CS 332 w22 — Threads
Table of Contents
In The Process Model topic, we saw that a process consists of (at least):
- An address space, containing
- the code (instructions) for the running program
- the data for the running program (static data, heap data, stack)
- Thread state, consisting of
- The program counter (PC), indicating the next instruction
- The stack pointer (implying the stack it points to)
- Other general purpose register values
- A set of OS resources
- open files, network connections, sound channels, …
In today's topic, we will decompose these and separate the concepts of thread and process.
1 The Big Picture
Threads are about concurrency and parallelism
- Parallelism: physically simultaneous operations for performance
- Concurrency: logically (and possibly physically) simultaneous operations for convenience/simplicity
- One way to get concurrency and parallelism is to use multiple processes
- The programs (code) of distinct processes are isolated from each other
- Threads are another way to get concurrency and parallelism
- Threads share a process — same address space, same OS resources
- Threads have private stack, CPU state — they are separately schedulable units
1.1 Examples
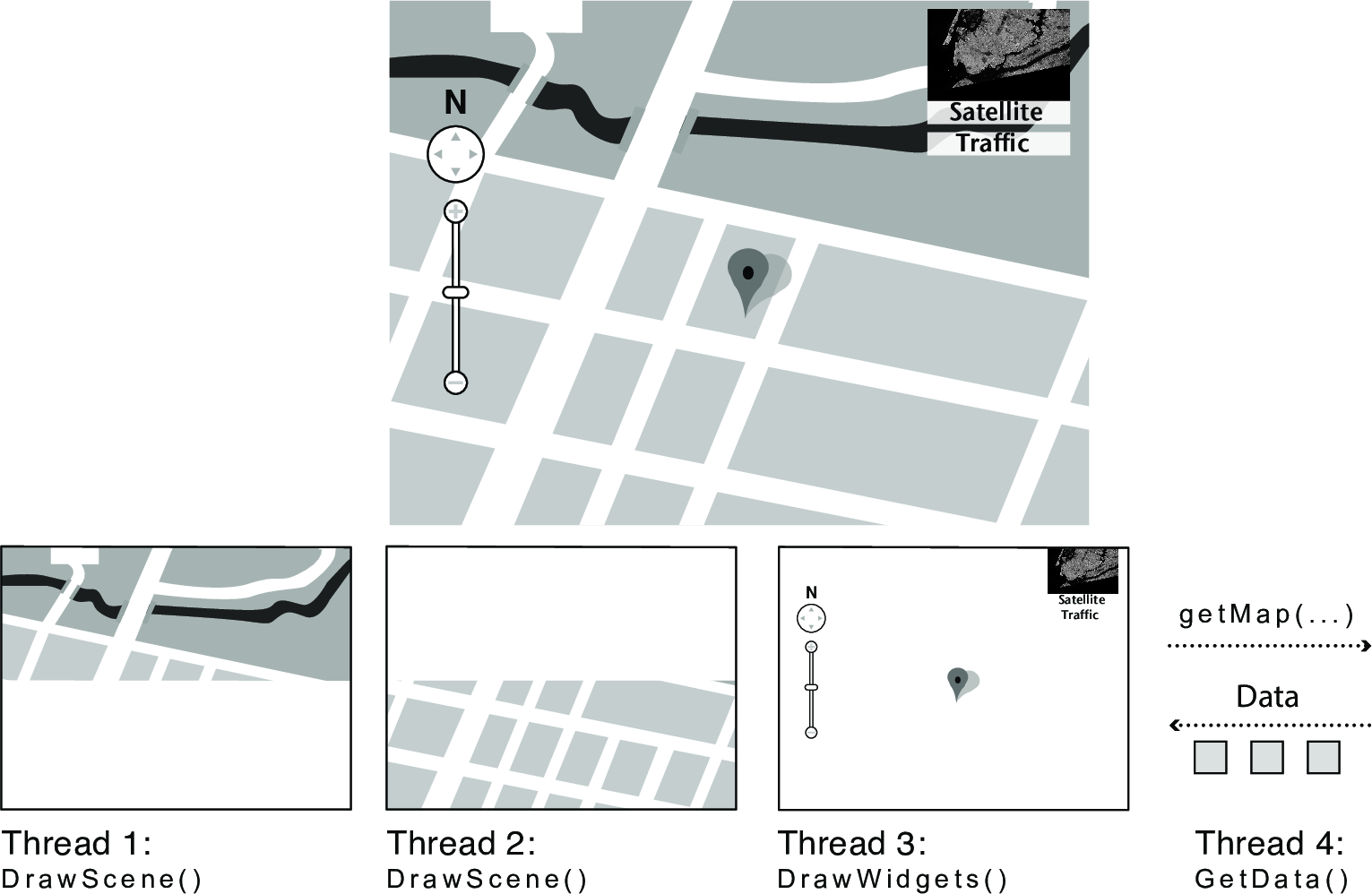
Consider an Earth Visualizer similar to Google Earth. This application lets the user virtually fly anywhere in the world, see aerial images at different resolutions, and view other information associated with each location. A key part of the design is that the user's controls are always up herbal: when the user moves the mouse to a new location, the image is redrawn in the background at successively better resolutions while the program continues to let the user adjust of you, select additional information about the location for display, or enter search terms.
To implement this application the programmer might write code to draw a portion of the screen, display user interface widgets, process user inputs, and fetch higher-resolution images for newly visible areas. In a sequential program, these functions would run in turn. With threads, they can run concurrently so that the user interface is responsive even while new data is being fetched and the screen being redrawn.
Other examples:
- Imagine a web server, which might like to handle multiple requests concurrently
- While waiting for the credit card server to approve a purchase for one client, it could be retrieving the data requested by another client from disk, and assembling the response for a third client from cached information
- Imagine a web client (browser), which might like to initiate multiple requests concurrently
- The Carleton CS home page has dozens of "src= …" HTML commands, each of which is going to involve a lot of sitting around! Wouldn't it be nice to be able to launch these requests concurrently?
- Imagine a parallel program running on a multiprocessor, which might like to employ "physical concurrency"
- For example, multiplying two large matrices — split the output matrix into \(k\) regions and compute the entries in each region concurrently, using \(k\) processors
1.2 What's the goal?
- If I want more than one thing running at a time, I already have a mechanism to achieve that
- Processes
- What's wrong with processes?
