CS 332 w22 — Other Approaches to Concurrency
Table of Contents
1 Message Passing
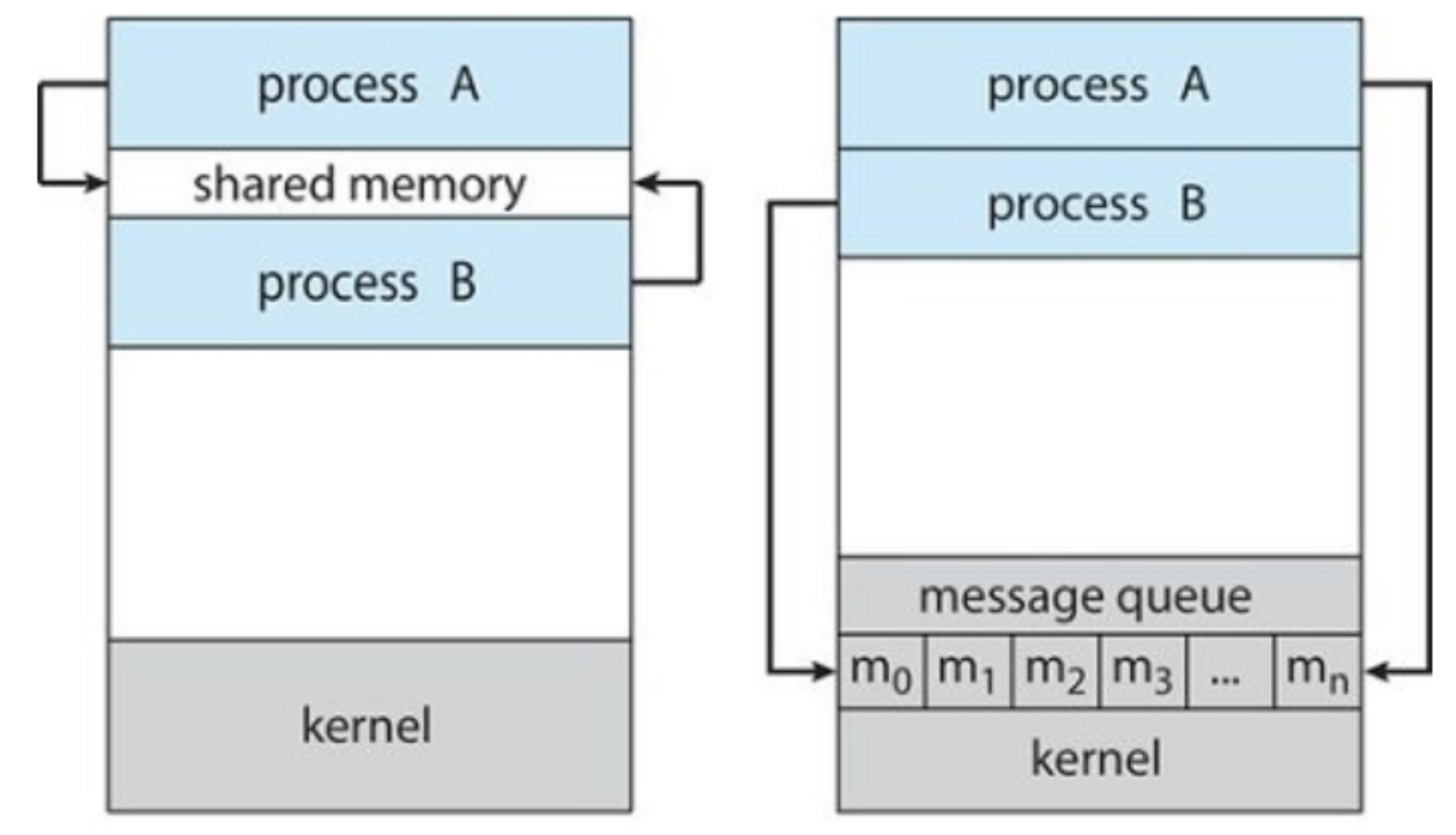
- Alternative to shared memory for communicating threads/processes/objects
- Logically provides
send(message)andreceive(message)operations - Often uses indirect communication where messages are passed via some third object (called a mailbox, a port, or a channel)
send(A, message)— Send a message to mailbox Areceive(A, message)— Receive a message from mailbox A
- Many design decisions to go from this core idea to a real system
- Suppose two threads execute a
receive()fromAsimultaneously, who gets the message? - Are mailboxes owned by a thread (and only that thread can receive messages through it) or are they owned by the runtime system (and can be passed from thread to thread and shared)?
