CS 332 w22 — File System Reliability
Table of Contents
1 Reading: Crash Consistency: FSCK and Journaling
Read OSTEP Chapter 42 for a nice walkthrough of two approaches to recovering from a mid-file-system-operation crash.
2 The Problem
- you're writing the file system
- then the power fails
- you reboot
- is your file system still useable?
- crash during multi-step operation
- may leave FS in an inconsistent state
- after reboot:
- bad: crash again due to corrupt FS
- worse: no crash, but reads/writes incorrect data
2.1 Example
This tiny example includes an inode bitmap (with just 8 bits, one per inode), a data bitmap (also 8 bits, one per data block), inodes (8 total, numbered 0 to 7, and spread across four blocks), and data blocks (8 total, numbered 0 to 7).
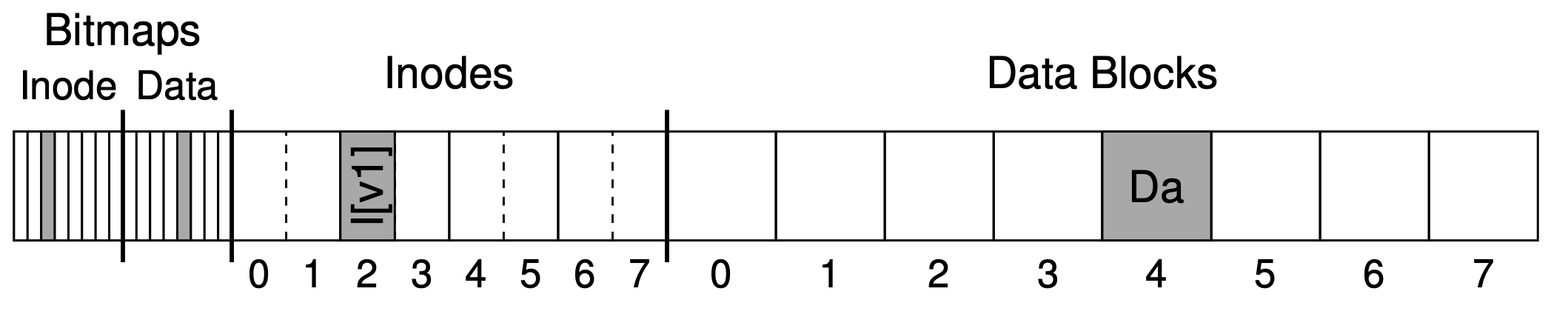
Here's what's inside our inode:
owner : awb permissions : read-write size : 1 pointer : 4 pointer : null pointer : null pointer : null
What needs to be updated to append a block's worth of data to the existing file?1

2.1.1 Crash Scenarios
- Just data block is written
- Just inode is written
- Just bitmap is written
- inode and data block are written, but not bitmap
- inode and bitmap are written, but not data
- data block and bitmap are written, but not inode
3 Solution #1: The File System Checker
- Unix tool
fsck - On reboot, check every part of the file system for consistency
- Before file system is mounted (ensures no other file system operations are taking place)
- Perform repairs as needed
- Problem
- Very slow to check the entire disk!
4 Solution #2: Write-Ahead Logging (a.k.a Journaling)
4.1 Overview
- what can we hope for?
- after rebooting and running recovery code
- FS internal consistency maintained e.g., no block is both in free list and in a file
- all but last few operations preserved on disk e.g., data I wrote yesterday are preserved but perhaps not data I was writing at time of crash so user might have to check last few operations
- no order anomalies echo 99 > result ; echo done > status
- correctness and performance often conflict
- disk writes are slow!
- safety => write to disk ASAP
- speed => don't write the disk (batch, write-back cache, sort by track, &c)
- crash recovery is a recurring problem
- arises in all storage systems, e.g. databases
- a lot of work has gone into solutions over the years
- many clever performance/correctness tradeoffs
4.2 Implementation
- most popular solution: logging (== journaling)
- goal: atomic system calls w.r.t. crashes
- goal: fast recovery (no hour-long fsck)
- the basic idea behind logging
- you want atomicity: all of a system call's writes, or none
- let's call an atomic operation a "transaction"
- record all writes the sys call will do in the log on disk (log)
- then record "done" on disk (commit)
- then do the FS disk writes (install)
- on crash+recovery:
- if "done" in log, replay all writes in log
- if no "done", ignore log
- this is a WRITE-AHEAD LOG
- After install, clean the log so the blocks for the installed entries can be reused
- you want atomicity: all of a system call's writes, or none
- write-ahead log rule
- install none of a transaction's writes to disk until all writes are in the log on disk, and the logged writes are marked committed.
- why the rule?
- once we've installed one write to the on-disk FS, we have to do all of the transaction's other writes — so the transaction is atomic
- we have to be prepared for a crash after the first installation write, so the other writes must be still available after the crash — in the log.
4.3 Challenges
- challenge: prevent write-back from cache
- a system call can safely update a cached block, but the block cannot be written to the FS until the transaction commits
- tricky because e.g. cache may run out of space, and be tempted to evict some entries in order to read and cache other data.
- consider create example:
- write dirty inode to log
- write dir block to log
- evict dirty inode
- commit
- solutions:
- ensure buffer cache is big enough
- pin dirty blocks in buffer cache
- after commit, unpin block
- challenge: each block gets written to disk twice (once for log, once for install)
- this is more overhead than we'd like
- what if we only logged metadata?
- so only the updates to e.g., the bitmap and the inode go in the log
- when would we write the data?2