- IPC (inter-process communication) is slow
- Why?1
- IPC (inter-process communication) is slow
- What's right with processes?
- Convenient abstraction of CPU, memory, I/O
1.2.1 What's needed?
- You'd like to have multiple hardware execution states:
- an execution stack and stack pointer (SP)
- traces state of procedure calls made
- the program counter (PC), indicating the next instruction
- a set of general-purpose processor registers and their values
- an execution stack and stack pointer (SP)
- That's a thread
- You’d like to have very fast communication among the separate execution contexts
- Use shared memory
- All threads run in the same virtual address space
- Globals are shared
- Locals are "private"
- Except there is no enforcement of that (threads are free to access any addresses in their shared virtual address space)
- Use shared memory
1.2.2 How could we achieve this?
- Key idea:
- separate the concept of a process (address space, OS resources)
- … from that of a thread of control (execution state: stack, stack pointer, program counter, registers)
- This execution state is usually called a thread
1.3 Reading: Concurrency: An Introduction
Read Chapter 26 (p. 303–315) of the OSTEP book. It gives a concise overview of the idea of threads and how they're used. The chapter also previews the challenge we will spend the next three weeks exploring: how can we effectively and efficiently coordinate among concurrent threads?
Key terms:
- thread-local
- interleaving (when the ordering of operations from multiple threads mix together, they interleave—a given potential ordering is called an interleaving)
- race condition or data race
- critical section
- mutual exclusion
- atomic operation
2 What Are Threads?
- Most modern OS's therefore support two entities:
- the process, which defines the address space and general process attributes (such as open files, etc.)
- the thread, which defines a sequential execution stream within a process
- A thread is bound to a single process / address space
- address spaces can have multiple threads executing within them
- sharing data among threads is cheap: all see the same address space
- creating threads is cheap too!
- Threads become the unit of scheduling
- processes / address spaces are just containers in which threads execute
- threads provide an execution model in which each thread runs on a dedicated virtual processor with unpredictable and variable speed
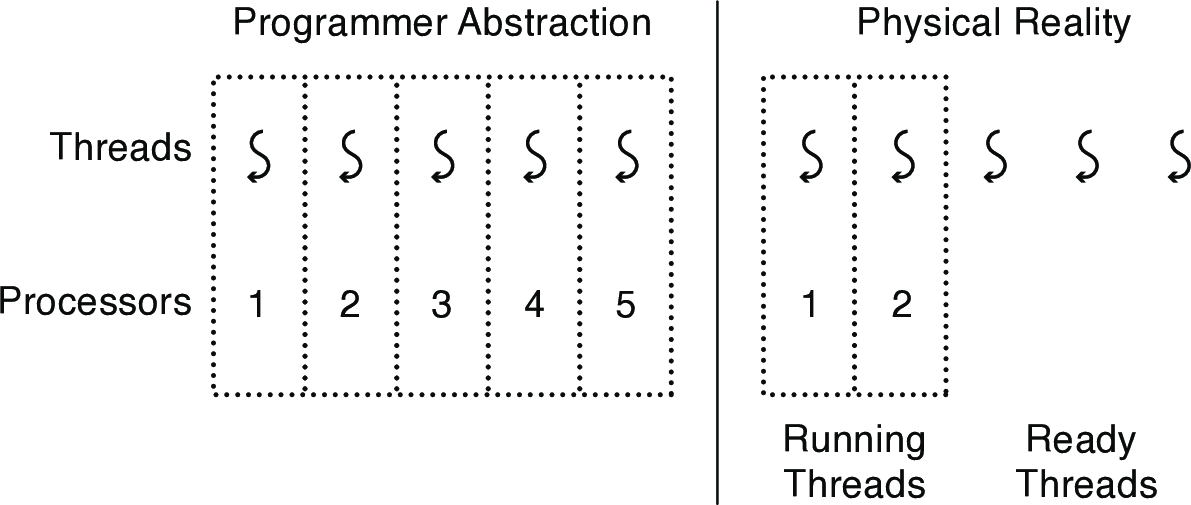
- Why "unpredictable speed"?
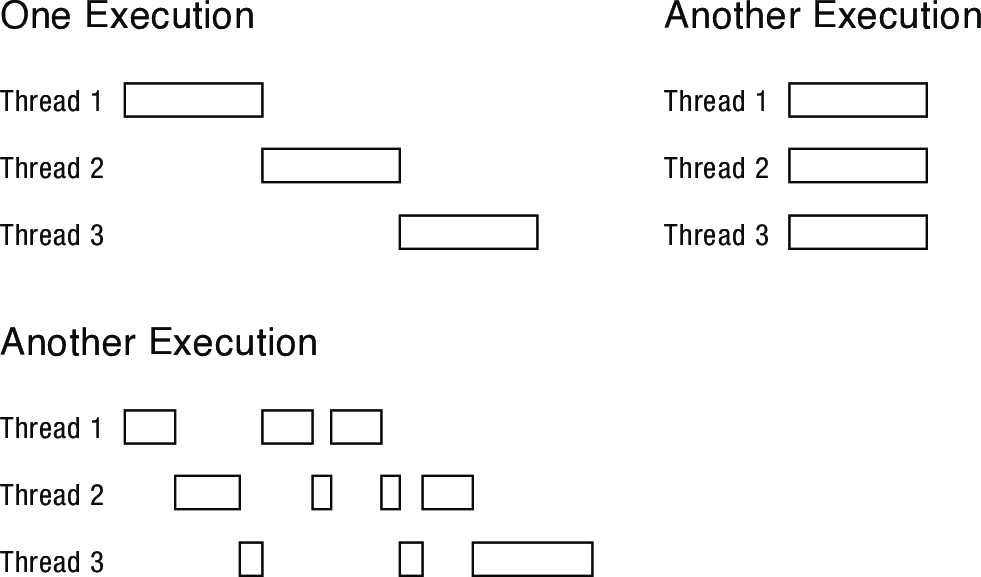
- The scheduler and available processors can lead to many possible interleavings (see examples below).
- Thread programmers should therefore not make any assumptions about the relative speed with which different threads execute.