- Should send and receive block until a message has been passed or return immediately?
- How many messages can be queued in a mailbox?
- Suppose two threads execute a
1.1 Actor Model
- Everything is an actor
- An actor, in response to a message it receives, can concurrently:
- Send a finite number of messages to other actors
- Create a finite number of new actors
- Designate the behavior to be used for the next message it receives
- Useful in a distributed system where actors may reside on different servers
- The Erlang programming language uses the actor model
- Facilitates a "let it crash" mentality
- Instead of lots of error-handling code, an actor that crashes notifies its "supervisor" (another actor), who can then respond—usually by restarting the crashed actor
- Actor model provides isolation: one crashed actor doesn’t bring others down
1.2 Communicating Sequential Processess (CSP)
- Similar to the actor model, also based on message passing
- Primary distinctions:
- CSP processes are anonymous, while actors have identities.
- CSP uses explicit channels for message passing, whereas actor systems transmit messages to named destination actors.
- CSP message-passing is fundamentally synchronous, i.e. the sender cannot transmit a message until the receiver is ready to accept it.
- In contrast, message-passing in actor systems is fundamentally asynchronous, i.e. message transmission and reception do not have to happen at the same time, and senders may transmit messages before receivers are ready to accept them.
Contrast this non-CSP fork-join code using threads in C:
#include <stdio.h> #include "thread.h" static void go(int n); #define NTHREADS 10 static thread_t threads[NTHREADS]; int main(int argc, char **argv) { int i; long exitValue; for (i = 0; i < NTHREADS; i++){ thread_create(&(threads[i]), &go, i); } for (i = 0; i < NTHREADS; i++){ exitValue = thread_join(threads[i]); printf("Thread %d returned with %ld\n", i, exitValue); } printf("Main thread done.\n"); return 0; } void go(int n) { printf("Hello from thread %d\n", n); thread_exit(100 + n); // Not reached }
