different ways of representing protection:
- access control lists (ACLs)
- for each object, keep list of principals and principals' allowed actions
- capabilities
- for each principal, keep list of objects and principal's allowed actions
- Both can be represented with the following matrix:
- access control lists (ACLs)
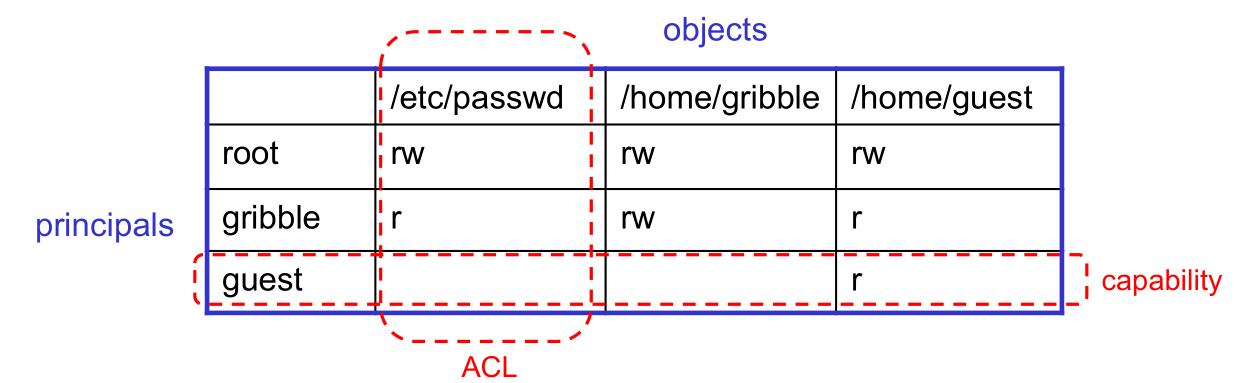
7.2 ACLs vs. Capabilities
- Capabilities are easy to transfer
- they are like keys: can hand them off
- they make sharing easy
- ACLs are easier to manage
- object-centric, easy to grant and revoke
- to revoke capability, need to keep track of principals that have it
- hard to do, given that principals can hand off capabilities
- object-centric, easy to grant and revoke
- ACLs grow large when object is heavily shared
- can simplify by using "groups"
- put users in groups, put groups in ACLs
- additional benefit
- change group membership, affects ALL objects that have this group in its ACL
- can simplify by using "groups"
8 FAT file system
- Created in the 1970s for MS-DOS and early versions of Windows
- Various enhancements over the years
- FAT-32: volumns of up to 228 blocks, files up to 232 - 1 bytes
Named for the file allocation table
- array of 32-bit entries (hence the 32 in FAT-32)
- each file is a linked list of FAT entries, one entry per block
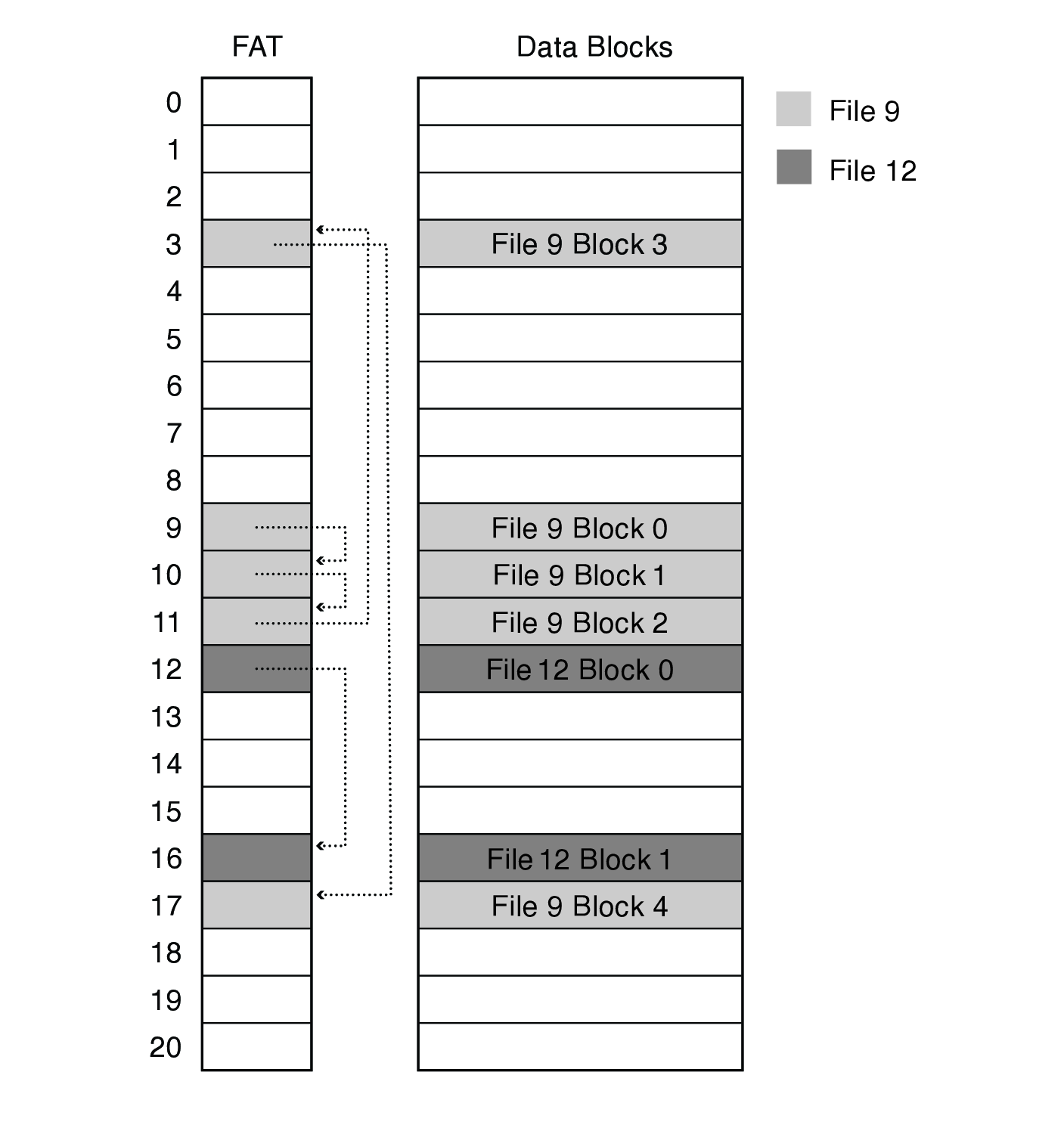
- file's number is the index of its first entry
