CS 332 w22 — Writing Concurrent Software
Table of Contents
1 Shared Object Design
- Shared objects have public/private methods, state variables, and synchronization variables
- Much like standard object-oriented programming, just with added synchronization variables
- Standard OOP approach:
- Decompose problem into objects
- For each object define clean interface and design underlying implementation
- In the multi-threaded case, add new steps:
- Add a lock
- Purpose: enforce mutually exclusive access to object's shared state
- For now, assume one lock per object
- Typically, all of an object's member variables are considered shared state
- Add code to acquire and release the lock
- Simple and common approach: acquire the lock at the start of every public method, release it at the end
- Easy to inspect code, verify lock is held
- Private methods can assume lock is already held
- Resist the slick temptation of "optimizing" by avoiding locking for part of all of some methods
- Have you analyzed program performance (profiled) to determine locking is a bottleneck?
- Do you fully understand possible compiler and architecture instruction re-ordering?
- Acquiring a free lock is cheap, reasoning about memory interleavings is HARD
- Identify and add condition variables
- How to decide what condition variables are needed?
- Consider each method, ask when can this method wait?
- Good option: have a condition variable for each situation where waiting occurs
- You have a lot of freedom to choose number of CVs and what each represents
- Example: bounded blocking queue had two CVs:
item_addedanditem_removed- Could have done it with a single
something_changedCV—what's the disadvantage?
- Could have done it with a single
- Always wait within a loop!
- Protect against state changes between signal and scheduling; spurious wakeups
- Improves modularity—loop condition shows when method proceeds without seeing other code
- Add a lock
- Add loops to wait using the condition variables
- Add signal and broadcast calls
- Use signal when
- at most one waiting thread can make progress
- any thread waiting on the condition variable can make progress
- Use broadcast when
- multiple waiting threads may all be able to make progress
- different threads are using the same condition variable to wait for different situations, so some of the waiting threads can make progress, but other cannot
- Use signal when
- Add signal and broadcast calls
2 Six Best Practices
- Follow a consistent structure
- Helps you and future yous
- Always synchronize with locks and condition variables
- Better than semaphores—self documenting
- Always acquire the lock at the beginning of a method and release it at the end
- Break off code requiring synchronization into separate methods
- Always hold the lock when operating on a condition variable
- Always wait in a while loop
- (Almost) never use
thread_sleep- Suspends calling thread for a specified period of time (then it returns to the ready queue)
- In most cases you should use a condition variable to wait
3 What if a lock is a bottleneck?
- Last time we examined more complex kinds of locks as a potential solution
- But we could also approach this problem by changing the way we use a standard mutual exclusion lock
- Your system works (you followed the rules!), but it's slow
- Performance measurements have identified lock contention as a significant issue
- Four design patterns to consider:
- Fine-grained locking
- Per-processor data structures
- Ownership design pattern
- Staged architecture
3.1 Fine-grained locking
Replace a single lock with many locks, each protecting part of the state. The OSTEP reading goes through several applications of this technique. It touches briefly on the idea of a concurrent hash table.
- Consider a web server that caches recently accessed pages in a hash table
- Lock acquired and released at start and end of
put(key, value),value = get(key), andvalue = remove(key) - With many concurrent requests, single lock limits performance
- Lock acquired and released at start and end of
- Instead, one lock per hash bucket within the hash table
- Now, many threads can access in parallel
- What about resizing the table? Involves accessing many buckets
- Solutions:
- Reader-writer lock on the overall hash table structure (# of buckets, array of buckets)
- Resizing method must acquire the lock for every bucket
- Divide the hash key space into regions that can be resized independently, assign locks to those instead of buckets
How might you use fine-grained locking to reduce contention for the lock protecting the shared memory heap in malloc and free?1
3.2 Per-processor data structures
Partition the data among available processors.
- Split the hash table for our web server cache into N separate tables, where N is the number of processors
- Each table still needs its own lock
- Lock contention decreased, cache performance increased
- If we end up needing to communicate a lot of data between processors, performance could suffer
- Could this same strategy be used for a shared memory heap?
- Yes, a separate heap region for each processor
- Caveats: rebalancing heaps needs to be rare, most allocated data freed by thread that acquires it
3.3 Ownership design pattern
One thread per object—no locks needed. Can be seen as an extension of the pre-processor data structure approach.
