Database Storage Practice Problems
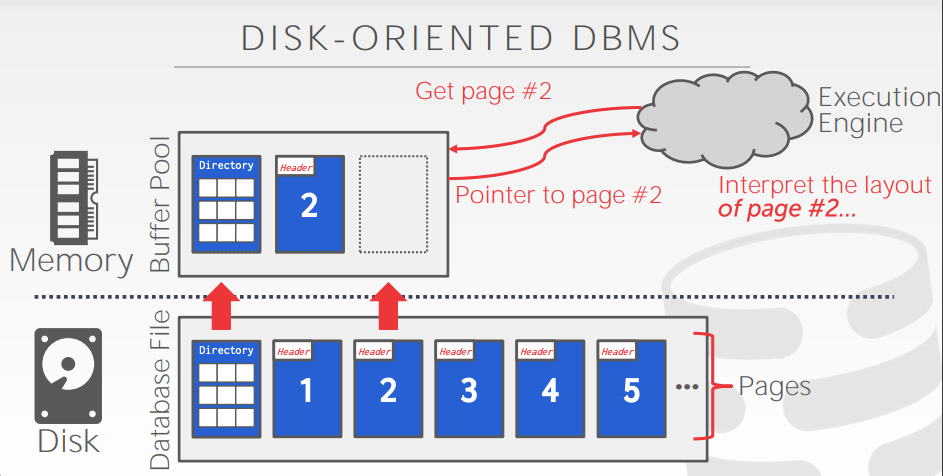
- Consider a bitmap representation of the available free space in pages on disk. For each page, two bits are maintained in the bitmap. If the page is between 0 and 30 percent full the bits are 00, between 30 and 60 percent the bits are 01, between 60 and 90 percent the bits are 10, and above 90 percent the bits are 11. Such bitmaps can be kept in memory even for quite large files.1
- Outline two benefits and one drawback to using two bits per page compared to using one byte per page in the bitmap.
- Describe how you might keep the bitmap up to date on record insertions and deletions.
- Outline the benefit of the bitmap technique over free lists (i.e., linked lists of free pages) in searching for free space and in updating free space information.
- PostgreSQL normally uses a small buffer pool, leaving it to the operating system virtual memory manager to manage the rest of main memory available for file system buffering. Explain (a) what is the benefit of this approach, and (b) one key limitation of this approach.2
- Why does grouping tuples into pages significantly affect database system performance?3
- Explain the tradeoff between the
FLOATdatatype and theNUMERICdatatype4 - Consider the partial schema below for a database of Wikipedia pages and users5
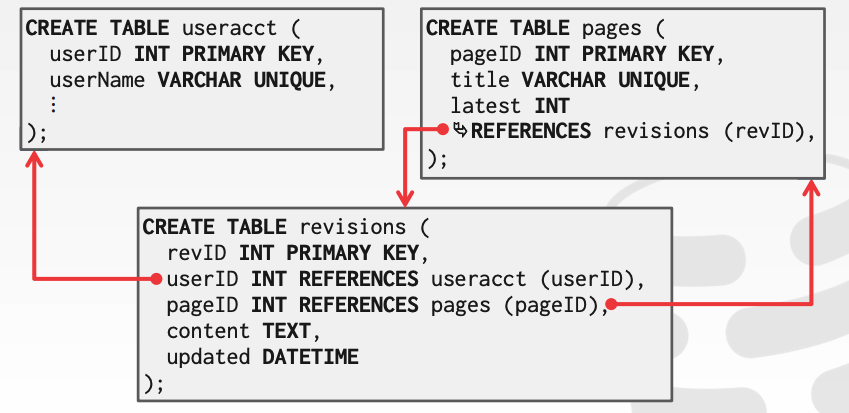
- Would a row-store database or a column-store databse be more appropriate for the following queries (i.e., are these OLTP or OLAP queries): (the red ? indicate places were specific values would be filled in)

- What about this query?

- Would a row-store database or a column-store databse be more appropriate for the following queries (i.e., are these OLTP or OLAP queries): (the red ? indicate places were specific values would be filled in)
Footnotes:
- The space used is less with 2 bits, and the number of times the freespace map needs to be updated decreases significantly, since many inserts/deletes do not result in any change in the free-spae map. However, we have only an approximate idea of the free space available, which could lead both to wasted space and/or to increased search cost for finding free space for a tuple.
- Every time a reord is inserted/deleted, check if the usage of the page has changed levels. In that case, update the corresponding bits. Note that we don't need to access the bitmaps at all unless the usage crosses a boundary, so in most of the cases there is no overhead.
- When free space for a large tuple or a set of tuples is sought, then multiple free list entries may have to be scanned before a proper-sized one is found, so overheads are much higher. With bitmaps, one page of the bitmap can store free info for many pages, so I/O spent for finding free space is minimal. Similarly, when a whole page or a large part of it is deleted, the bitmap technique is more convenient for updating free space information.
The database system does not know what are the memory demands from other proccesses. By using a small buffer pool, PostgreSQL ensures that it does not grab too much of main memory. But at the same time, even if a page is evicted from the buffer, if the OS file system manager has enough memory allocated to it, the evicted page is likely to still be cached in the file system buffer. Thus, a database buffer pool miss is often not very expensive since the page is still in the file system buffer. The drawback of this approach is that the database system may not be able to control the file system buffer replacement poliy. Thus, the operating system may make suboptimal decisions on what to evict from the file system buffer.
If we group related tuples into pages, we can often retrieve most, or all, of the requested tuples by a query with one sequential disk read. Disk accesses tend to be the bottlenecks in databases; since this storage strategy reduces the number of disk accesses for a given operation, it significantly improves performance.
The variable-precision datatype (FLOAT) will have better performance, as the CPU has didicated instructions for operating on IEEE-754 representations. It will, however, suffer from rounding errors. The fixed-precision datatype (NUMERIC) will provide an exact representation (no rounding errors), but result in slower performance.
- A row-store would be appropriate for these queries, as they reflect an OLTP workload. Each one pertains to a individual update or read (get the information for the lastest revisions of a specific page; update the last login for a specific user; insert a new revision).
- A column-store would be appropriate for this query. It only uses to two attributes (lastLogin and hostname) across a wide swath of tuples, and only reads the data. A row-store database would need to bring in a bunch of unnecessary data into memory to answer this query.