Project 3: Query Execution
- Assigned: Friday, May 21
- Due: 9pm Wednesday, June 2
- Collaboration: This assignment can be done in pairs or individually. I will assume the same collaboration as Project 2 unless you tell me otherwise.
Overview
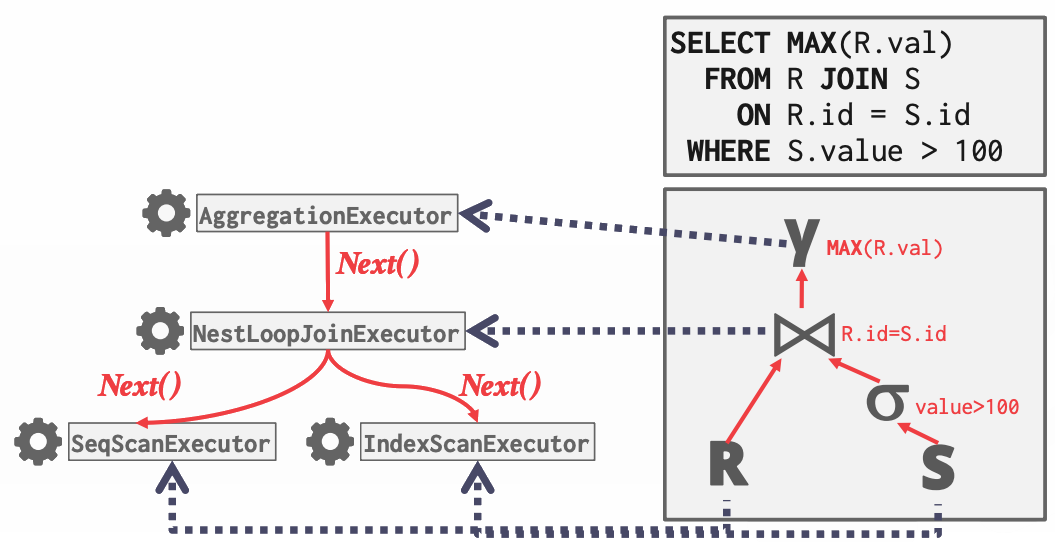
The third programming project is to add support for executing queries in your database system. You will implement executors that are responsible for taking query plan nodes and executing them. You will create executors that perform the following operations:
- Access Methods: Sequential Scans
- Modifications: Inserts
- Miscellaneous: Nested Loop Joins and Aggregation
Because the DBMS does not support SQL (yet), your implementation will operate directly on hand-written query plans. We will use the Iterator query processing model (i.e., the Volcano model). Every query plan executor implements a Next function. When the DBMS invokes an executor’s Next function, the executor produces either (1) a single tuple (and returns true) or (2) returns false to indicate that there are no more tuples. With this approach, each executor implements a loop that keeps calling Next on its children to retrieve tuples and then process them one-by-one.
As optional reading, you may be interested in following a select statement through the PostgreSQL internals.
The project is comprised of the following tasks:
- Task #1 — System Catalog
- Task #2 — Executors
The Moodle forums are a great place to post questions!
Pre-Lab Activities
We will go over how to get started on this project in lab on May 21. Before lab, you are expected to
Pull the latest changes from the public repo (the first command will say the remote already exists if you ran it previously, this is fine)
$ git remote add public https://github.com/awb-carleton/bustub.git $ git pull public masterRead this entire project writeup
Lab
Note: further small changes to the public repo were made May 21, so make sure to pull before you start working.
System Catalog Advice
In a real system, we would want to use the buffer pool manager to make the catalog persistent on disk. For this project, we’ll simplify things by storing the catalog in memory on the heap. This means we’ll use new to allocate catalog data structures. The data structure that concerns us is the metadata about the tables in the database:
/**
* Metadata about a table.