- Threads are concurrent executions sharing an address space (and some OS resources)
- Address spaces provide isolation
- If you can't name it, you can't read or write it
- Hence, communicating between processes is expensive
- Must go through the OS to move data from one address space to another
- Because threads are in the same address space, communication is simple/cheap
- Just update a shared variable!
- Address spaces provide isolation
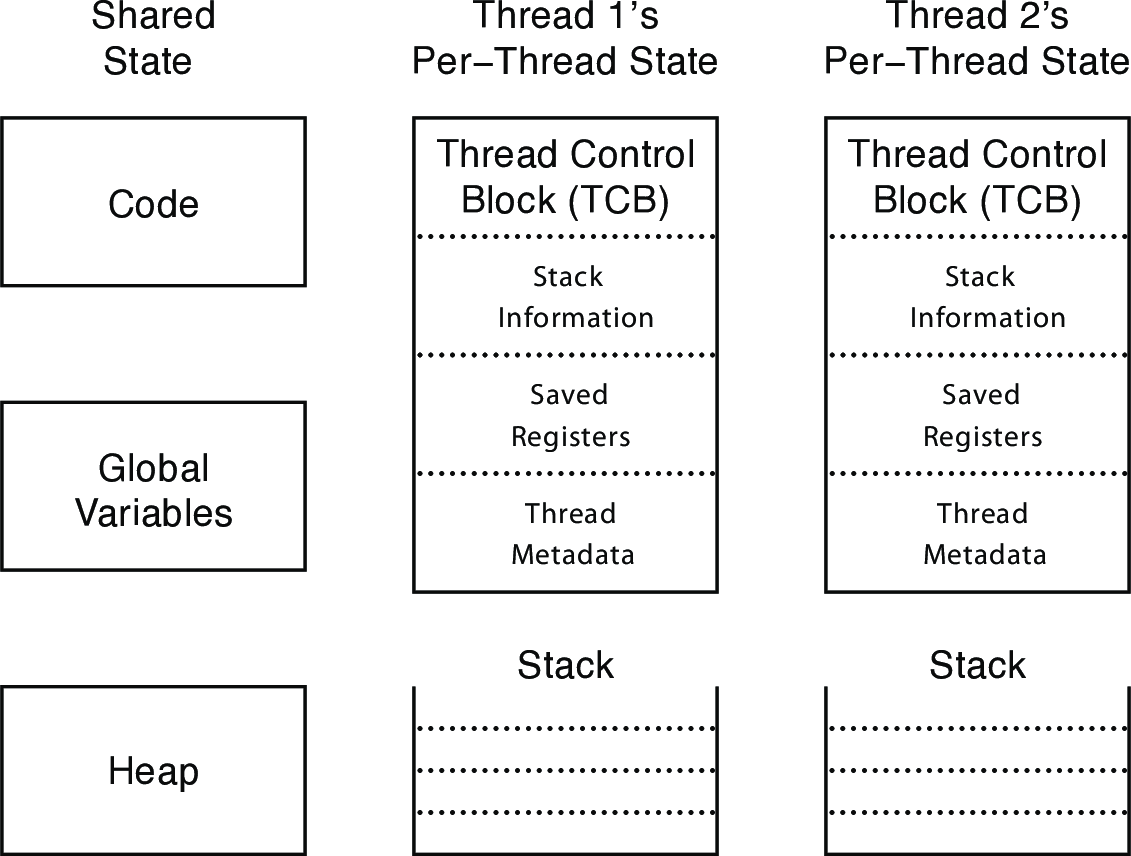
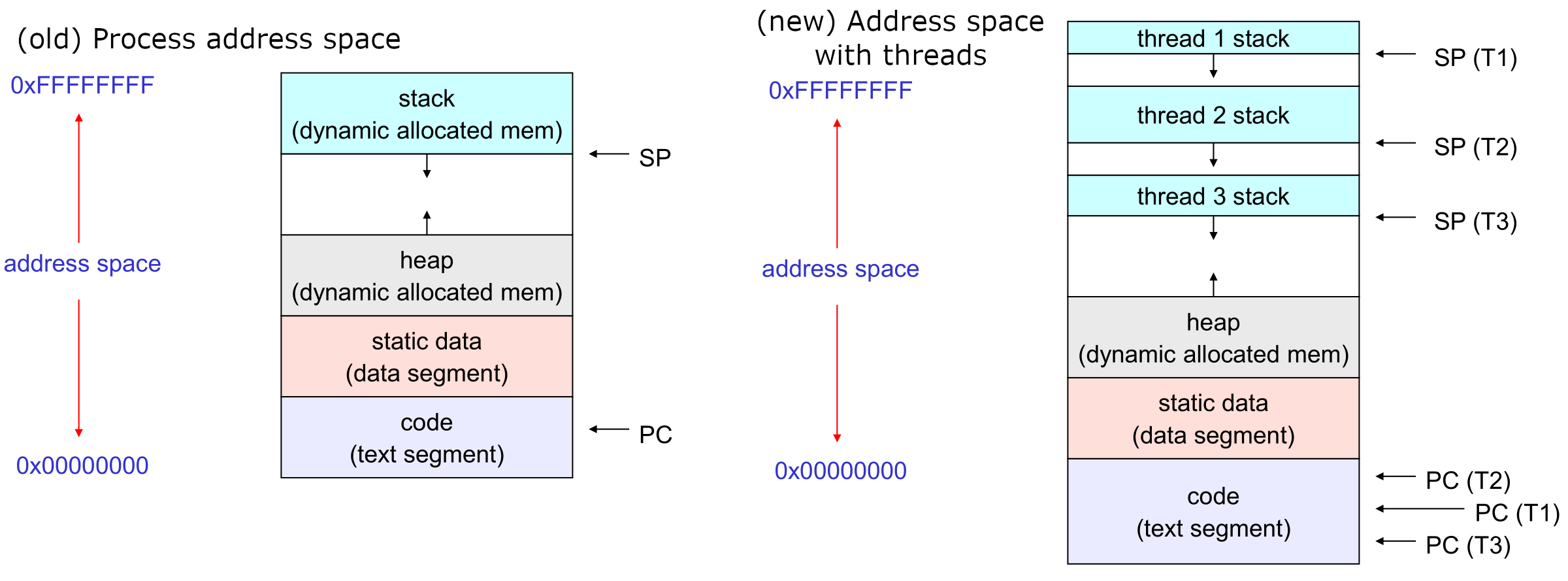
2.1 The Process/Thread Separation
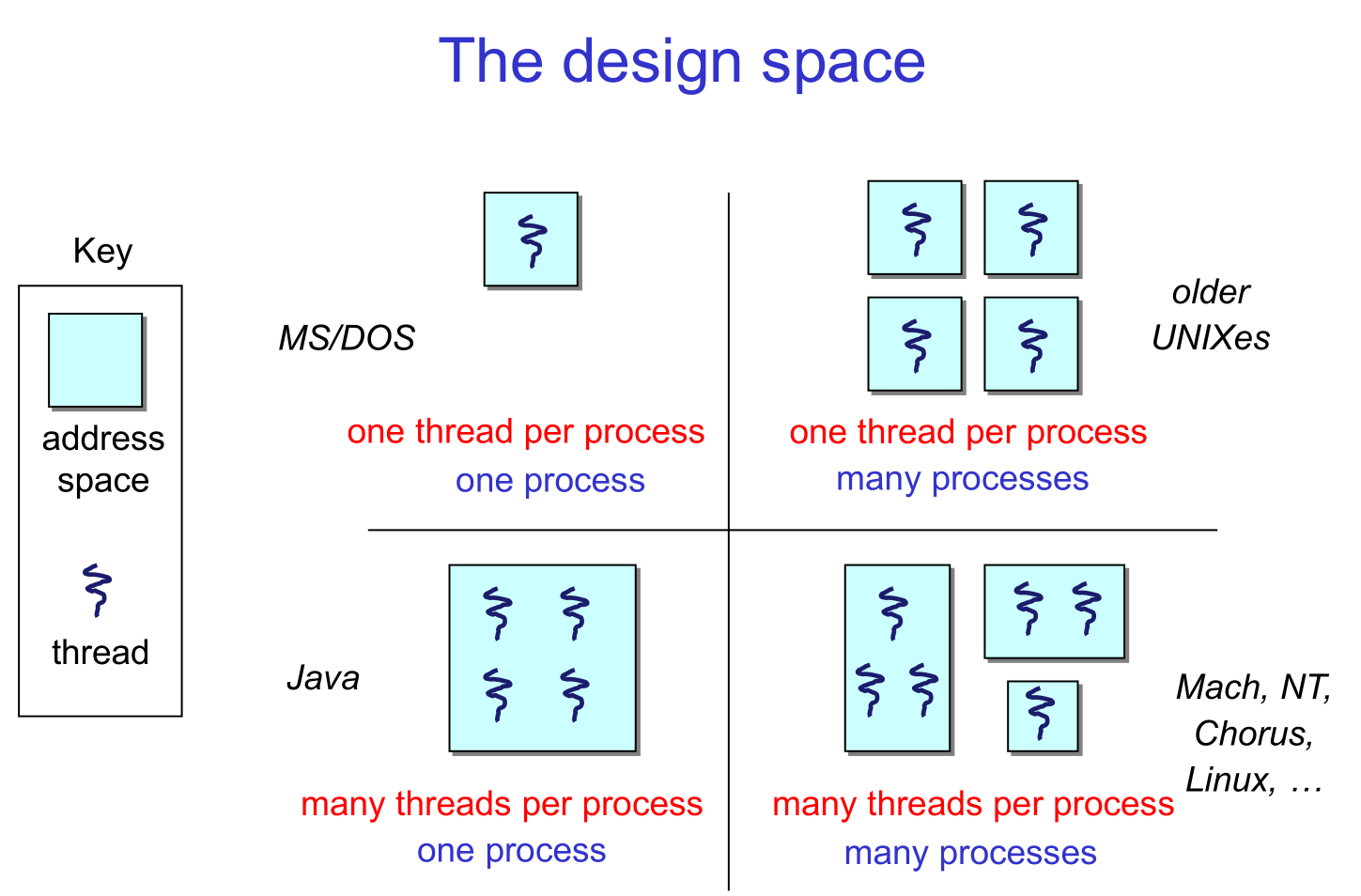
Different aspects of this diagram:
- one thread per process: a simple, single-threaded application running in user mode, using system calls to ask the kernel to perform privileged operations
- many threads per process: a process has multiple concurrent threads, all executing in user mode. At any given time a subset of these threads may be running while the rest are suspended.
- many single-threaded processes: as recently as 20 years ago, many operating systems supported multiple processes, but only one thread per process (this is the model osv uses, in fact). To the kernel, however, each process looks like a thread: a separate sequence of instructions, executing sometimes in the kernel and sometimes at user level. For example, on a multiprocessor, if multiple processes perform system calls at the same time, the kernel, in effect, has multiple threads executing concurrently in kernel mode.
- many kernel threads: to manage complexity, shift work to the background, exploit parallelism, and hide I/O latency, the operating system kernel itself can benefit from using multiple threads. In this case, each kernel thread runs with the privileges of the kernel. The operating system kernel itself implements the thread abstraction for its own use.
Supporting multithreading — that is, separating the concept of a process (address space, files, etc.) from that of a minimal thread of control (execution state), is a big win. It means that creating concurrency does not require creating new processes. Since processes have a lot more overhead than threads (e.g., a whole new address space), this makes concurrency faster / better / cheaper. Multithreading is useful even on a single core processor running only one thread at a time—why?5
