CS 208 s20 — Caching: Associativity and Lookup
Table of Contents
1 Video
Here is a video lecture for the material outlined below. It covers CSPP sections 6.4.2 to 6.4.4 (p. 617–627). It contains sections on
- Louie, Louie (0:05)
- warmup (1:35)
- associativity (5:32)
- associativity example (12:16)
- placement policy (17:45)
- cache organization (21:02)
- cache parameters (28:58)
- direct-mapped lookup example (32:01)
- 2-way associative lookup example (38:44)
- fully associative lookup (41:37)
- lab 4 advice (44:02)
- homework (49:57)
The Panopto viewer has table of contents entries for these sections. Link to the Panopto viewer: https://carleton.hosted.panopto.com/Panopto/Pages/Viewer.aspx?id=bb7ba5e8-b51b-4de1-9dd7-abc300f7fd56
2 Warmup
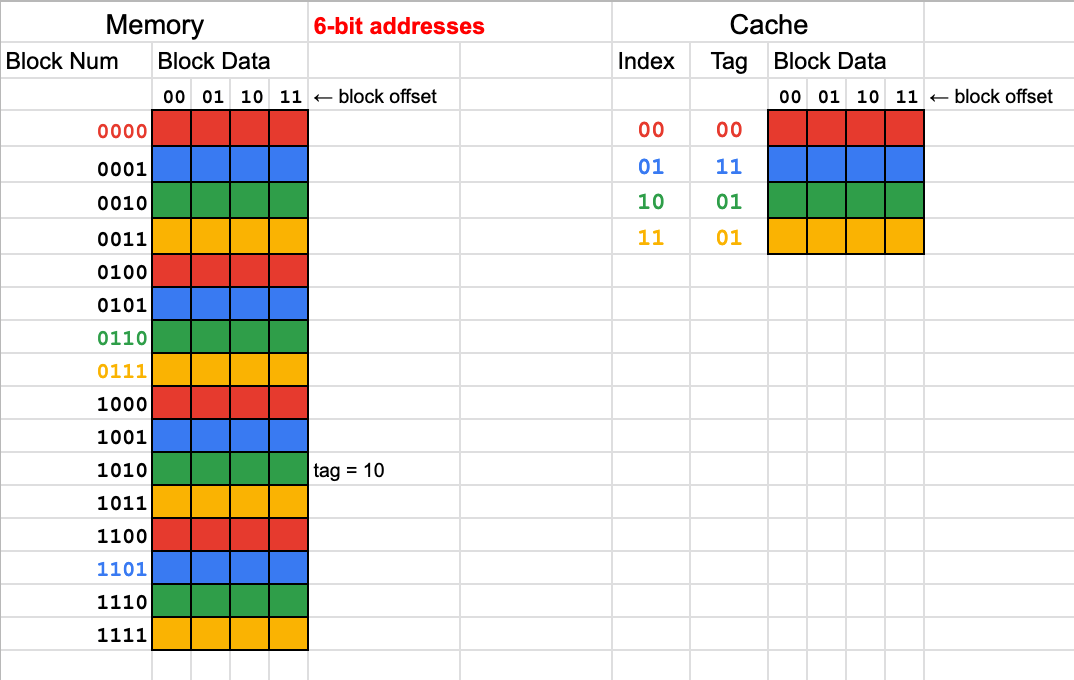
2.1 Conflict
- what happens if we access these two addresses in alternation?
- every access is a cache miss, replacing the address that was just loaded in on the last miss
- rest of the cache goes unused
3 Associativity
- each address maps to exactly one set
- each set can store a block in more than one way (in more than one line)
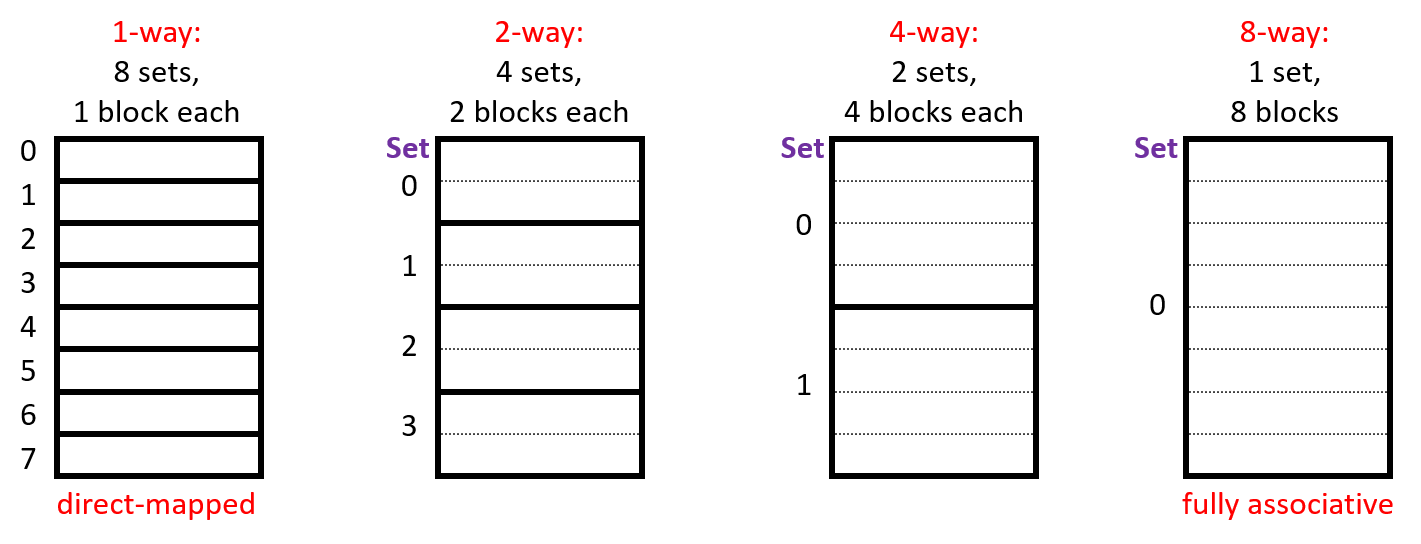