*/
struct TableMetadata {
TableMetadata(Schema schema, std::string name, std::unique_ptr<TableHeap> table, table_oid_t oid)
: schema_(std::move(schema)), name_(std::move(name)), table_(std::move(table)), oid_(oid) {}
Schema schema_;
std::string name_;
std::unique_ptr<TableHeap> table_;
table_oid_t oid_;
};Note that we have a pointer to a TableHeap inside our TableMetadata. A TableHeap is an object that keeps track of the pages for a particular table and manipulate and retrieve the tuples inside them. We can look at src/include/storage/table/table_heap.h to learn about the relevant methods:
/**
* Create a table heap with a transaction. (create table)
* @param buffer_pool_manager the buffer pool manager
* @param lock_manager the lock manager
* @param log_manager the log manager
* @param txn the creating transaction
*/
TableHeap(BufferPoolManager *buffer_pool_manager, LockManager *lock_manager, LogManager *log_manager,
Transaction *txn);
/**
* Insert a tuple into the table. If the tuple is too large (>= page_size), return false.
* @param tuple tuple to insert
* @param[out] rid the rid of the inserted tuple
* @param txn the transaction performing the insert
* @return true iff the insert is successful
*/
bool InsertTuple(const Tuple &tuple, RID *rid, Transaction *txn);
/**
* Read a tuple from the table.
* @param rid rid of the tuple to read
* @param[out] tuple output variable for the tuple
* @param txn transaction performing the read
* @return true if the read was successful (i.e. the tuple exists)
*/
bool GetTuple(const RID &rid, Tuple *tuple, Transaction *txn);
/** @return the begin iterator of this table */
TableIterator Begin(Transaction *txn);
/** @return the end iterator of this table */
TableIterator End();So, when we need to create a new table in the Catalog’s CreateTable method, we’d use the above constructor like
TableHeap *new_table = new TableHeap(bpm_, lock_manager_, log_manager_, txn);Where bpm_, lock_manager_, and log_manager_ are fields of the Catalog class, and txn is a parameter of the CreateTable method. You’d construct TableMetadata similarly. To create a std::unique_ptr from new_table, we would do std::unique_ptr<TableHeap>(new_table).
Note that InsertTuple takes a RID *rid, which it updates with the appropriate RID based on where tuple is inserted. Conversely, GetTuple takes an RID and updates the output parameter Tuple *tuple with the tuple corresponding to that RID.
This would also be a good time to take stock of the other fields of the Catalog class:
/** tables_ : table identifiers -> table metadata. Note that tables_ owns all table metadata. */
std::unordered_map<table_oid_t, std::unique_ptr<TableMetadata>> tables_;
/** names_ : table names -> table identifiers */
std::unordered_map<std::string, table_oid_t> names_;
/** The next table identifier to be used. */
std::atomic<table_oid_t> next_table_oid_{0};
/** indexes_: index identifiers -> index metadata. Note that indexes_ owns all index metadata */
std::unordered_map<index_oid_t, std::unique_ptr<IndexInfo>> indexes_;
/** index_names_: table name -> index names -> index identifiers */
std::unordered_map<std::string, std::unordered_map<std::string, index_oid_t>> index_names_;
/** The next index identifier to be used */
std::atomic<index_oid_t> next_index_oid_{0};The first two are std::unordered_maps that you’ll use to keep track of the TableMetadata you create for new tables. The std::atomic<table_oid_t> next_table_oid_{0}; is a table_oid_t (which is just an integer underneath) that starts at 0 with one important feature provided by std::atomic: it is thread safe! std::atomic can ensure thread-safe access to any of the fundamental integral types. You can use next_table_oid just like you would any other integer variable (e.g., next_table_oid++). You are not required to make the Catalog thread-safe as a whole, so this use of std::atomic is primarily to demonstrate this useful C++ feature.
Executors Advice
None of the query operators you will implement are algorithmically complex, so the main challenge is integrating them with the Bustub architecture. This means figuring out how to get the data and methods you need from the available objects.