- Allocation is typically simple, something like next fit
- May scatter a file's blocks across volume, requiring defragmentation
- Read files and rewrite them to new, more consolidated location
- May scatter a file's blocks across volume, requiring defragmentation
- FAT continues to be used for its simplicity and portability
- USB flash storage, camera memory cards
- Downsides
- poor locality
- poor random access
- limited metadata and access control
- no hard links
- limitations on volumn and file size
- doesn't support modern reliability techniques
9 Unix Fast File System (FFS)
- Dennis Ritchie and Ken Thompson, Bell Labs, 1969
"UNIX rose from the ashes of a multi-organizational effort in the early 1960s to develop a dependable timesharing operating system" – Multics
- Designed for a "workgroup" sharing a single system
- Did its job exceedingly well
- Although it has been stretched in many directions and made ugly in the process
- A wonderful study in engineering tradeoffs
(Old) Unix disks are divided into five parts:
- Boot block
- can boot the system by loading from this block
- Superblock
- specifies boundaries of next 3 areas, and contains head of freelists of inodes and file blocks
- inode area
- contains descriptors (inodes) for each file on the disk; all inodes are the same size; head of freelist is in the superblock
- File contents area
- fixed-size blocks; head of freelist is in the superblock
- Swap area
- holds processes that have been swapped out of memory
9.1 inodes
A per-file on-disk data structure that contains the file's metadata
9.1.1 inode format
- User number
- Group number
- Protection bits
- Times (file last read, file last written, inode last written)
- File code: specifies if the i-node represents a directory, an ordinary user file, or a "special file" (typically an I/O device)
- Size: length of file in bytes
- Block list: locates contents of file (in the file contents area)
- Link count: number of directories referencing this inode
9.1.2 The flat (inode) file system
- Each file is known by a number, which is the number of the i-node
- seriously — 1, 2, 3, etc.!
- why is it called "flat"?2
- Files are created empty, and grow when extended through writes
9.1.3 The tree (directory, hierarchical) file system
- A directory is a flat file of fixed-size entries
- Each entry consists of an i-node number and a file
| inode number | file name |
|---|---|
| 152 | . |
| 18 | .. |
| 216 | my_file |
| 4 | another_file |
| 93 | louie_louie |
| 144 | a_directory |
- It's as simple as that!
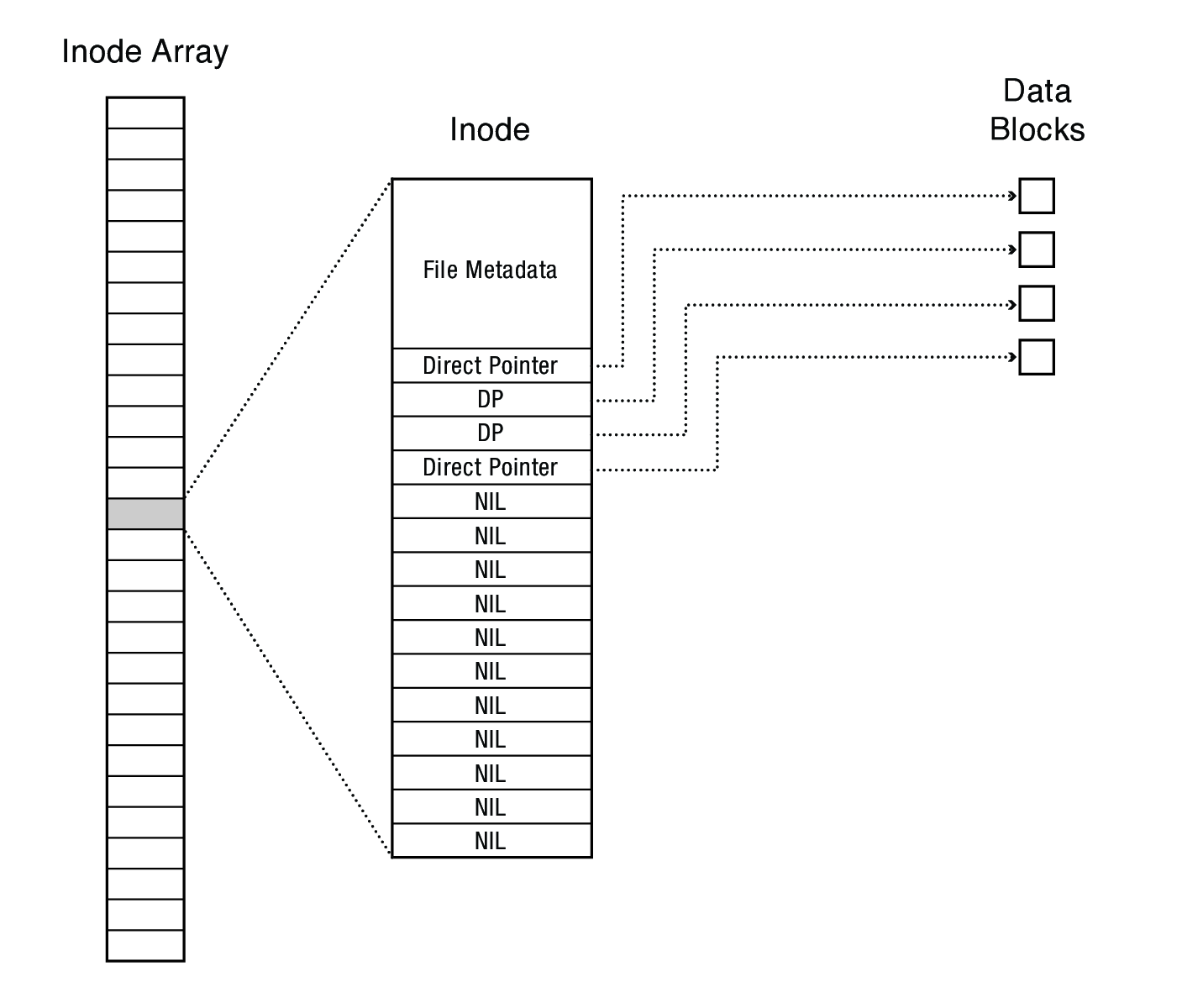
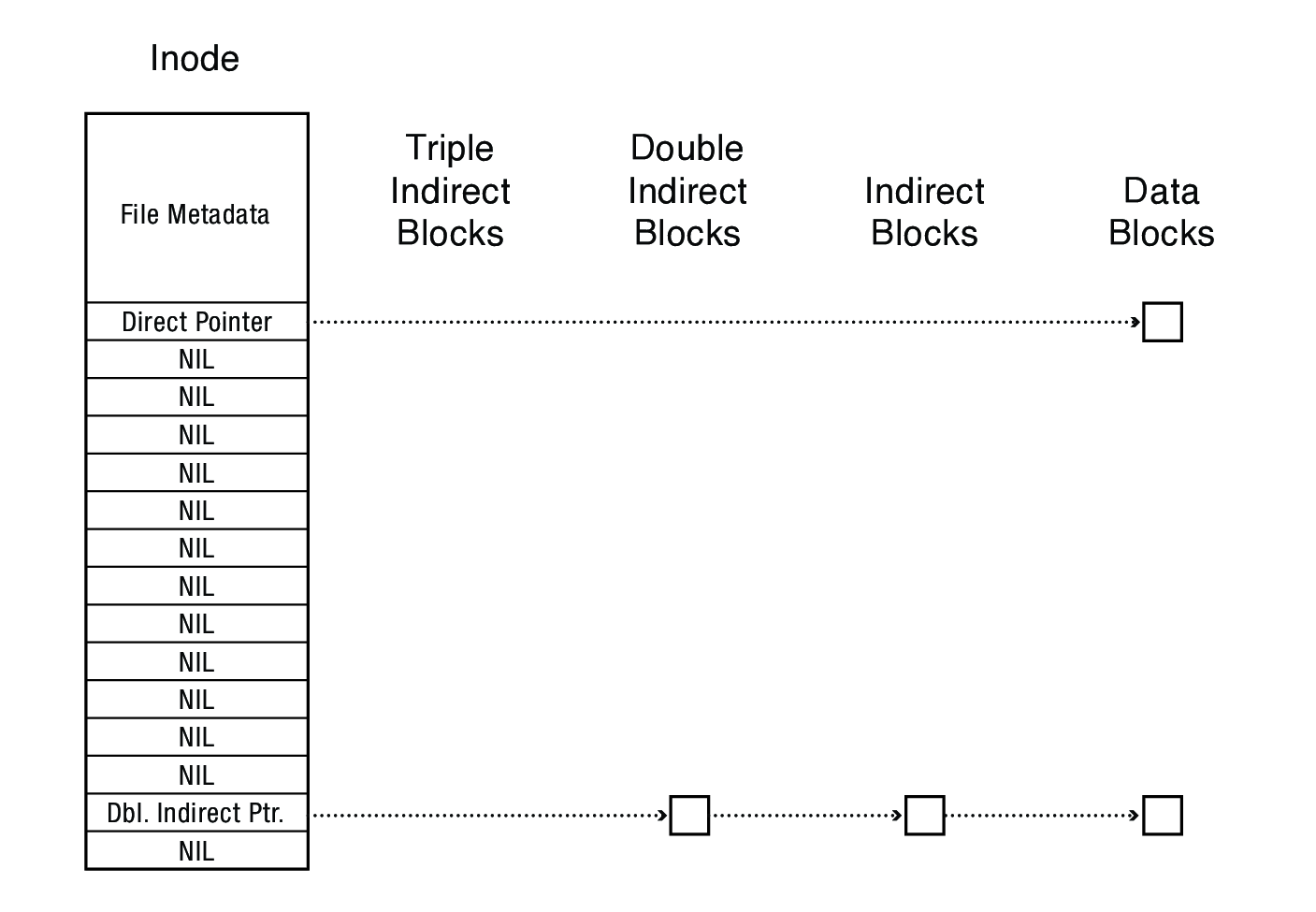
9.1.4 The "block list" portion of the inode (Unix Version 7)
- Points to blocks in the file contents area
- Must be able to represent very small and very large files.