3 Multi-threaded Hello, World
3.1 Simple Thread API
| call | description |
|---|---|
void thread_create(thread, func, arg) |
Create a new thread, storing information about it in thread. Concurrently with the calling thread, thread executes the function func with the argument arg |
void thread_yield() |
The call thread voluntarily gives up the processor to let some other thread(s) run. The scheduler can resume running the calling thread whenever it chooses to do so. |
int thread_join(thread) |
Wait for thread to finish if it has not already done so; then return the value passed to thread_exit by that thread. Note that thread_join may be called only once for each thread. |
void thread_exit(ret) |
Finish the current thread. Store the value ret in the current thread's data structure. If another thread is already wainting in a vall to thread_join, resume it. |
- thread API analogous to asynchronous procedure call
thread_createis similar tofork/exec,thread_joinis similar towait
3.2 Code
#include <stdio.h> #include "thread.h" static void go(int n); #define NTHREADS 10 static thread_t threads[NTHREADS]; int main(int argc, char **argv) { int i; long exitValue; for (i = 0; i < NTHREADS; i++){ thread_create(&(threads[i]), &go, i); } for (i = 0; i < NTHREADS; i++){ exitValue = thread_join(threads[i]); printf("Thread %d returned with %ld\n", i, exitValue); } printf("Main thread done.\n"); return 0; } void go(int n) { printf("Hello from thread %d\n", n); thread_exit(100 + n); // Not reached }
thread_tis a struct with thread-specific metadata- the second argument,
gois a function pointer—where the newly created thread show begin execution - the third argument,
i, is passed to the function
3.3 Output
$ ./threadHello Hello from thread 0 Hello from thread 1 Thread 0 returned 100 Hello from thread 3 Hello from thread 4 Thread 1 returned 101 Hello from thread 5 Hello from thread 2 Hello from thread 6 Hello from thread 8 Hello from thread 7 Hello from thread 9 Thread 2 returned 102 Thread 3 returned 103 Thread 4 returned 104 Thread 5 returned 105 Thread 6 returned 106 Thread 7 returned 107 Thread 8 returned 108 Thread 9 returned 109
- why might the "Hello" message from thread 2 print after the "Hello" message from thread 5, even though thread 2 was created before thread 5?