All the executors take a pointer to a corresponding plan object in their constructors. You will want to add a private field and store this pointer there. This first thing to do when implementing an executor is to take a look at the plan to see what data it stores. For example, the SeqScanPlanNode (src/include/execution/plans/seq_scan_plan.h) provides these two methods:
/** @return the predicate to test tuples against; tuples should only be returned if they evaluate to true */
const AbstractExpression *GetPredicate() const { return predicate_; }
/** @return the identifier of the table that should be scanned */
table_oid_t GetTableOid() const { return table_oid_; }So we can get the table_oid_t for the table we are scanning, but how do we get access to the table itself? Well, we’re implementing a GetTable method in the Catalog, so if we had access to the catalog, we could access the table. Every executor takes in an ExecutorContext*, which stores the necessary context (i.e., internal database objects) to run an executor. That includes the catalog, so getting the TableMetadata for the table we’re scanning looks like this:
exec_ctx_->GetCatalog()->GetTable(plan_->GetTableOid())With this we can get the table’s Schema, as well as access the TableHeap and its iterator.
Schemas
Speaking of schemas, it’s time to get specific about what that is. A Schema object (src/include/catalog/schema.h) defines the structure of particular tuples (or keys in the case of indexes). This includes the number of columns, the datatype of each of those columns (via Column objects), and the length of the tuple in bytes. Each table in the database has an associated schema.
Each executor has an output schema that defines the structure of tuples output by the executor (i.e., produced by its Next method). They all define a GetOutputSchema method that returns a pointer to this Schema. Each executor will also have access to a schema for each of its input/child executors. Scans, inserts, and aggregations will have a single input, while a join will have two. Methods that take a Tuple often also take a Schema* because they need to have access to information about the structure of the tuple. When using these methods, you will need to make sure to pass in a pointer to the appropriate schema (i.e., if the tuple is being output by Next, use the output schema; if the tuple is coming from a table or child executor, use the schema for that).
Next and Init
Every executor will use Next to produce tuples. I say produce rather than return, because the Next method returns true or false to indicate whether there more tuples left to process. Next uses the output parameter Tuple *tuple to store the tuple produced by that call to Next. For executors that produce existing tuples that are stored on disk (e.g., sequential scan), the RID *rid parameter should also be updated (tuples created by aggregations or joins don’t have a record ID until and unless they are inserted into a table).
The ExecutionEngine calls Init once before calling Next in a loop. For some executors you may want to perform one-time setup/initialization in Init, but other will not use it at all.
Project Specification
Like the previous projects, we are providing you with stub classes that contain the API that you need to implement. You should not modify the signatures for the pre-defined functions in ExecutionEngine class. If you do this, then it will break the test code that we will use to grade your assignment. If a class already contains certain member variables, you should not remove them. You may however add helper functions and member variables to these classes.
You will need a working BufferPoolManager for this project. To attempt the Extra Credit, you will need a BPlusTree that supports insertion with splitting and simple deletion, as well as a working IndexIterator.
System Catalog
A database maintains an internal catalog to keep track of meta-data about the database. For example, the catalog is used to answer what tables are present and where.
In this warm-up task, you will be modifying src/include/catalog/catalog.h to that allow the DBMS to add new tables to the database and retrieve them using either the name or internal object identifier (table_oid_t). You will implement the following methods:
CreateTable(Transaction *txn, const std::string &table_name, const Schema &schema)GetTable(const std::string &table_name)GetTable(table_oid_t table_oid)
This first task is meant to be straightforward to complete. The goal is to familiarize yourself with the catalog and how it interacts with the rest of the system. CreateTableTest in test/catalog/catalog_test.cpp tests these methods.
Executors
In the second task, you will implement executors for sequential scans, inserts, nested loop joins, and aggregations. For each query plan operator type, there is a corresponding executor object that implements the Init and Next methods. The Init method is for setting up internal state about the invocation of the operator (e.g., retrieving the corresponding table to scan). The Next method provides the iterator interface that produces a tuple and corresponding RID on each invocation (returning false if there are no more tuples).