- Once a thread removes an object from a container, it has exclusive access to that object
- Making a lock for that object unnecessary
- Example: a web page contains multiple objects (HTML frames, images, etc.)
- Multi-threaded web browser processes pages in three stages
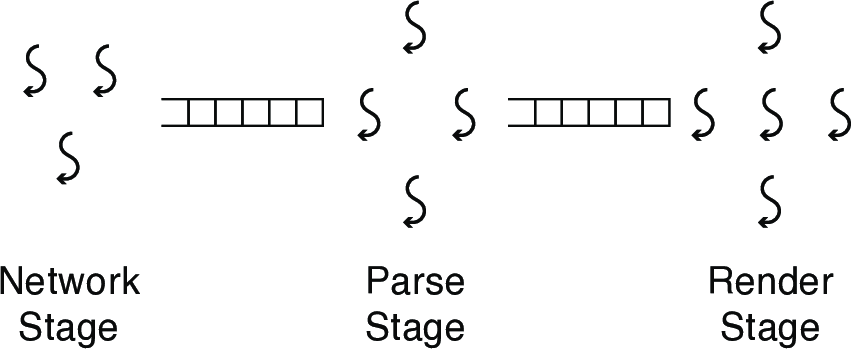
- One thread per network connection, per object being parsed/rendered
- Can this be applied to the heap?
- One heap per thread
3.4 Staged architecture pattern
Divide the system into multiple subsystems, each with its own pool of threads. This is a similar idea to the ownership pattern, but with the design focused on the stages (subsystems) rather than one thread per object.
- Stages connected via producer/consumer queues
- Each worker thread pulls from incoming queues, possibly adding to outgoing queues after processing
- Advantages include modularity and cache locality
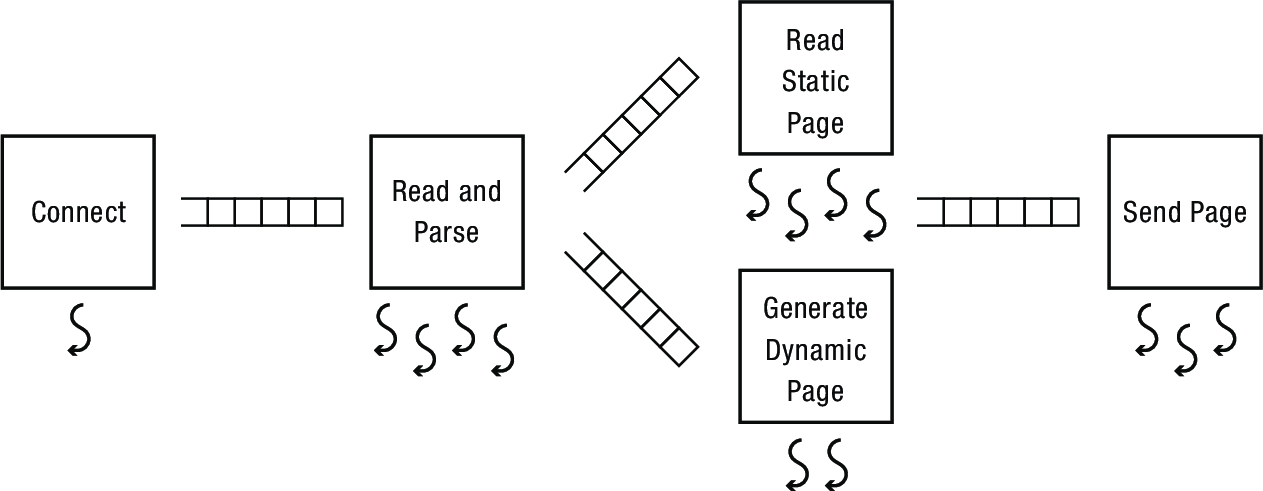
- Disadvantages: one stage can become a bottleneck, queues can fill
- Dynamically vary threads per stage to maximize throughput
4 Reading: Concurrent Data Structures
Read OSTEP chapter 29, (p. 353-366). It walks through C implementations of several concurrent data structures and measures their performance.
Footnotes:
One approach: partition the heap into separate regions, each with its own lock