CS 332 w22 — Meltdown
Table of Contents
Adapted from Robert Morris. 6.S081: https://pdos.csail.mit.edu/6.S081/2020/schedule.html
1 Why Study Meltdown?
- Security is a critical O/S goal
- The kernel's main strategy: isolation
- User/supervisor mode, page tables, defensive system calls, etc.
- It's worth looking at examples of how things go wrong
2 Meltdown
- a surprising and disturbing attack on user/kernel isolation
- one of a number of recent "micro-architectural" attacks
- exploiting hidden implementation details of CPUs
- fixable, but people fear an open-ended supply of related surprises
Here's the core of the attack (in a C-like assembly psuedocode, where
r1,r2, etc. represent registers):char buf[8192] r1 = <a kernel virtual address> r2 = *r1 r2 = r2 & 1 r2 = r2 * 4096 r3 = buf[r2]
- This will be executed from user code.
- Will
r2end up holding data from the kernel?
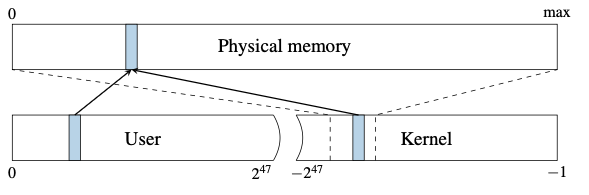
2.1 Kernel Memory Mapped via User Page Table
- Meltdown attack assumes the kernel is mapped in user page table, with
PTE_Uclear (i.e., would cause a fault if user tried to access that virtual address).- this was near universal until these attacks were discovered.
- kernel in upper half (high bit set), user in lower half (starting at zero).
- mapping both user and kernel makes system calls significantly faster.
- no switched page tables
- the point:
*r1is meaningful, even if forbidden.
2.2 Speculative Execution
- So how can the above code possibly be useful to an attacker?
- The answer has to do with a bunch of mostly-hidden CPU implementation details.
- Speculative execution, and caches.
- First, speculative execution.
- This is not yet about security.
- Imagine this ordinary code.
This is C-like code;
r0etc. are registers, and*r0is a memory reference.r0 = <something> r1 = valid // r1 is a register; valid is a value stored in RAM if(r1 == 1){ r2 = *r0 r3 = r2 + 1 } else { r3 = 0 }
- The
r1 = validmay have to load from RAM, taking 100s of cycles. - The
if(r1 == 1)needs that data. - It would be too bad if the CPU had to pause until the RAM fetch completed.
- Instead, the CPU predicts which way the branch is likely to go, and continues executing.
- This is called speculation.
- So the CPU may execute the
r2 = *r0and then ther3 = r2 + 1.
- What if the CPU mis-predicts a branch, e.g. r1 == 0?
- It flushes the results of the incorrect speculation.
- Specifically, the CPU reverts the content of
r2andr3. - And re-starts execution, in the
elsebranch.
- Speculative execution is a huge win for performance, since it lets the CPU obtain a lot of parallelism — overlap of slower operations (divide, memory load, etc.) with subsequent instructions.
- What if the CPU speculatively executes the first part of the branch, and
r0holds an illegal pointer?- If
valid == 1, ther2 = *r0should raise an exception. - If
valid == 0, ther2 = *r0should not raise an exception, even though executed speculatively.
- If
- The CPU retires instructions only after it is sure they won't need to be canceled due to mis-speculation.
- And the CPU retires instructions in order, only after all previous instructions have retired, since only then does it know that no previous instruction faulted.
- Thus a fault by an instruction that was speculatively executed may not occur until a while after the instruction finishes.
- Speculation is, in principle, invisible — part of the CPU implemention, but not part of the specification.
- That is, speculation is intended to increase performance without changing the results that programs compute — to be transparent.
- Some jargon:
- Architectural features — things in the CPU manual, visible to programmers.
- Micro-architectural — not in the manual, intended to be invisible.
2.3 Caches
Another micro-architectural feature: CPU caches.
core L1: va | data | perms TLB L2: pa | data RAM
- If a load misses, data is fetched, and put into the cache.
- L1 ("level one") cache is virtually indexed, for speed.
- A system call leaves kernel data in L1 cache, after return to user space. (Assuming page table has both user and kernel mappings)
- Each L1 entry probably contains a copy of the PTE permission bits.
- On L1 miss: TLB lookup, L2 lookup with phys addr.
- Times:
- L1 hit – a few cycles.
- L2 hit – a dozen or two cycles.
- RAM – 300 cycles.
- A cycle is 1/clockrate, e.g 0.5 nanosecond.
