Homework 1: SQL
- Assigned: Friday, April 2
- Due: 9pm Monday, April 12
- Collaboration: Individual assignment
Overview
For this homework you will construct a set of SQL queries to analyze the MusicBrainz dataset. This homework is an opportunity to: (1) learn basic and certain advanced SQL features, and (2) get familiar with using a full-featured DBMS, SQLite, that can be useful for you in the future. You can expect to spend 6 ot 8 hours on this homework.
Setup Instructions
Setting up SQLite
Make sure that you are using at least SQLite version 3.25! Older releases (prior to 2019) will not support the SQL features that you need to complete this assignment.
SQLite should come pre-installed on both MacOS and Linux (including WSL). Unfortunately, the version of SQLite that apt installs on Ubuntu 18.04 is too old for our purposes, so if you’re working on Ubuntu 18, you’ll need to manually download a more recent version of SQLite. SQLite can be invoked on the command line using the command sqlite3. There’s also a graphical interface if you’d prefer that.
Check that SQLite is working by doing step 1 of this tutorial.
Acquiring the Database
Download the database file:
$ wget https://cs.carleton.edu/faculty/awb/cs334/s21/musicbrainz-cs334-s21.db.gzCheck its MD5 checksum to ensure that you have correctly downloaded the file:
$ md5sum musicbrainz-cs334-s21.db.gz
0454990e4484e77e0c608fa086aa7dc7 musicbrainz-cs334-s21.db.gzUnzip the database from the provided database by running the following command in your terminal. Note that the database file be 550MB after you decompress it.
$ gunzip musicbrainz-cs334-s21.db.gzThe resulting .db file is a sample of the original dataset created for this assignment. Although this is not required to complete the assignment, the complete dataset is available by following the steps here.
Check the contents of the database by running the .tables command on the sqlite3 terminal. You should see fifteen tables, and the output should look like this:
$ sqlite3 musicbrainz-cs334-s21.db
SQLite version 3.32.3
Enter ".help" for usage hints.
sqlite> .tables
area artist_credit_name medium release_status
artist artist_type medium_format work
artist_alias gender release work_type
artist_credit language release_info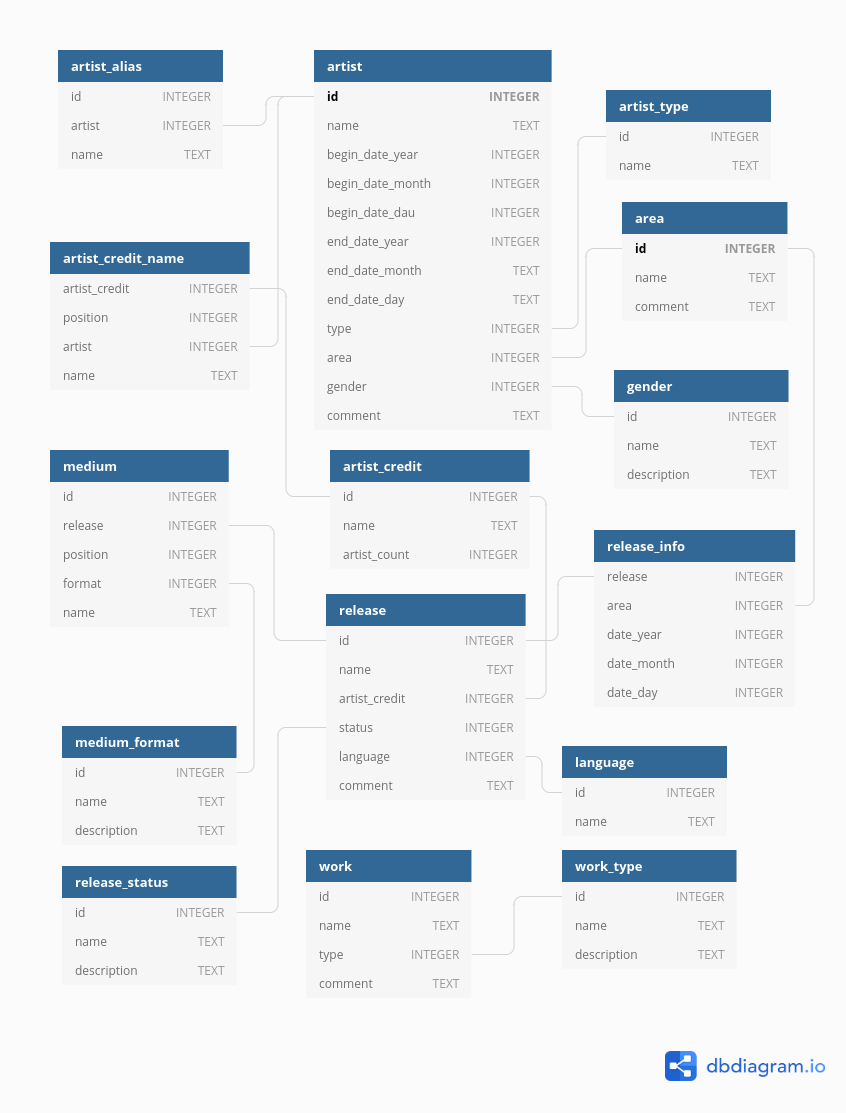
Finally, create indices using the following commands in SQLite: (we’ll talk about indices later in the term, for now just know their purpose is to speed up queries related to the attributes we’re indexing)
CREATE INDEX ix_artist_name ON artist (name);