- creating and scheduling are separate operations: only assumption is that threads run on their own virtual processor with unpredictable speed, any interleaving is possible
- why must the "Thread returned" message from thread 2 print before the Thread returned message from thread 5?
- the threads can finish in any order, but the main thread waits for them in the order they were created
- what is the minimum and maximum number of threads that could exist when thread 5 prints "Hello"?
- minimum is 2 threads: thread 5 and the main thread
- maximum is 11 threads: all 10 could have been created, while 5 is the first to run
3.4 Links to source code
4 Thread Life Cycle
| State of Thread | Location of Thread Control Block (TCB) | Location of Registers |
|---|---|---|
| INIT | Being created | TCB |
| READY | Ready list | TCB |
| RUNNING | Running list | Processor |
| WAITING | Sychronization variable's waiting list | TCB |
| FINISHED | Finished list, then deleted | TCB or deleted |
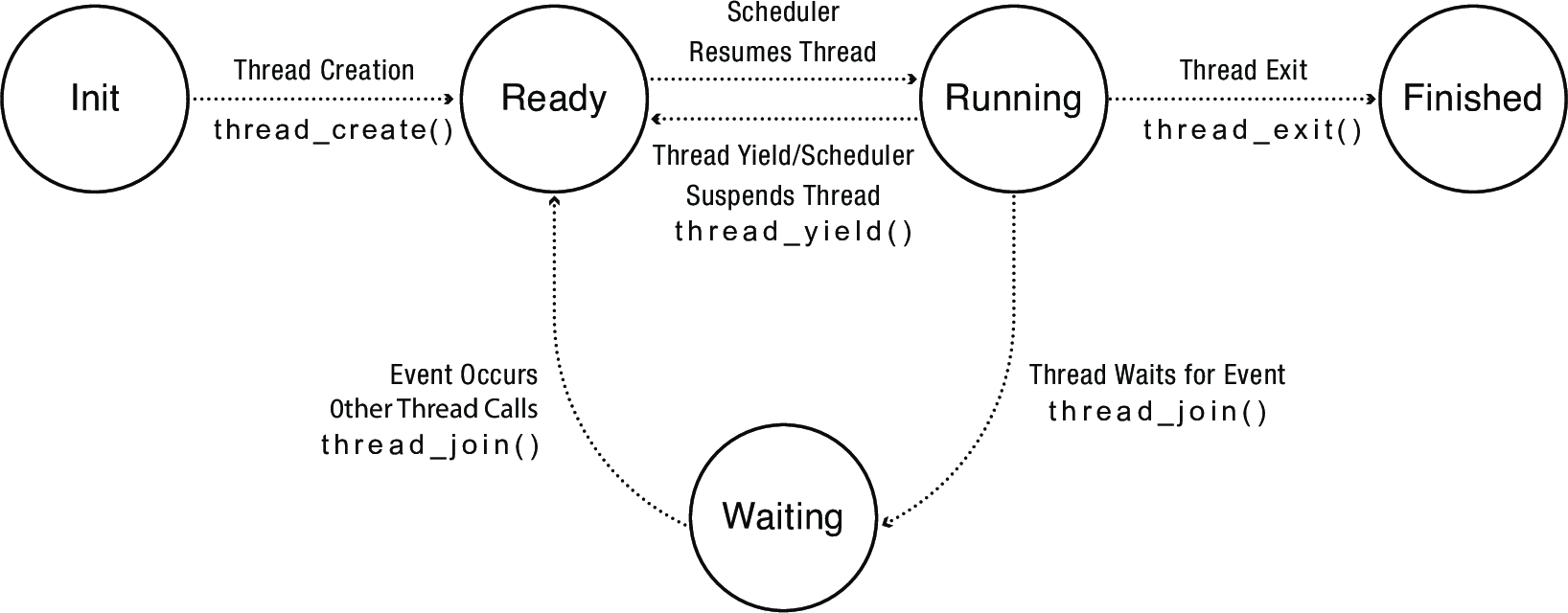
Note: not all operating systems keep a separate ready and running lists. In Linux, the RUNNING thread is whichever thread is at the front of the ready list.
5 Where Do Threads Come From?
5.1 Kernel Threads
Natural answer: the OS is responsible for creating/managing threads
- For example, the kernel call to create a new thread would
- allocate an execution stack within the process address space
- create and initialize a Thread Control Block
- stack pointer, program counter, register values
- stick it on the ready queue
- We call these kernel threads
- There is a thread name space
- Thread ids (TIDs)
- TIDs are integers (surprise!)
- Why "must" the kernel be responsible for creating/managing threads?