The executors that you will implement are defined in the following header files:
src/include/execution/executors/seq_scan_executor.hsrc/include/execution/executors/insert_executor.hsrc/include/execution/executors/nested_loop_join_executor.hsrc/include/execution/executors/aggregation_executor.h
The associated .cpp files can be found in src/execution.
Each executor is responsible for processing a single plan node type. They accept tuples from their children and give tuples to their parent. They may rely on conventions about the ordering of their children, which we describe below. We also assume executors are single-threaded throughout the entire project. You are also free to add private helper functions and class members as you see fit.
We provide the ExecutionEngine (src/include/execution/execution_engine.h) helper class. It converts the input query plan to a query executor, and executes it until all results have been gathered.
To understand how the executors are created at runtime during query execution, refer to the ExecutorFactory (src/include/execution/executor_factory.h) helper class. Moreover, every executor has an ExecutorContext (src/include/execution/executor_context.h) that maintains additional state about the query.
We have provided tests in test/execution/executor_test.cpp.
Sequential Scan
The sequential scan executor iterates over a table and return its tuples one-at-a-time. A sequential scan is specified by a SeqScanPlanNode. The plan node specifies which table to iterate over. The plan node may also contain a predicate; if a tuple does not satisfy the predicate, it is skipped over.
Be careful when using the TableIterator object. You may find yourself getting strange output by switching between ++iter and iter++, so make sure you are consistent.
You will want to make use of the predicate in the sequential scan plan node. In particular, take a look at AbstractExpression::Evaluate. Note that this returns a Value, which you can GetAs<bool>.
The ouput of sequential scan should be a copy of matched tuple and its record ID.
Insert
This executor inserts tuples into a table. There are two types of inserts. The first are inserts where the values to be inserted are embedded directly inside the plan node itself (called raw inserts). The other are inserts that take the values to be inserted from a child executor. For example, you could have an InsertPlanNode whose child was a SeqScanPlanNode to copy one table into another. Use the IsRawInsert() method of the InsertPlanNode to determine what type of insert is being executed.
You will want to look up table information during executor construction. One the first call to Next, the executor should insert all the tuples and return false to indicate no more calls to Next are necessary.
Nested Loop Join
This executor implements a basic nested loop join that combines the tuples from its two child executors together.
You will want to make use of the predicate in the nested loop join plan node. In particular, take a look at AbstractExpression::EvaluateJoin, which handles the left tuple and right tuple and their respective schemas. Note that this returns a Value, which you can GetAs<bool>.
One implementation approach would be to use the Init method to perform the entire join and store the resulting tuples in buffer (i.e., a std::vector field). Next would then return tuples from the buffer one at a time.
When joining two tuples, you will need to manually construct the combined tuple. The Tuple class has a constructor Tuple(std::vector<Value> values, const Schema *schema) you can use for this purpose. Use the output schemas from the child executors (e.g., plan_->GetLeftPlan()->OutputSchema()) and Tuple’s GetValue(const Schema *schema, uint32_t column_idx) to exact Values from tuples and generate a vector for the combined tuple. Use the output schema of the nested loop join (GetOutputSchema()) when constructing the combined tuple.
Aggregation
This executor combines multiple tuple results from a single child executor into a single tuple. In this project, we ask you to implement COUNT, SUM, MIN, and MAX. We provide you with a SimpleAggregationHashTable that has all the necessary functionality for aggregations (defined in src/include/executors/aggregation_executor.h). You will construct a SimpleAggregationHashTable in the constructor or Init. You will use the InsertCombine method to insert keys and combine them with the current aggregation. To generate the arguments for InsertCombine, use the MakeKey and MakeVal methods defined in src/include/executors/aggregation_executor.h.
You will also need to implement GROUP BY with a HAVING clause. We provide you with a SimpleAggregationHashTable Iterator that can iterate through the hash table.