- Why is it safe to have both kernel and user data in the cache?
- Can user programs read kernel data directly out of the cache?
- In real life, micro-architecture is not invisible.
- It affects how long instructions and programs take.
- It's of intense interest to people who write performance-critical code.
- And to compiler writers.
- Intel and other chip makers publish optimization guides, usually vague about details (trade secrets).
2.4 Flush + Reload: Determine if Data was in the Cache
- A useful trick: sense whether something is cached.
- This technique is called Flush+Reload.
- You want to know if function
f()uses the memory at a addressX.- ensure that memory at
Xis not cached. Intel CPUs have aclflushinstructions. Or you could load enough junk memory to force everything else out of the cache. - call
f() - Record the time.
Modern CPUs let you read a cycle counter.
For Intel CPUs, it's the
rdtscinstruction. - load a byte from address
X(you need memory fences to ensure the load really happens) - Record the time again.
- If the difference in times is < (say) 50, the load in #4 hit,
which means
f()must have used memory at addressX. Otherwise not.
- ensure that memory at
2.5 The Meltdown Attack
Back to Meltdown – this time with more detail:
char buf[8192] // the Flush of Flush+Reload clflush buf[0] clflush buf[4096] <some expensive instruction like divide> r1 = <a kernel virtual address> r2 = *r1 r2 = r2 & 1 // speculated r2 = r2 * 4096 // speculated r3 = buf[r2] // speculated <handle the page fault from "r2 = *r1"> // the Reload of Flush+Reload a = rdtsc r0 = buf[0] b = rdtsc r1 = buf[4096] c = rdtsc if b-a < c-b: low bit was probably a 0
- That is, you can deduce the low bit of the kernel data based on which of two cache lines was loaded (
buf[0]vsbuf[4096]). - Point: the fault from
r2 = *r1is delayed until the load retires, which may take a while, giving time for the subsequent speculative instructions to execute. - Point: apparently the
r2 = *r1does the load, even though it's illegal, and puts the result intor2, though only temporarily since reverted by the fault at retirement. - Point: the
r3 = buf[r2]loads some ofbuf[]into the cache, even though change tor3is canceled due to mis-speculation. Since Intel views the cache content as hidden micro-architecture. - The attack often doesn't work
- The conditions for success are not clear.
- Perhaps reliable if kernel data is in L1, otherwise not.
- How could Meltdown be used in a real-world attack?
- The attacker needs to run their code on the victim machine.
- Timesharing: kernel may have other users' secrets, e.g. passwords, keys.
- In I/O or network buffers, or maybe kernel maps off of phys mem.
- Cloud: some container and VMM systems might be vulnerable, so you could steal data from other cloud customers.
- Your browser: it runs untrusted code in sandboxes, e.g. plug-ins, maybe a plug-in can steal your password from your kernel.
- However, Meltdown is not known to have been used in any actual attack.
2.6 Defenses
- A software fix:
- Don't map the kernel in user page tables.
- The paper calls this "KAISER"; Linux now calls it KPTI.
- Requires a page table switch on each system call entry/exit.
- The page table switch can be slow — it may require TLB flushes.
- PCID can avoid TLB flush, though still some expense.
- Most kernels adopted KAISER/KPTI soon after Meltdown was known.
- Don't map the kernel in user page tables.
- A hardware fix:
- Only return permitted data from speculative loads!
- If
PTE_Uis clear, return zero, not the actual data.
- If
- This probably has little or no cost since apparently each L1
cache line contains a copy of the
PTE_Ubit from the PTE. - AMD CPUs apparently worked like this all along.
- The latest Intel CPUs seem to do this (called
RDCL_NO).
- Only return permitted data from speculative loads!
- These defenses are deployed and are believed to work; but:
- It was disturbing that page protections turned out to not be solid!
- More micro-architectural surprises have been emerging.
- Is the underlying issue just fixable bugs? Or an error in strategy?
- Stay tuned, this is still playing out.
3 References
- https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
- https://cyber.wtf/2017/07/28/negative-result-reading-kernel-memory-from-user-mode/
- https://eprint.iacr.org/2013/448.pdf
- https://gruss.cc/files/kaiser.pdf
- https://en.wikipedia.org/wiki/Kernel_page-table_isolation
- https://spectrum.ieee.org/computing/hardware/how-the-spectre-and-meltdown-hacks-really-worked
4 Reading: Meltdown: Reading Kernel Memory from User Space
If you want to learn more about Meltdown, read the paper from the folks who discovered it: Lipp, Moritz, et al. "Meltdown: Reading kernel memory from user space." 27th USENIX Security Symposium (USENIX Security 18). 2018.