- it's the scheduler
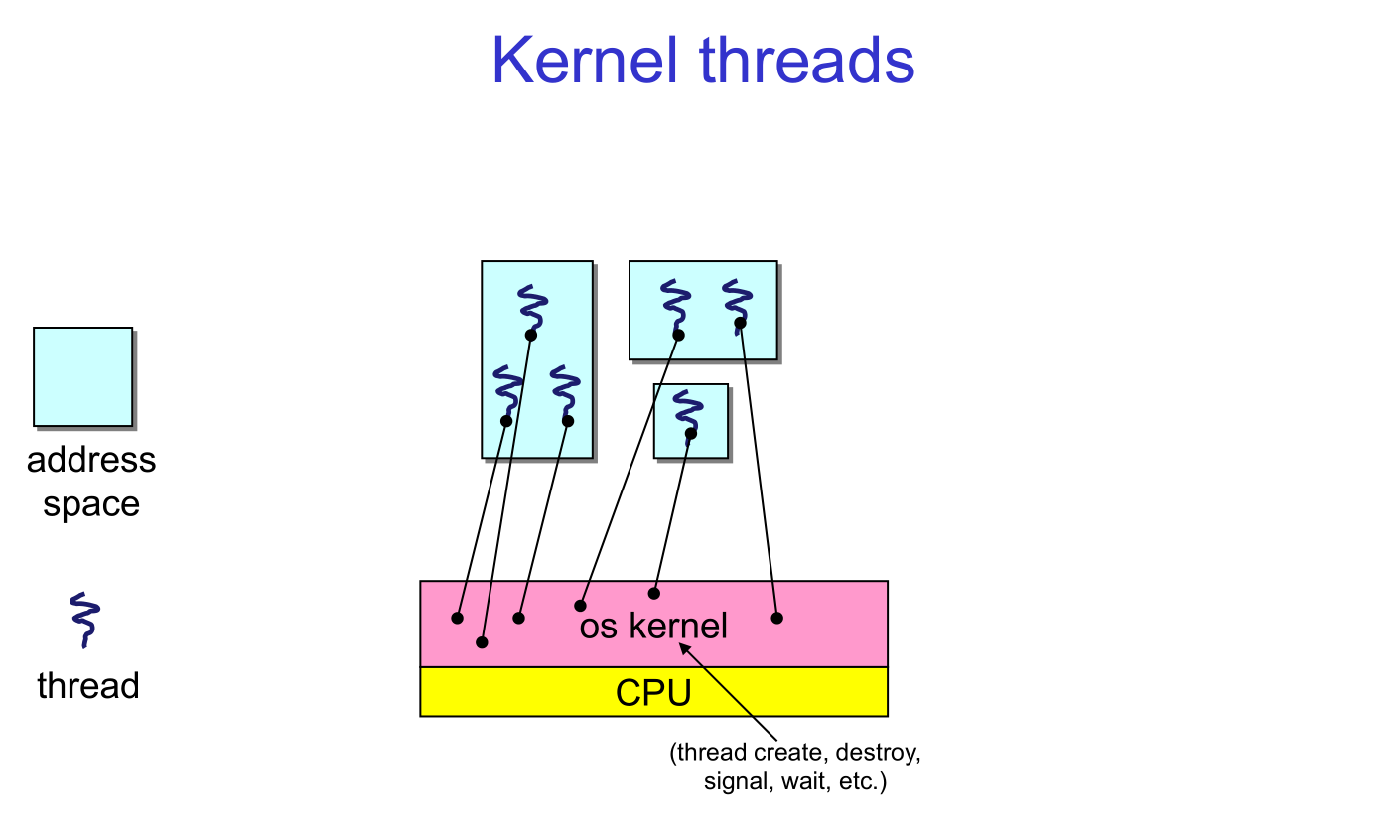
- OS now manages threads and processes / address spaces
- all thread operations are implemented in the kernel
- OS schedules all of the threads in a system
- if one thread in a process blocks (e.g., on I/O), the OS knows about it, and can run other threads from that process
- possible to overlap I/O and computation inside a process
- that is, under programmer control
- Kernel threads are cheaper than processes
- less state to allocate and initialize
- But, they're still pretty expensive for fine-grained use
- orders of magnitude more expensive than a procedure call
- thread operations are all system calls
- context switch
- argument checks
5.2 User-level Threads
- There is an alternative to kernel threads
- Note that thread management isn't doing anything that feels privileged
- Threads can also be managed at the user level (that is, entirely from within the process)
- a library linked into the program manages the threads
- because threads share the same address space, the thread manager doesn't need to manipulate address spaces (which only the kernel can do)
- threads differ (roughly) only in hardware contexts (PC, SP, registers), which can be manipulated by user-level code
- the thread package multiplexes user-level threads on top of kernel thread(s)
- each kernel thread is treated as a "virtual processor"
- we call these user-level threads