You will want to aggregate the results and make use of the HAVING for constraints. In particular, take a look at AbstractExpression::EvaluateAggregate, which handles aggregation evaluation for different types of expressions. Note that this returns a Value, which you can GetAs<bool>. The for a hash table iterator itr, use itr.Key().group_bys_ to get a vector of group by Values and itr.Val().aggregates_ to get a vector of aggregate Values.
Extra Credit
For extra credit, you can implement Catalog methods and executors related to indexes (i.e., B+ Trees). See Grading for specifics on extra credit grading.
First, you will need to support adding indexes to the catalog. Similar to table_oid_t, index_oid_t is the unique object identifier for an index. You will implement the following methods:
CreateIndex(txn, index_name, table_name, schema, key_schema key_attrs, keysize)GetIndex(const std::string &index_name, const std::string &table_name)GetIndex(index_oid_t index_oid)GetTableIndexes(const std::string &table_name)
CreateIndexTest in test/catalog/catalog_test.cpp tests these methods.
Next, modify your InsertExecutor to also insert entries into any indexes the table has. Finally, implement the two new executors described below. There are tests for an insert involving an index and both of these new executors in test/execution/executor_test.cpp.
If you want to go truly above and beyond, you can implement update, limit, and nested loop index join along with an associated test for each. Email me to let me know if you attempt this.
Index Scan
Index scans iterate over an index to get tuple RIDs. These RIDs are used to look up tuples in the table corresponding to the index. Finally these tuples are returned one-at-a-time. An index scan is specified by a IndexScanPlanNode. The plan node specifies which index to iterate over. The plan node may also contain a predicate; if a tuple does not satisfy the predicate, it is skipped over.
Make sure to retrieve the tuple from the table once the RID is retrieved from the index. Remember to use the catalog to look up the table.
You will want to make use of the iterator of your B+ tree to support both point query and range scan. (Use a reinterpret_cast to convert an Index* to a BPlusTreeIndex*.)
For this project, you can safely assume the key value type for index is <GenericKey<4>, RID, GenericComparator<4>>.
Delete
Delete removes tuples from tables and removes their entries from any associated indexes. The child executor will provide the tuples (with their RID) that the update executor will modify.
Get an RID from the child executor and call MarkDelete (src/include/storage/table/table_heap.h) to make it invisible. The deletes will be applied when the transaction commits.
Testing
You can test the individual components of this assignment using our testing framework. We use GTest for unit test cases. All of the tests the autograder will run on your submission can be found in test/catalog/catalog_test.cpp and test/execution/executor_test.cpp.
Your code will also be evaluated for memory errors. These include problems such as array overflows and failing to deallocate memory. We will use the command
$ valgrind --leak-check=full --suppressions=../build_support/valgrind.supp ./test/executor_test --gtest_filter=ExecutorTest.SimpleSeqScanTest:ExecutorTest.SimpleSelectInsertTestto check for these errors (run from the build directory). See this guide for information about interpreting valgrind output.
valgrind and Debug mode
Configuring the project in Debug mode (either with cmake -DCMAKE_BUILD_TYPE=Debug .. or in VS Code) will interfere with valgrind. So when you go to check your code for memory errors, you will need to reconfigure and rebuild the project without Debug mode. In VS Code this should only require changing build variants and rebuilding. Via command line, you may need to remove the build directory and rebuild from scratch.
Logging
Instead of using printf statements for debugging, use the LOG_* macros for logging information like this:
LOG_INFO("# Pages: %d", num_pages);
LOG_DEBUG("Fetching page %d", page_id);To enable logging in your project, you will need to reconfigure it like this (or select a build variant with debug info in VS Code):
$ mkdir build
$ cd build
$ cmake -DCMAKE_BUILD_TYPE=DEBUG ..