- Each inode contains 13 block pointers
- first 10 are "direct pointers" (pointers to 512B blocks of file data)
- then, single, double, and triple indirect pointers
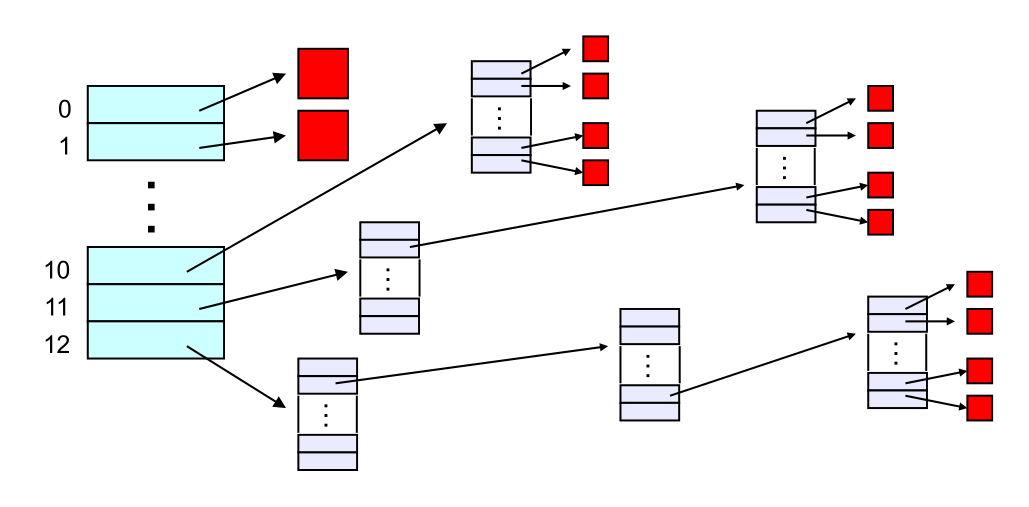
- Alternatively, 15 block pointers of which 12 are direct
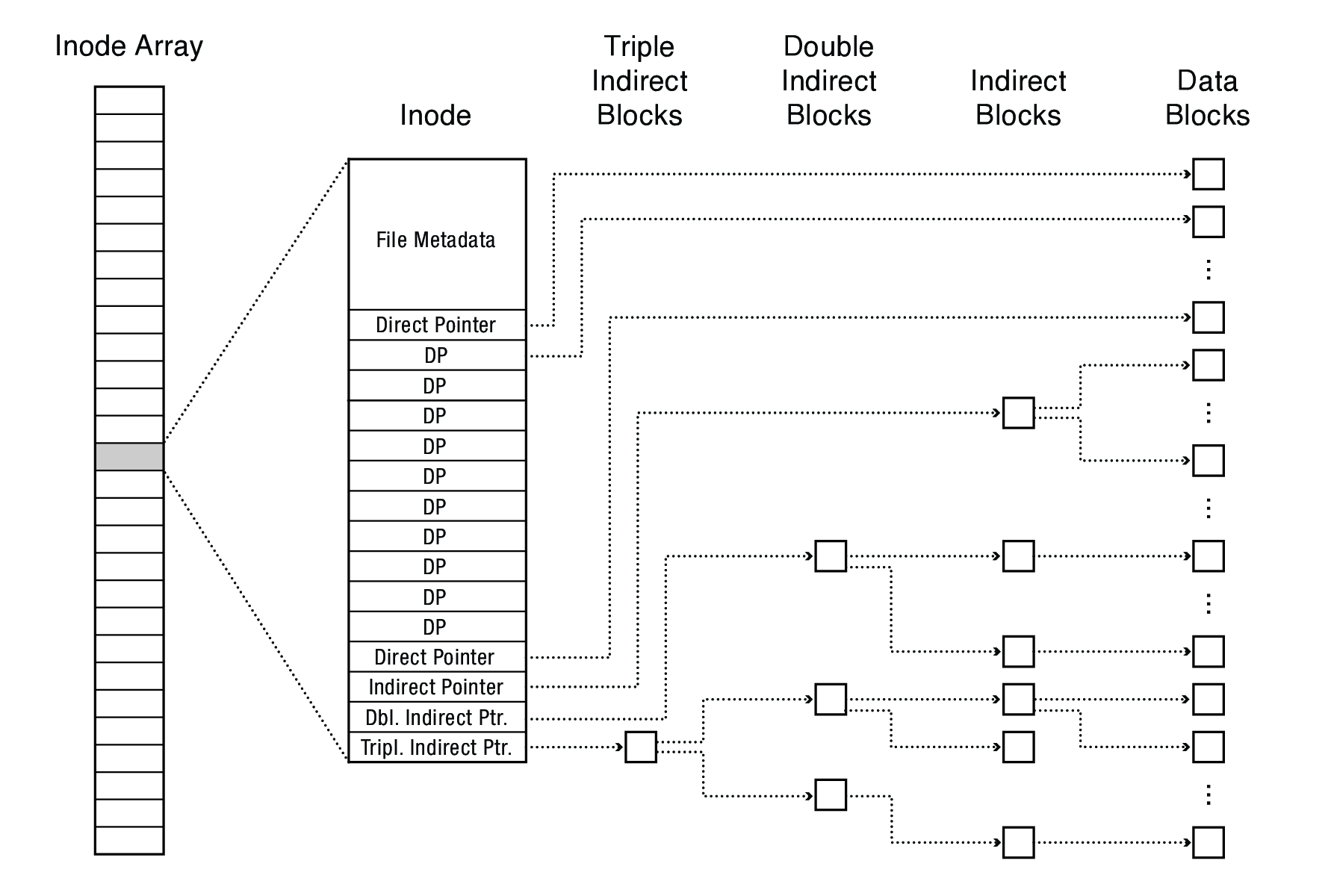
This means…
- The block list only occupies 13 x 4B in the inode
- Can get to 10 x 512B = a 5120B file directly
- (10 direct pointers, blocks in the file contents area are 512B)
- Can get to 128 x 512B = an additional 65KB with a single indirect reference
- (the 11th pointer in the i-node gets you to a 512B block in the file contents area that contains 128 4B pointers to blocks holding file data)
- Can get to 128 x 128 x 512B = an additional 8MB with a double indirect reference
- (the 12th pointer in the i-node gets you to a 512B block in the file contents area that contains 128 4B pointers to 512B blocks in the file contents area that contain 128 4B pointers to 512B blocks holding file data)