- a library linked into the program manages the threads
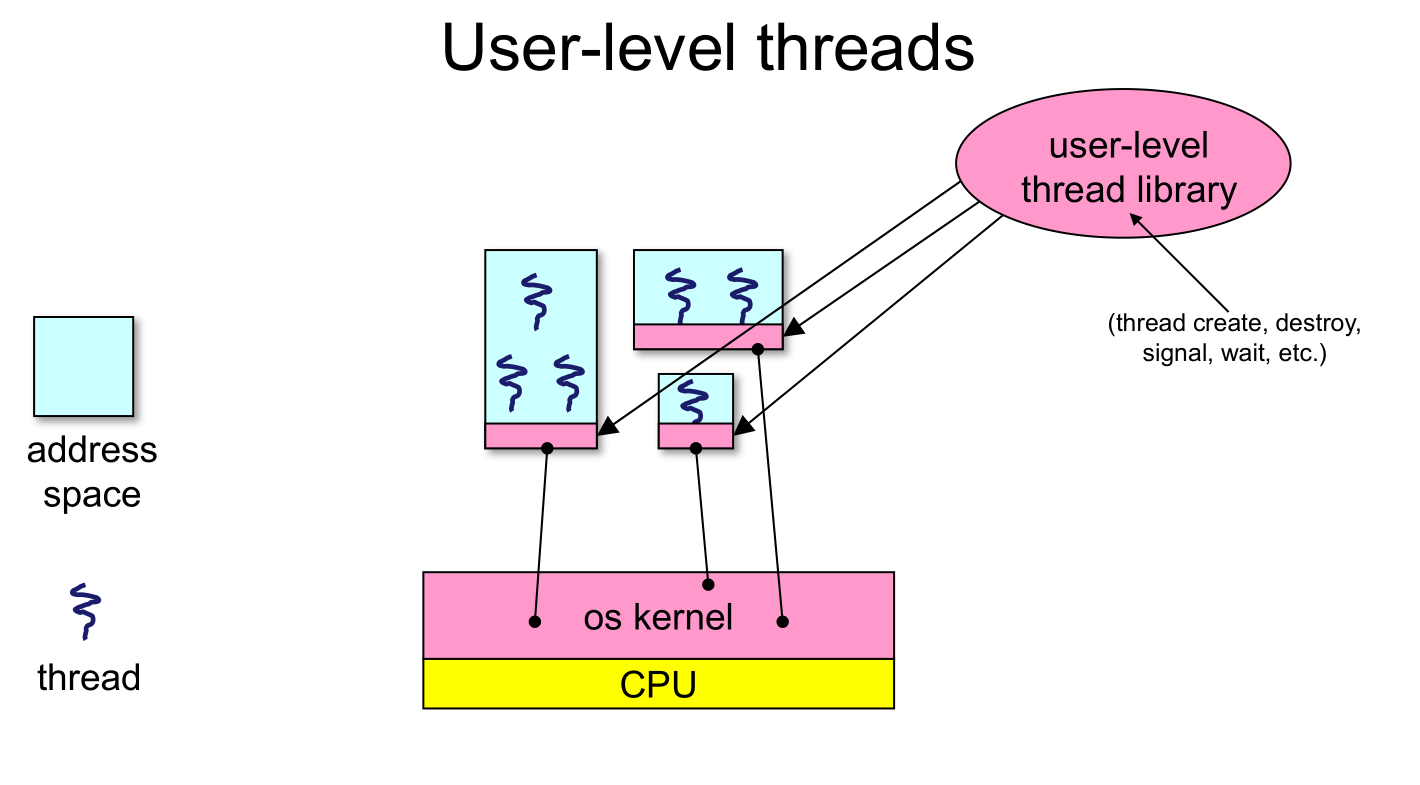
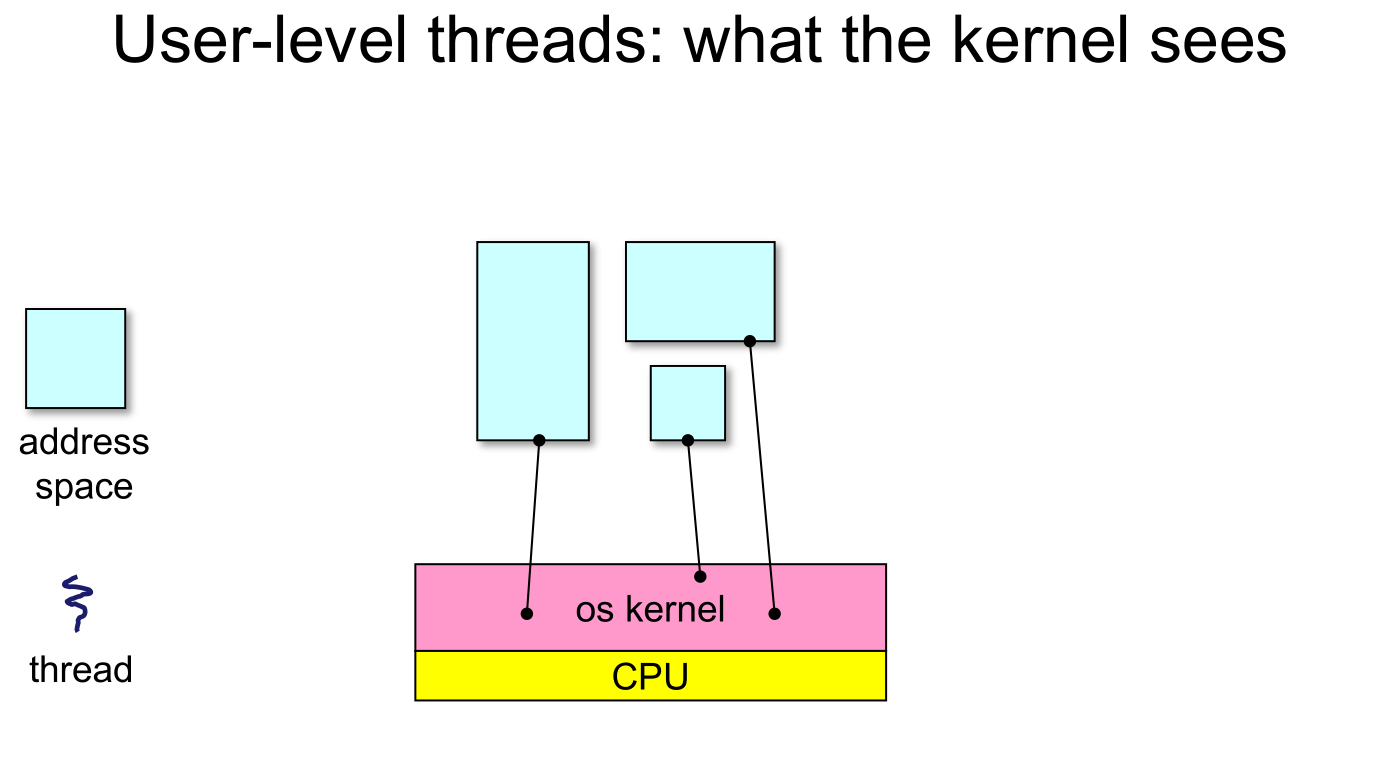
- User-level threads are small and fast
- managed entirely by user-level library
- e.g., pthreads (
libpthreads.a)
- e.g., pthreads (
- each thread is represented simply by a PC, registers, a stack, and a small thread control block (TCB)
- creating a thread, switching between threads, and synchronizing threads are done via procedure calls
- no kernel involvement is necessary!
- user-level thread operations can be 10-100x faster than kernel threads as a result
- managed entirely by user-level library
- The OS schedules the kernel thread
- The kernel thread executes user code, including the thread support library and its associated thread scheduler
- The thread scheduler determines when a user-level thread runs
- it uses queues to keep track of what threads are doing: run, ready, wait
- just like the OS and processes
- but, implemented at user-level as a library
- it uses queues to keep track of what threads are doing: run, ready, wait
5.2.1 User-level Context Switch
- Very simple for user-level threads:
- save context of currently running thread
- push CPU state onto thread stack
- restore context of the next thread
- pop CPU state from next thread’s stack
- return as the new thread
- execution resumes at PC of next thread
- Note: no changes to memory mapping required!