$ makeThe different logging levels are defined in src/include/common/logger.h. After enabling logging, the logging level defaults to LOG_LEVEL_INFO. Any logging method with a level that is equal to or higher than LOG_LEVEL_INFO (e.g., LOG_INFO, LOG_WARN, LOG_ERROR) will emit logging information. Note that you will need to add #include "common/logger.h" to any file that you want to use the logging infrastructure.
Style
Your code must follow the Google C++ Style Guide. We use clang to automatically check the quality of your source code. The style part of project grade will be zero if your submission fails any of these checks.
Execute the following commands to check your syntax. The format target will automatically correct the formatting of your code. The check-lint and check-clang-tidy targets will print errors and instruct you how to fix it to conform to our style guide.
$ make format
$ make check-lint
$ make check-clang-tidySubmission
You will submit your work for this project via Gradescope.
Gradescope lets you submit via GitHub, which is probably the easiest method. All you’ll need to do is connect your GitHub account (the Gradescope submission page has a button for this) and select the repository and branch you wish to submit. Alternatively, you can create a zip file of the src directory and upload that.
When you submit, the autograder will compile your code, run the test cases, check your code for style, and use valgrind to check for memory errors. It will use the following files (all other submitted files will be discarded):
Your Project 1 files:
src/include/buffer/lru_replacer.hsrc/buffer/lru_replacer.cppsrc/include/buffer/buffer_pool_manager.hsrc/buffer/buffer_pool_manager.cpp
as well as
src/include/catalog/catalog.hsrc/include/execution/executors/seq_scan_executor.hsrc/include/execution/executors/insert_executor.hsrc/include/execution/executors/nested_loop_join_executor.hsrc/include/execution/executors/aggregation_executor.hsrc/execution/seq_scan_executor.cppsrc/execution/insert_executor.cppsrc/execution/nested_loop_join_executor.cppsrc/execution/aggregation_executor.cpp
For the extra-credit tests only, it will also use:
src/include/execution/executors/index_scan_executor.hsrc/include/execution/executors/delete_executor.hsrc/execution/index_scan_executor.cppsrc/execution/delete_executor.cppsrc/include/storage/page/b_plus_tree_internal_page.hsrc/storage/page/b_plus_tree_internal_page.cppsrc/include/storage/page/b_plus_tree_leaf_page.hsrc/storage/page/b_plus_tree_leaf_page.cppsrc/include/storage/index/b_plus_tree.hsrc/storage/index/b_plus_tree.cppsrc/include/storage/index/index_iterator.hsrc/storage/index/index_iterator.cpp
These files must be at the given locations in your submission.
Although you are allowed submit your answers as many times as you like, you should not treat Gradescope as your only debugging tool. Many people may submit their projects near the deadline, and thus it will Gradescope take longer to process the requests. You may not get feedback in a timely manner to help you debug problems.
Grading
This project will be graded out of 150 points, as shown in the table below. No tests will be run for a submission that does not compile. While the autograder will assign 0 points for a test that doesn’t pass, partial credit can be earned for evidence of a good-faith effort. Comments explaining your approach can help earn partial credit. The four tests that involve index operations are each worth 1 extra credit point.
| Test | Points |
|---|---|
CatalogTest.CreateTableTest |
20 points |
ExectuorTest.SimpleSeqScanTest |
20 points |
ExecutorTest.SimpleRawInsertTest |
20 points |
ExecutorTest.SimpleSelectInsertTest |
20 points |
ExecutorTest.SimpleNestedLoopJoinTest |
20 points |
ExecutorTest.SimpleAggregationTest |
10 points |
ExecutorTest.SimpleGroupByAggregation |
10 points |
| No style problems | 15 points |
No valgrind errors |
15 points |
(extra credit) CatalogTest.CreateIndexTest |
1 point |
(extra credit) ExecutorTest.SimpleIndexScanTest |
1 point |
(extra credit) ExecutorTest.SimpleRawInsertWithIndexTest |
1 point |
(extra credit) ExecutorTest.SimpleDeleteTest |
1 point |