CREATE INDEX ix_artist_area ON artist (area);
CREATE INDEX ix_artist_credit_name ON artist_credit_name (artist_credit);
CREATE INDEX ix_artist_credit_id ON artist_credit (id);
CREATE INDEX ix_artist_alias ON artist_alias(artist);
CREATE INDEX ix_work_name ON work (name);
CREATE INDEX ix_work_type ON work (type);
CREATE INDEX ix_work_type_name ON work_type (name);
CREATE INDEX ix_release_id ON release (id);
CREATE INDEX ix_release_artist_credit ON release (artist_credit);
CREATE INDEX ix_release_info_release ON release_info (release);
CREATE INDEX ix_medium_release ON medium (release);
CREATE INDEX ix_medium_format_id on medium_format (id);SQL Queries
Now you’re ready to start working on the SQL queries. Write each one in its own file with the indicated name.
You can create a hw1 directory and an empty placeholder file for each query inside it with these terminal commands:
$ mkdir hw1
$ cd hw1
$ touch q1_sample.sql \
q2_long_name.sql \
q3_old_music_nations.sql \
q4_dubbed_smash.sql \
q5_vinyl_lover.sql \
q6_old_is_not_gold.sql \
q7_release_percentage.sql \
q8_collaborate_artist.sql \
q9_dre_and_eminem.sql \
q10_around_the_world.sqlq1_sample.sql
The purpose of this query is to make sure that the formatting of your output matches exactly the formatting of the auto-grading script. Details: List all types of work ordered by type ascendingly.
Here’s the correct SQL query and expected output:
sqlite> select name from work_type order by name;
Aria
Audio drama
Ballet
Beijing opera
Cantata
Concerto
Incidental music
Madrigal
Mass
Motet
Musical
Opera
Operetta
Oratorio
Overture
Partita
Play
Poem
Prose
Quartet
Sonata
Song
Song-cycle
Soundtrack
Suite
Symphonic poem
Symphony
Zarzuela
Étudeq2_long_name.sql
List works with longest name of each type.
Details: For each work type, find works that have the longest names. There might be cases where there is a tie for the longest names—in that case, return all of them. Display work names and corresponding type names, and order it according to work type (i.e., work.type) (ascending) and use work name (ascending) as tie-breaker.
Hint: a HAVING clause will probably be useful.
q3_old_music_nations.sql
List top 10 countries with the most classical music artists (born or started before 1850) along with the number of associated artists.
Details: Print country and number of associated arists before 1850. For example, Russia|191. Sort by number of artists in descending order.
q4_dubbed_smash.sql
List the top 10 UK artists with releases under other names along with the number of such aliases.