- save context of currently running thread
- This is all done by assembly language
How to keep a user-level thread from hogging the CPU?
- Strategy 1: force everyone to cooperate
- a thread willingly gives up the CPU by calling
yield() yield()calls into the scheduler, which context switches to another ready thread- what happens if a thread never calls
yield()?
- a thread willingly gives up the CPU by calling
- Strategy 2: use preemption
- scheduler requests that a timer interrupt be delivered by the OS periodically
- usually delivered as a UNIX signal
- signals are just like software interrupts, but delivered to user-level by the OS instead of delivered to OS by hardware
- at each timer interrupt, scheduler gains control and context switches as appropriate
- scheduler requests that a timer interrupt be delivered by the OS periodically
5.2.2 User-level Thread I/O
- When a user-level thread does I/O, the kernel thread "powering" it is lost for the duration of the (synchronous) I/O operation!
- The kernel thread blocks in the OS, as always
- It maroons with it the state of the user-level thread
- Could have one kernel thread "powering" each user-level thread
- "common case" operations (e.g., synchronization) would be quick
- Could have a limited-size “pool” of kernel threads "powering" all the user-level threads in the address space
- the kernel will be scheduling these threads, obliviously to what's going on at user-level
- What if the kernel preempts a thread holding a lock?
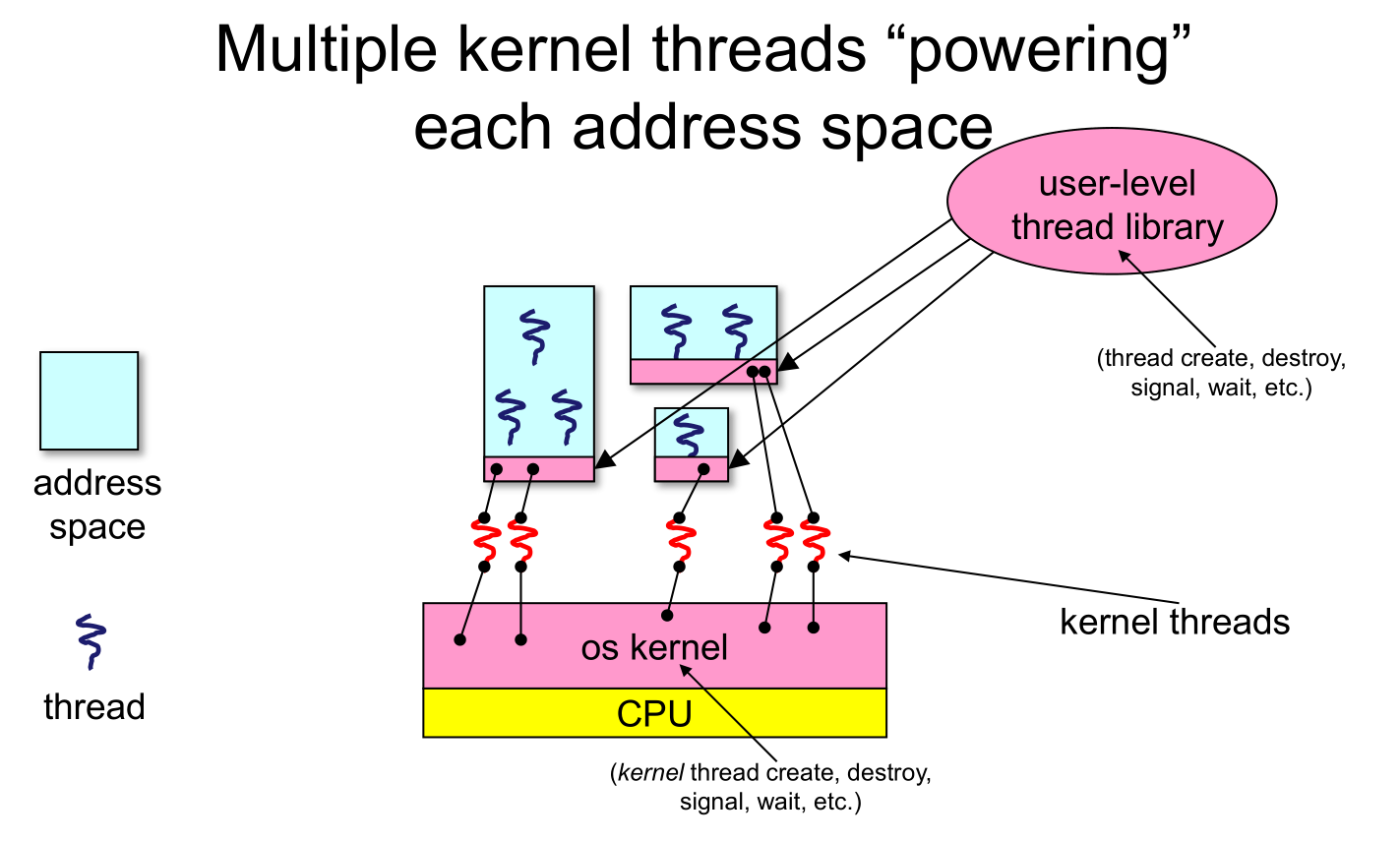
- Effective coordination of kernel decisions and user-level threads requires OS-to-user-level communication
- OS notifies user-level that it has suspended a kernel thread
- This is called scheduler activations
- a research paper from the 1990s with huge effect on practice
- each process can request one or more kernel threads
- process is given responsibility for mapping user-level threads onto kernel threads
- kernel promises to notify user-level before it suspends or destroys a kernel thread
Footnotes:
Processes are isolated from each other (private addresses spaces), so any sharing of data requires at least one level of indirection
Threads are separately schedulable units, meaning the OS scheduler decides which runs when. This creates multiple possible interleavings of the operations of the two threads, and thus multiple possible program behaviors.
A single line of C code often compiles to multiple processor instructions (e.g., a read, an add, and a write), creating the possibility that two threads accessing shared data could interfere with each other.
It ensures that only one thread can execute a critical section/access a shared piece of data at a time.
Threads can end up waiting for I/O, so a multithreaded process can have one thread wait for blocking I/O while another makes progress.