- Can get to 128 x 128 x 128 x 512B = an additional 1GB with a triple indirect reference
- (the 13th pointer in the i-node gets you to a 512B block in the file contents area that contains 128 4B pointers to 512B blocks in the file contents area that contain 128 4B pointers to 512B blocks in the file contents area that contain 128 4B pointers to 512B blocks holding file data)
- Maximum file size is 1GB + a smidge
- A later version of Bell Labs Unix utilized 12 direct pointers rather than 10
- Berkeley Unix went to 1KB block sizes
- What's the effect on the maximum file size?
- 256x256x256x1K = 17 GB + a smidge
- What's the price?3
- What's the effect on the maximum file size?
- Subsequently went to 4KB blocks
- 1Kx1Kx1Kx4K = 4TB + a smidge
- High degree/fan out is useful to avoid lots of jumping around to different nodes
- The asymmetric structure supports both small and large files efficiently
A small file will be accessed via a small-depth tree using just direct pointers
- Max file size for hypothetical BigFFS with 12 direct, 1 indirect, 1 double indirect, 1 triple indirect, and 1 quadrupal indirect pointers4
- 4KB blocks and 8-byte pointers
Sparse files (ranges of empty space between file data) are also supported
- A database could store tables at the start of its file, indices at 1 GB into the file, log at 2GB, and additional metadata at 4 GB
- Size of the file would be 4 GB, but space consumed by the file might be much smaller
- A database could store tables at the start of its file, indices at 1 GB into the file, log at 2GB, and additional metadata at 4 GB
9.2 Putting it all together
The file system is just a huge data structure
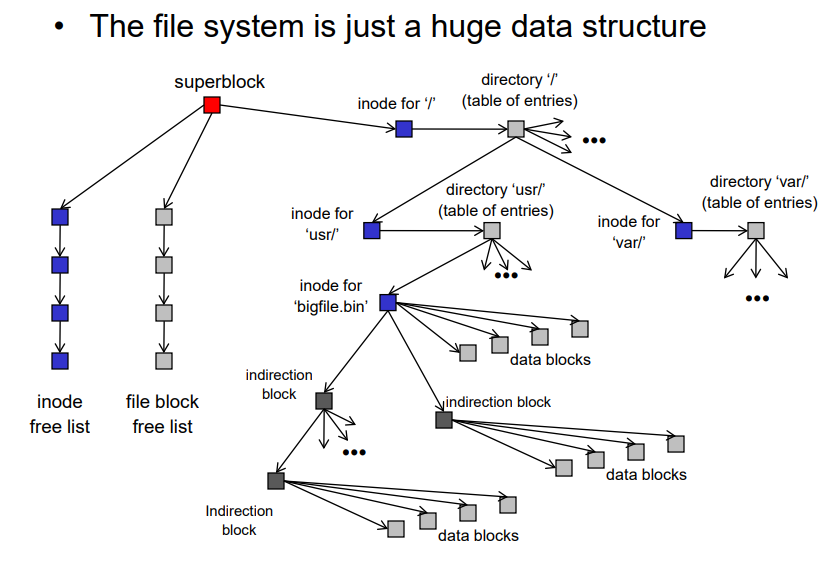
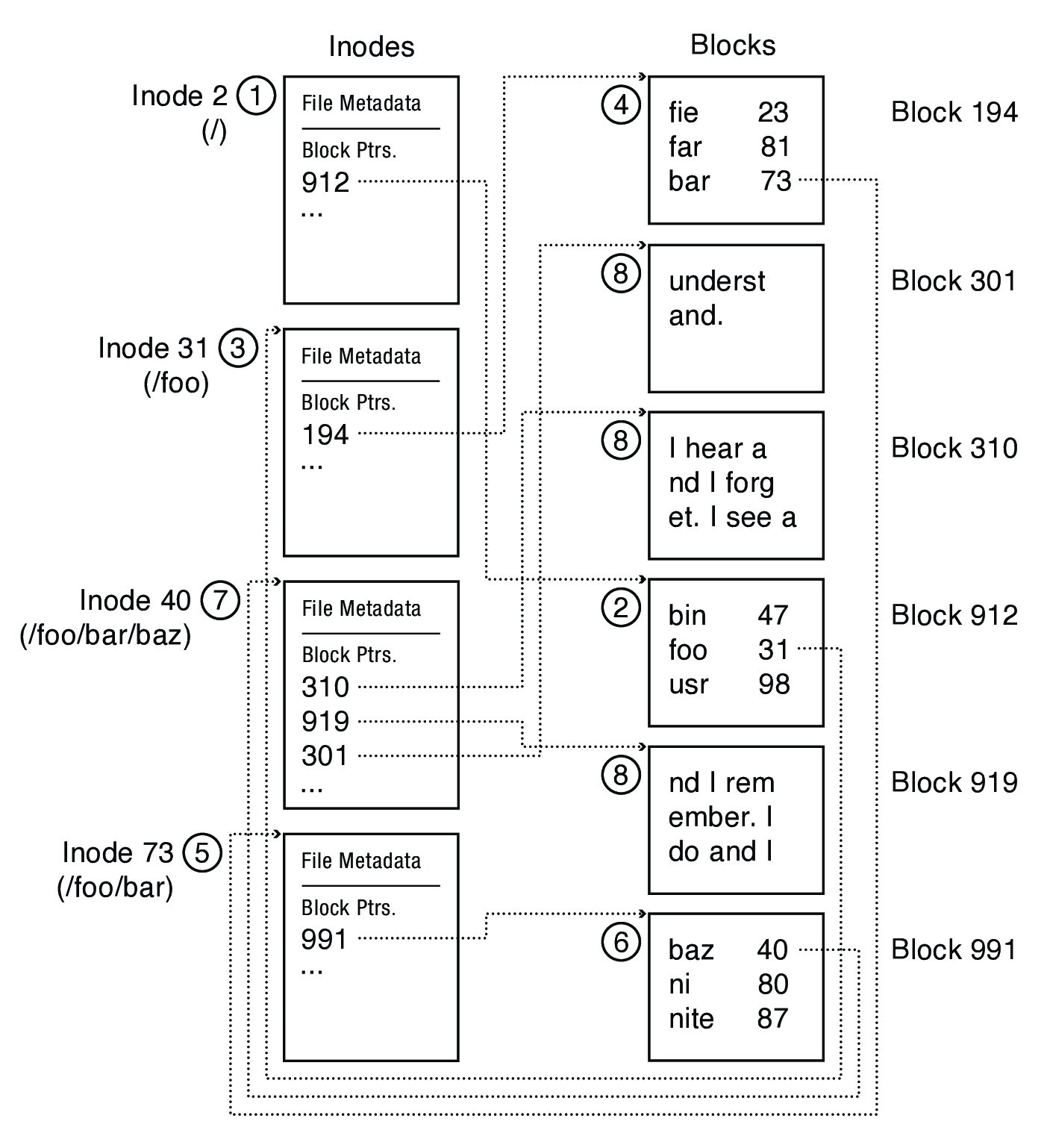
Steps to read /foo/bar/baz
10 Microsoft New Technology File System (NTFS)
- Released in 1993, big improvement over FAT
- Key difference from FFS: track variable-sized extents rather than fixed-size blocks