with this CSP code using goroutines in Go:
package main
import (
"fmt"
)
func main() {
output := make(chan int) // creating the channel
for i := 0; i < 10; i++ {
// creating a new go routine and
// sharing the reference of the channel
go myFunc(i, output)
}
fmt.Println("main ready to receive")
for i := 0; i < 10; i++ {
// synchronously receive an integer from the channel
fmt.Printf("goroutine sent %d\n", <-output)
}
}
func myFunc(i int, output chan<- int) {
fmt.Printf("Hello from goroutine %d\n", i)
output <- i + 100
fmt.Printf("goroutine %d finished\n", i)
}2 Asynchronous I/O
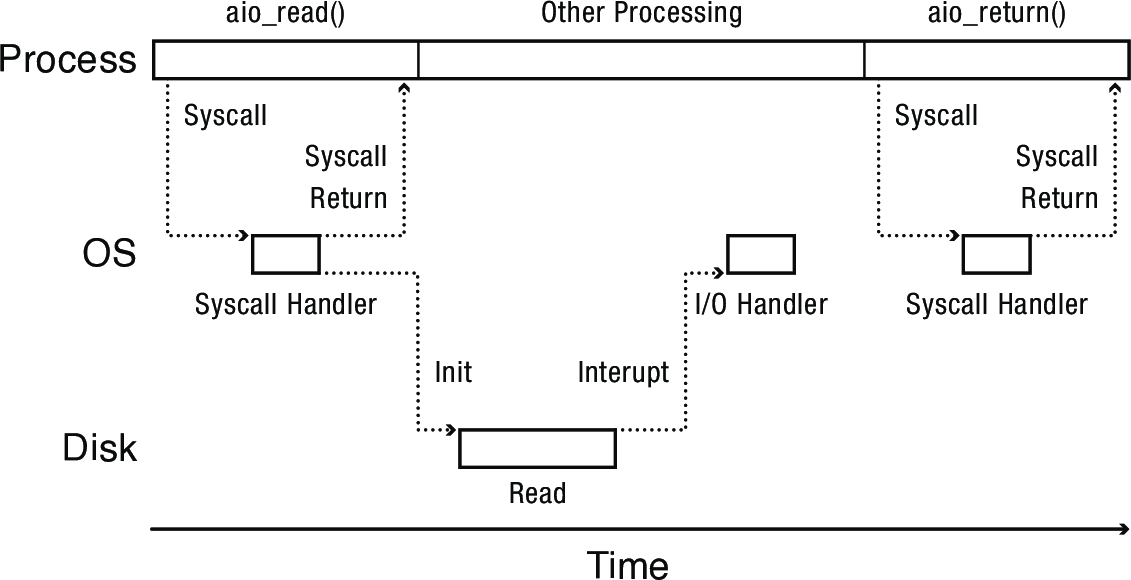
- I/O system call returns immediately, operation is performed asynchronously in the background as the process continues on its way
- Result provided by either
- Calling a signal handler
- Placing the result in a queue in the process's memory
- Storing the result in kernel memory until the process makes another system call to get it
- Allows computation and I/O to overlap without the use of threads
struct aiocb { /* The order of these fields is implementation-dependent */ int aio_fildes; /* File descriptor */ off_t aio_offset; /* File offset */ volatile void *aio_buf; /* Location of buffer */ size_t aio_nbytes; /* Length of transfer */ }
3 Event-Driven Programming
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *errorfds, struct timeval *timeout);
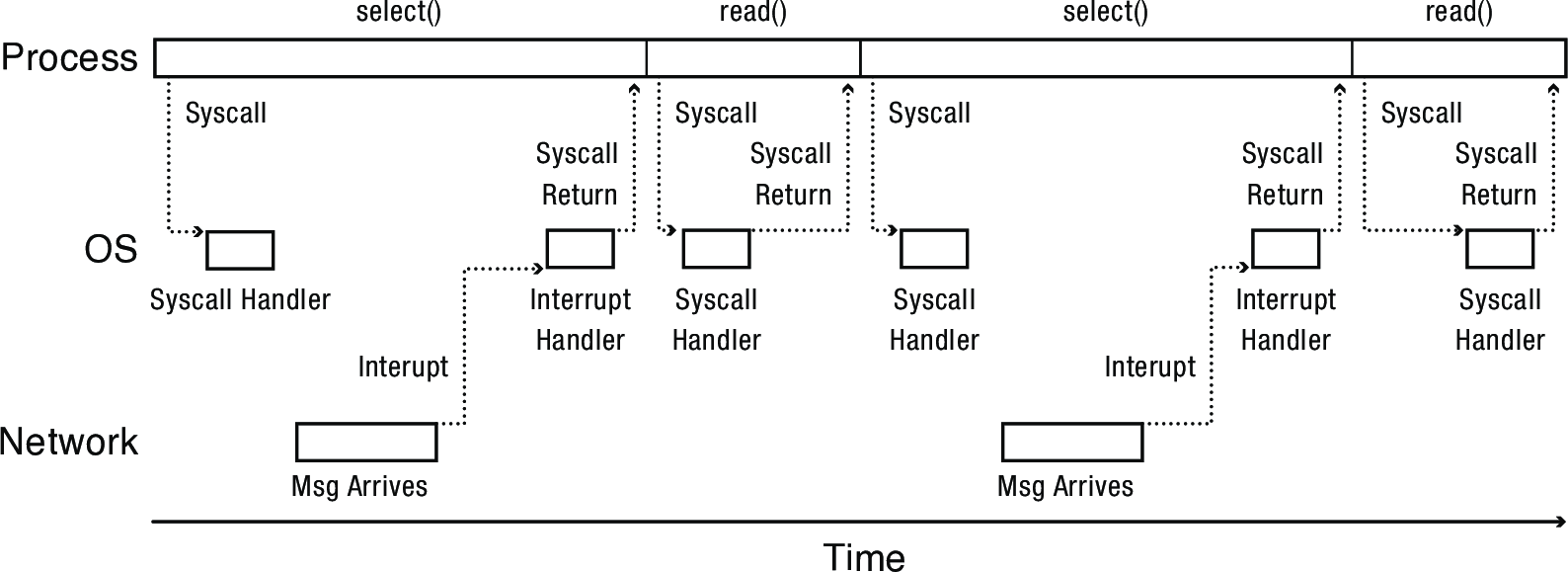
select is a system call that upon return has modified the fd_set arrays to indicate which of the file descriptors in each are ready for reading/writing/have some exceptional condition pending. Passing NULL for timeout will cause select to block until some descriptor is ready.