Details: Count the number of distinct names in artist_alias for each artist in the artist table, and list only the top ten who are from the United Kingdom and started after 1950 (not included). Print the artist name in the artist table and the number of corresponding distinct artist names in the artist_alias table.
q5_vinyl_lover.sql
List the distinct names of releases issued in vinyl format by the British band Coldplay.
Details: Vinyl format includes ALL sizes of vinyl, but excludes all VinylDisc formats. Sort the release names by release date in ascending order.
q6_old_is_not_gold.sql
Which decades saw the most number of official releases? List the number of official releases in every decade since 1900. Like 1970s|57210.
Details: Print all decades and the number of official releases (note the existence of the release_status table and that status is an attribute of the release table). Releases with different issue dates or countries are considered different releases. Print the relevant decade in a fancier format by constructing a string that looks like this: 1970s. Sort the decades in decreasing order with respect to the number of official releases and use decade (descending) as tie-breaker. Make sure to exclude releases whose dates are NULL.
q7_release_percentage.sql
List the month and the percentage of all releases issued in the corresponding month all over the world between July 2019 and July 2020. Display like 2020.01|5.95.
Details: The percentage of releases for a month is the number of releases issued in that month devided by the total releases from 07/2019 to 07/2020, both included. Be aware that values in release_info can be NULL—include all releases with non-NULL date_year and date_month values that fall within the range (i.e., don’t use date_day in your query). Releases with different issue dates or countries are considered different releases. Round the percentage to two decimal places using ROUND(). Sort by dates in ascending order.
q8_collaborate_artist.sql
List the number of artists who have collaborated with Ariana Grande.
Details: Print only the total number of artists. An artist is considered a collaborator if they appear in the same artist_credit with Ariana Grande. The answer should include Ariana Grande herself.
q9_dre_and_eminem.sql
List the rank, artist names, along with the number of collaborative releases of Dr. Dre and Eminem among other most productive duos (as long as they appear in the same release) both started after 1960 (not included). Display like [rank]|Dr. Dre|Eminem|[# of releases].
Details: For example, if you see a release by A, B, and C, it will contribute to three pairs of duos: A|B|1, A|C|1, and B|C|1. You will first need to calculate a rank of these duos by number of collaborated releases (release with artist_credit shared by both artists) sorted descendingly, and then find the rank of Dr. Dre and Eminem. Only releases in English are considered. Both artists should be solo artists (i.e., they have an artist_type of 'Person'). All pairs of names should have the alphabetically smaller one first. Use artist names (ascending) as a tie breaker for the ranking.
Hint: Artist aliases may be used everywhere. When doing aggregation, using artist ids will ensure you get the correct results. One example entry in the rank list is 9|Benj Pasek|Justin Paul|27.
Hint: For this query and the next one, you may find common table expressions to be useful.
q10_around_the_world.sql
Concatenate all aliases of The Beatles using comma-separated values (like “Beetles, fab four”).
Details: Find all aliases of artist “The Beatles” in artist_alias and order them by id (ascending). Print a single string containing all the aliases separated by commas.
Submission
Upload a zip file containing the 10 .sql files below with your solutions to Gradescope.
q1_sample.sqlq2_long_name.sqlq3_old_music_nations.sqlq4_dubbed_smash.sqlq5_vinyl_lover.sqlq6_old_is_not_gold.sqlq7_release_percentage.sqlq8_collaborate_artist.sqlq9_dre_and_eminem.sqlq10_around_the_world.sql
Assuming these .sql files are in a directory called hw1, you can run this command from the parent directory to produce a correctly-organized zip file to upload to Gradescope:
$ zip -j submission.zip hw1/*.sqlThe autograder will give you immediate feedback on your solutions by comparing the output they generate with the expected output. Your files need to have these exact names and be in the top-level directory of the zip for the autograder to work. Feedback is displayed in diff format with your submission’s output as the first file. For your queries, the order of the output columns is important; their names are not. You can submit your answers as many times as you like.
Grading
This lab will be graded out of 50 points, with each of the 10 queries worth 5 points. While the autograder will assign 0 points for a query that doesn’t generate the expected output, partial credit can be earned for evidence of a good-faith effort. Comments explaining your approach can help earn partial credit (a comment line in SQL begins with two hyphens: --).