- An extent is a contiguous set of blocks
- The modern Linux file system ext4 uses this approach
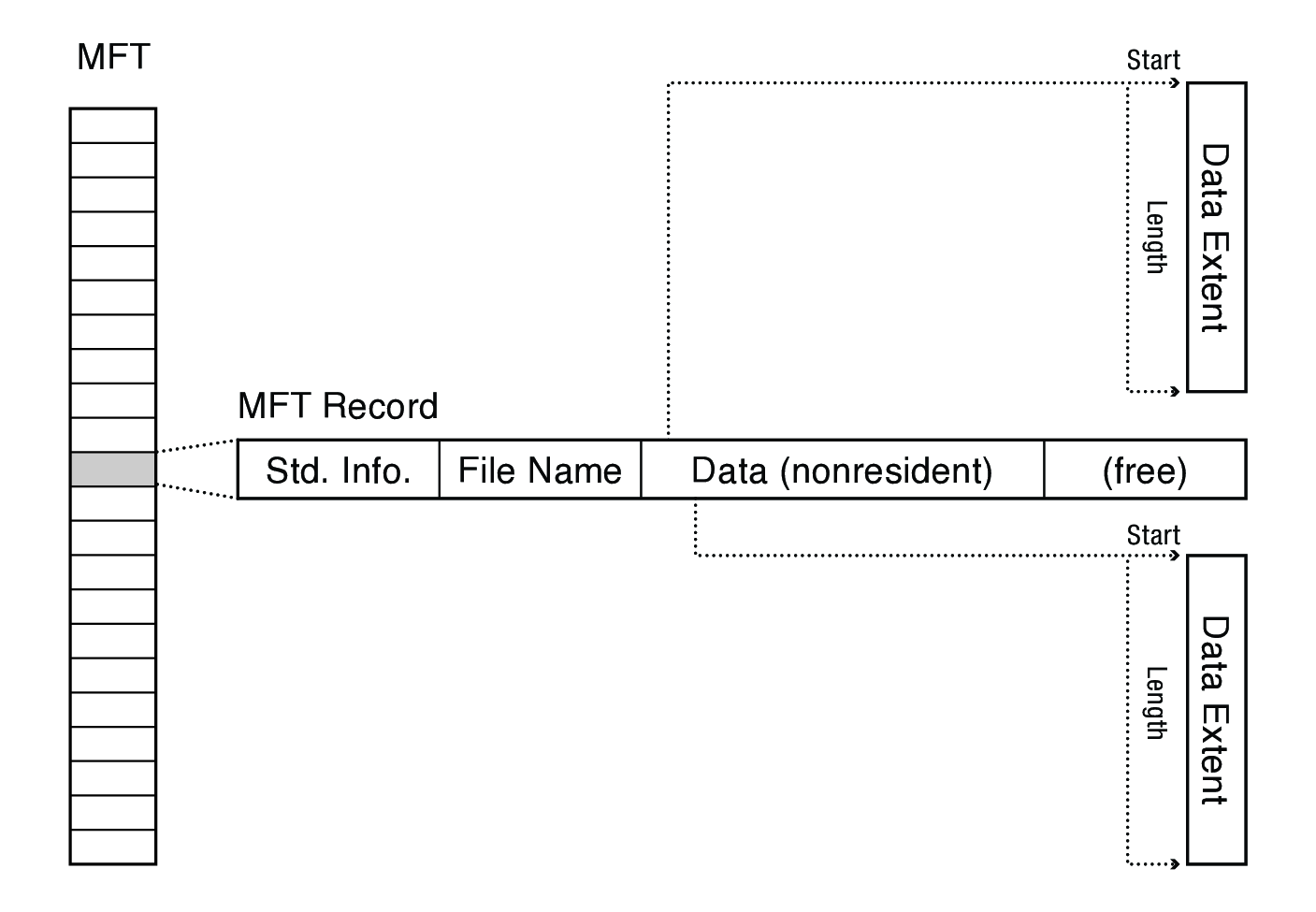
- A master file table (MFT) stores an array of 1 KB records
- Each MFT record has information about a file and variable sized attribute records
- The attribute records store both file data and metadata
- An attribute can be resident (stored directly within the MFT record) or nonresident (MFT record contains pointers to the start and end of the extent storing the data)
A basic file with two data extents:
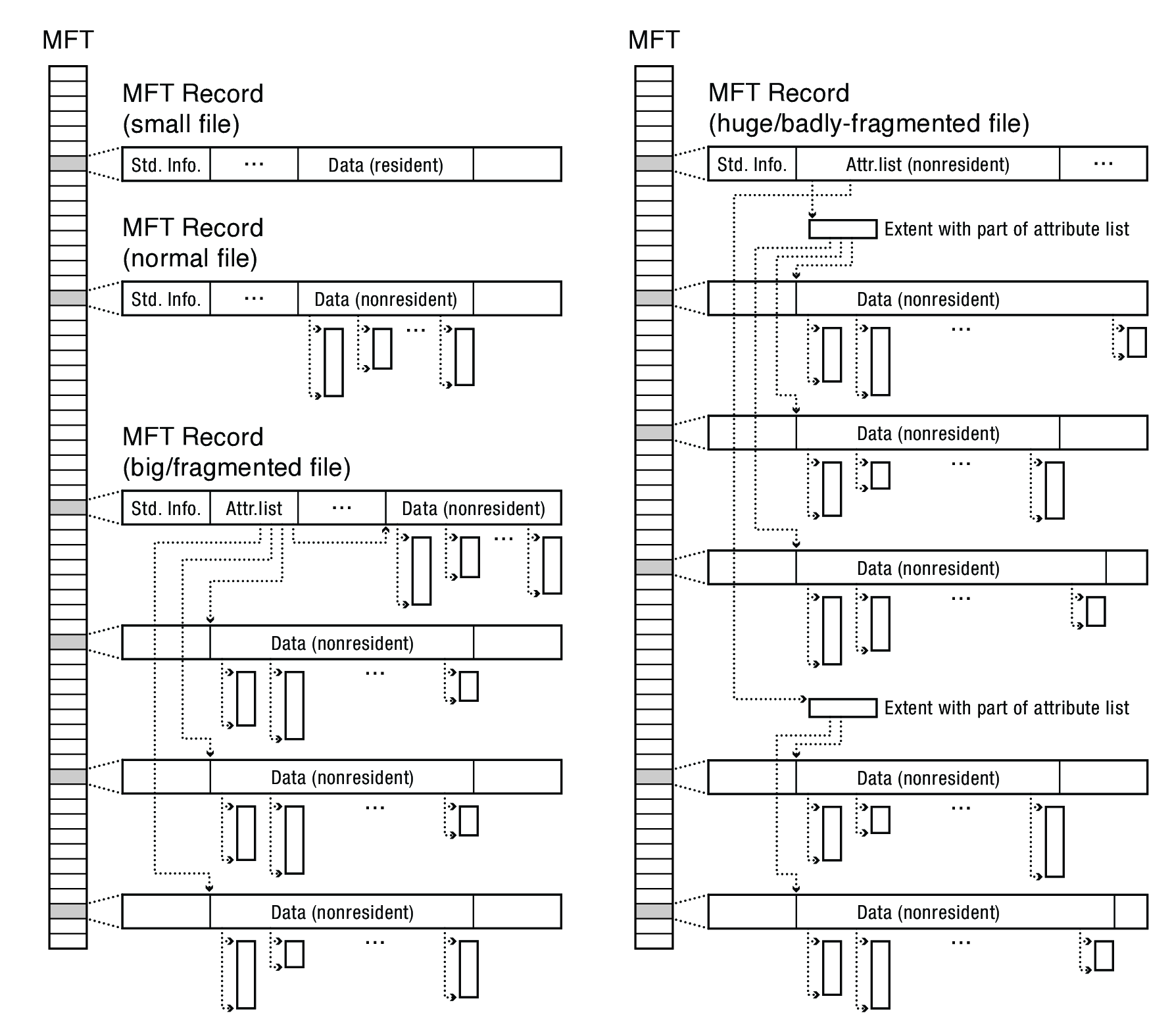
A small file's data can be resident:

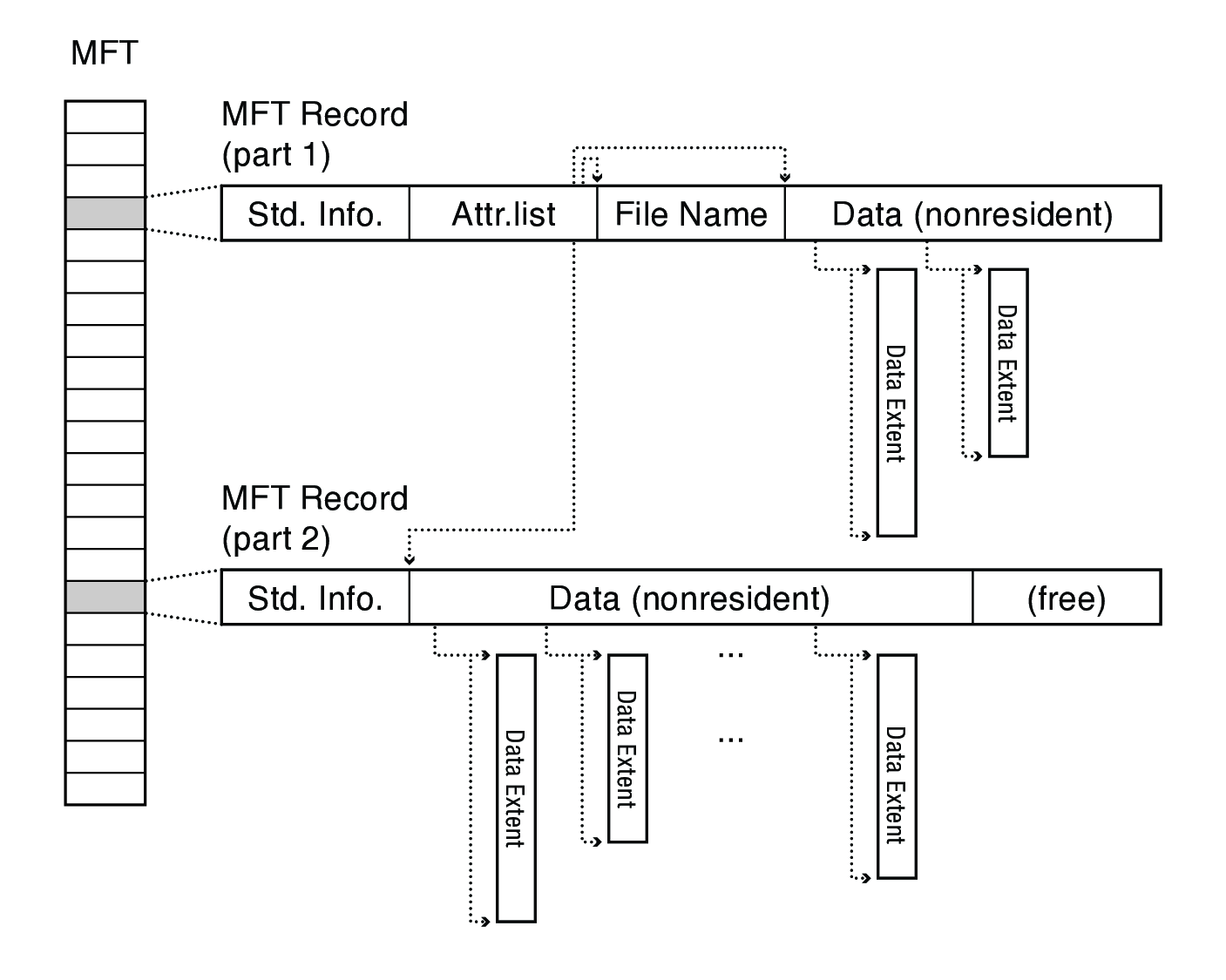
A large file may span multiple MFT records, in which case the first record stores an attribute list that indicates where to find each attribute
11 Copy-on-write File Systems
- ZFS is a popular open-source example (formerly the Zettabyte File System)
- See the OSTEP chapter on Log-Structured File Systems (LFS) for another example
- Goal is to transform random writes into sequential writes
- Instead of updating various parts of the on-disk data structure, requiring several non-sequential writes
- Write new versions to a sequential chunk of free space
- Because small writes are expensive and large memory caches will greatly reduce the number of reads from disk, this can be a big performance boost for write-heavy workloads
Footnotes:
Caching and prefetching would certainly differ between sequential and direct access. The OS can make much stronger assumptions about the pattern of access in the sequential setting.
There is no hierarchical structure, just a mapping of files to inodes.
Disks with many small files will waste space, since each file must occupy at least one block.
- 12 direct * 4 KB = 48 KB
- 1 indirect = 4 KB / 8B per pointer = 512 pointers/block, so 4 KB * 512 = 2 MB
- Similarly, double indirect = 1 GB, triple = 512 GB, and quadrupal = 512 * 512 * 512 * 512 * 4 KB = 256 TB
- So a bit more than 256.5 TB in total