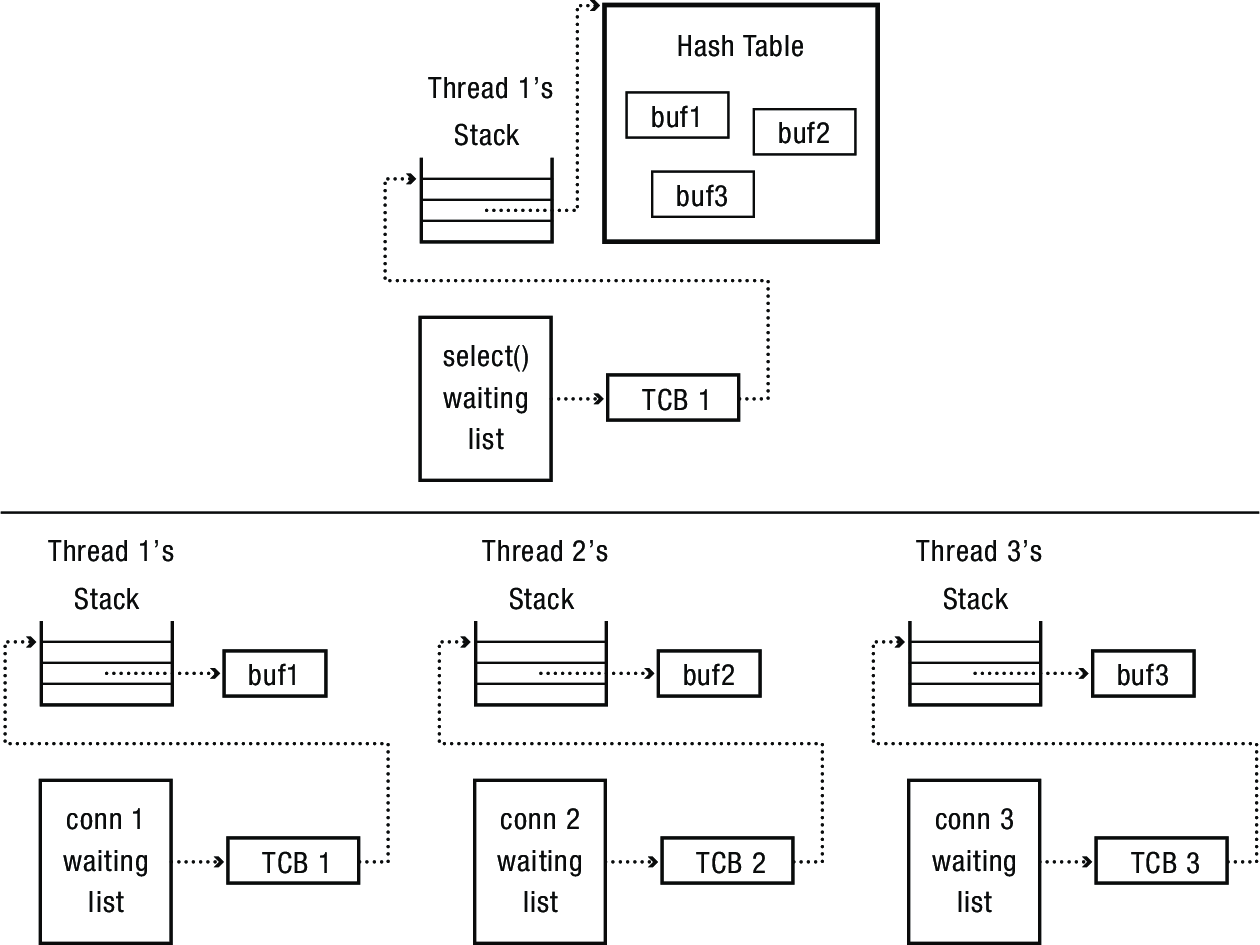
The basic idea is to handle a series of overlapping events with a single thread.
- Thead spins in a loop; each iteration it gets and processes the next I/O event
- Will need a data structure to keep track of where it is in each ongoing task
- Called a continuation
- Ex.: a web request has a series of I/O steps (make a network connection, read from the connection, read requested data from disk, and write data to the connection)
- Request may also be split into multiple packets
- A packet is a unit of formatted data transmitted across a network
- Server needs to keep track of packets received and then where it is in the sequence of steps for that client
- Request may also be split into multiple packets
- Asynchronous I/O is an essential component of making event-driven programming work in practice
- If the thread has to block for a long-running I/O operation, no events get processed in the meantime (bad!)
3.1 Event-Driven Programming vs Threads
- Coping with high-latency I/O devices
- Traditionally, event-driven programming had a clear advantage due to lower overhead
- These days larger memories and more scalable threads have narrowed the gap significantly
- Exploiting multiple processors
- Event-driven programming does not inherently help a program exploit multiple processors
- In practice, event-driven and thread approaches are combined, with each thread following the event-driven pattern to handle I/O
- Shifting work to run in the background
- Event-driven programming is best suited to short-lived tasks; threads are a better fit for a mix of short, immediate tasks and longer, background tasks
- Expressing logically concurrent tasks
- Largely a matter of taste, which means there are strong opinions on both sides
4 Data Parellel Programming
- A declarative form of concurrent programming
- Programmer describes the computation to apply across the entire dataset
- Runtime system decides how to map parallel work across available processors
- Runtime itself may be implemented using threads, invisible to the programmer
- Commonly used in large-scale data analysis tasks
- Hadoop: open source system that can process terabytes of data spread over 1000s of servers
- Ex.: update popularity estimate of each web page based on pages that refer to it
- SQL (Structured Query Language): language for accessing databases
- Programmer describes the desired result (query), database creates lower-level program to implement it (possibly using threads)
- Hadoop: open source system that can process terabytes of data spread over 1000s of servers
- Rendering pixels on a screen—perform a similar operation across all elements of a large dataset
- GPUs (Graphical Processing Units) are specialized hardware for this task
- Can be an order of magnitude faster than a CPU
Imperative code:
/* * bzero.c -- Multi-threaded program to zero a block of data * * Compile with * > gcc -g -Wall -Werror -D_POSIX_THREAD_SEMANTICS bzero.c -c -o bzero.o * > gcc -g -Wall -Werror -D_POSIX_THREAD_SEMANTICS thread.c -c -o thread.o * > gcc -lpthread bzero.o thread.o -o bzero * Run with * > ./bzero */ #include <stdio.h> #include <string.h> #include <assert.h> #include "thread.h" #define BUFSIZE 1000 static unsigned char zeroblock[BUFSIZE]; static unsigned char testblock[BUFSIZE]; int main(int argc, char **argv) { // first, initialize the testblock to a known value (void) memset(testblock, 0x55, BUFSIZE); (void) memset(zeroblock, 0x0, BUFSIZE); // test the parallel block zero blockzero(testblock, BUFSIZE); // compare against the known zero block if (memcmp(testblock, zeroblock, BUFSIZE) == 0) printf("Success!\n"); else printf("block zero failed!\n"); } // To pass two arguments, we need a struct to hold them. typedef struct bzeroparams { unsigned char *buffer; int length; }; #define NTHREADS 10 // Zero a block of memory using multiple threads. void blockzero (unsigned char *p, int length) { int i, j; thread_t threads[NTHREADS]; struct bzeroparams params[NTHREADS]; // For simplicity, assumes length is divisible by NTHREADS. assert((length % NTHREADS) == 0); for (i = 0, j = 0; i < NTHREADS; i++, j += length/NTHREADS) { params[i].buffer = p + i * length/NTHREADS; params[i].length = length/NTHREADS; thread_create_p(&(threads[i]), &go, ¶ms[i]); } for (i = 0; i < NTHREADS; i++) { thread_join(threads[i]); } } void go (struct bzeroparams *p) { memset(p->buffer, 0, p->length); thread_exit(0); // Not reached }
vs a delcarative version:
forall i in 0:N-1
array[i] = 0
5 Non-Blocking Synchronization
- What if we could design concurrent data structures where threads would never block (i.e., never have to wait for another thread)?
- Acquiring a lock is a blocking operation, since a thread may have to wait
- A wait-free data structure is one that guarantees progress for every thread
- A lock-free data structure is one that guarantees progress for some thread
compare-and-swapinstruction is a typical building block- A lock-free hash table with an array of pointers to each bucket
lookup: a lookup deferferences the pointer and checks the bucketupdate: a thread allocates a new copy of the bucket, then usescompare-and-swapto atomically replace the existing pointer if and only if it has not been changed in the meantime. If two threads simultaneously update, one will succeed and the other must retry.
- A lock-free hash table with an array of pointers to each bucket
6 Reading: Concurrent Data Structures
Read OSTEP chapter 33, (p. 425-434). It goes into more detail about the Linux event-driven API.