- capacity of a cache (\(C\)) is number of sets (\(S\)) times the number of lines per set (\(E\)) times the block size (\(B\), number of bytes stored in a line)
- \(C = S \times E \times B\)
3.1 Example
| block size | capacity | address width |
|---|---|---|
| 16 bytes | 8 blocks | 16 bits |
Where would data from address 0x1833 be placed?2
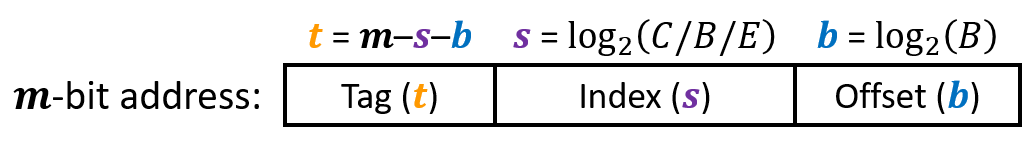
3.2 Placement
- where do we store a new block when we load it into the cache?
- any empty block in the correct set may be used to store block
- if there are no empty blocks, which one should we replace?
- no choice for direct-mapped caches (each set has only one block, so that block has to be replaced)
- caches typically use something close to least recently used (LRU)
4 Generic Cache Memory Organization
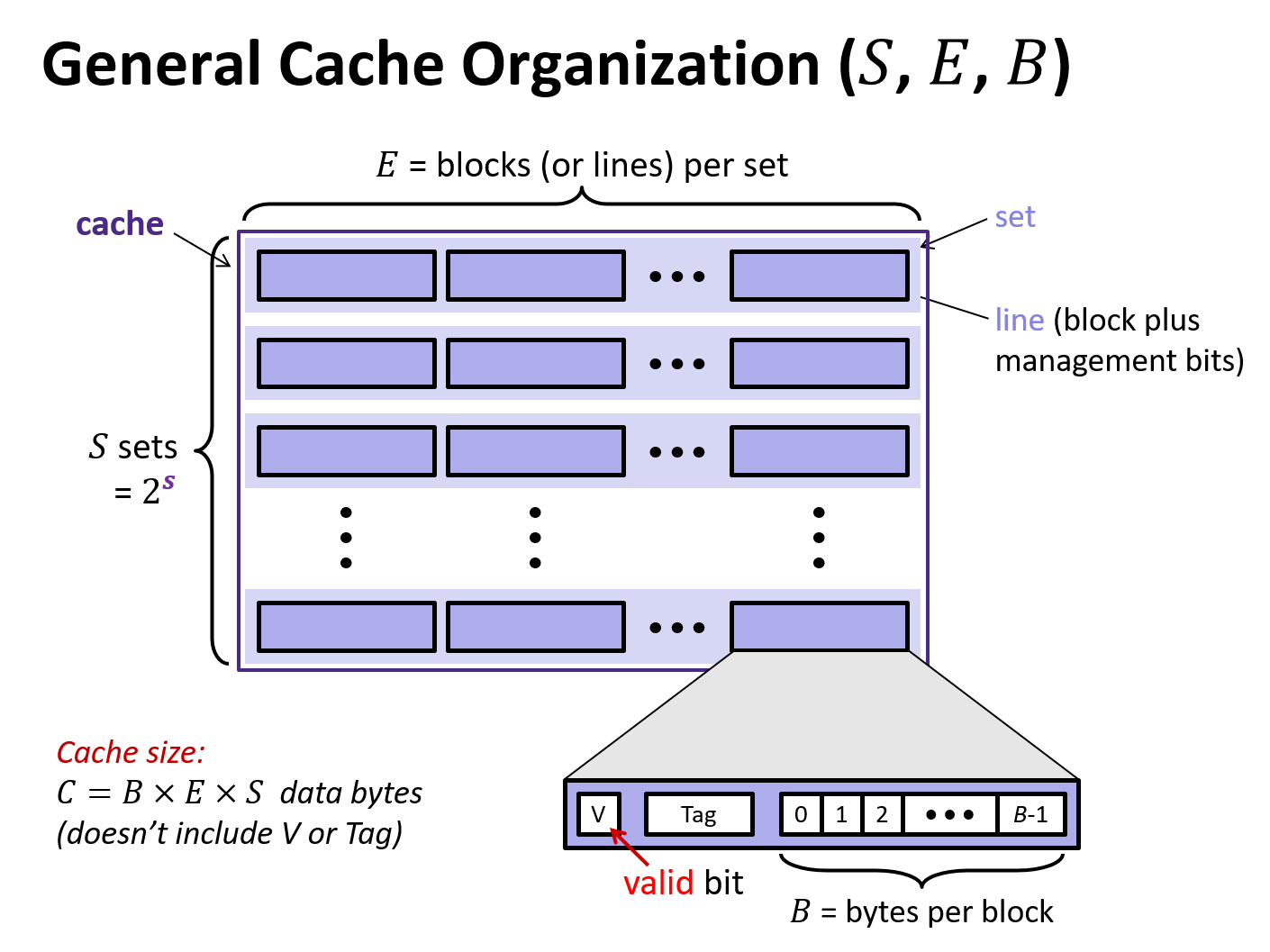
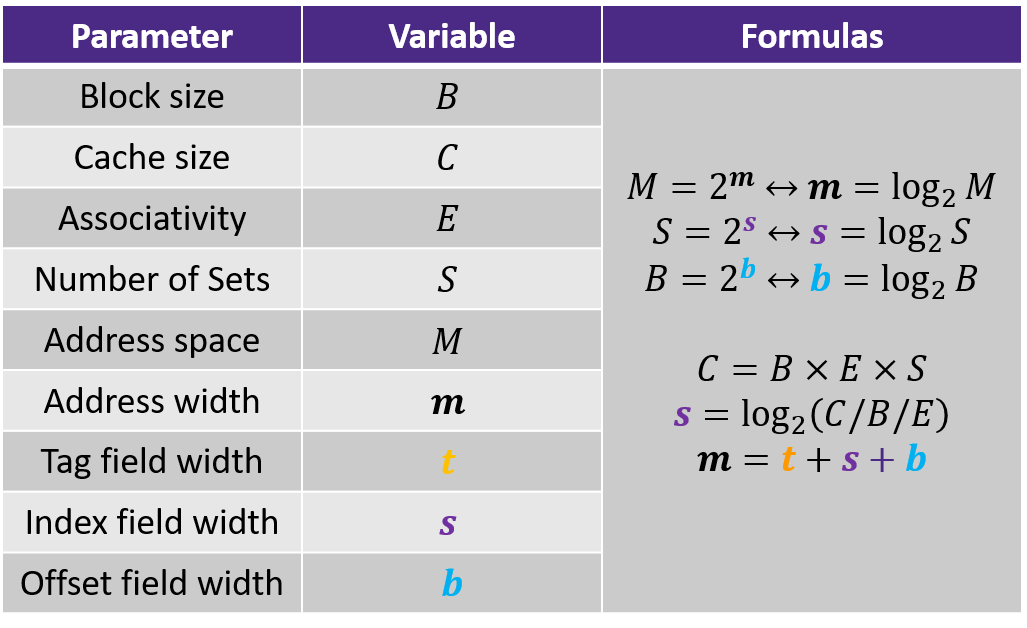
- a cache has an array of \(S = 2^s\) cache sets, each of which contain \(E\) blocks or cache lines
- each line consists of a valid bit to indicate whether the line contains meaningful information, \(t=m-s-b)\) tag bits to indentify a block within the cache line, and a data block of \(B=2^b\) bytes
- management bits (valid bit and tag) plus block data
- hence, the cache organization is parameterized by the tuple \((S, E, B)\) with a capacity (excluding tag and valid bits) of \(C = S\times E\times B\)
- instruction to load m-bit address \(A\) from memory, CPU sends \(A\) to the cache
- similar to a hash table with a simple hash function, the cache just inspects the bits of \(A\) to determine if it is present
- \(S\) and \(B\) define the partition of the bits of \(A\)
- \(s\) set bits index into the array of \(S\) sets
- \(t\) tag bits indicate which line (if any) within the set contains the target word
- a line contains the target word if and only if the valid bit is set and the tag bits match
- \(b\) block offset bits give the offset of the word in the $B$-byte data block
4.1 Cache Parameter Exercise
With 12-bit addresses, a 256 byte cache, 32 byte block size, and 2-way associativity, how are addresses used for caching?3
5 Direct Mapped Caches
- spreadsheet example (8 byte blocks, accessing
int)- use \(s\) bits to find set
- valid? + tag match = hit
- no match? old line gets envicted and overwritten
- use block offset to find starting byte to read
int - what if we were reading a long? we'd need bytes past the end of the block
- would be slow and messy to read across block boundaries
- this is why we want everything aligned to an address that's a multiple of its size!
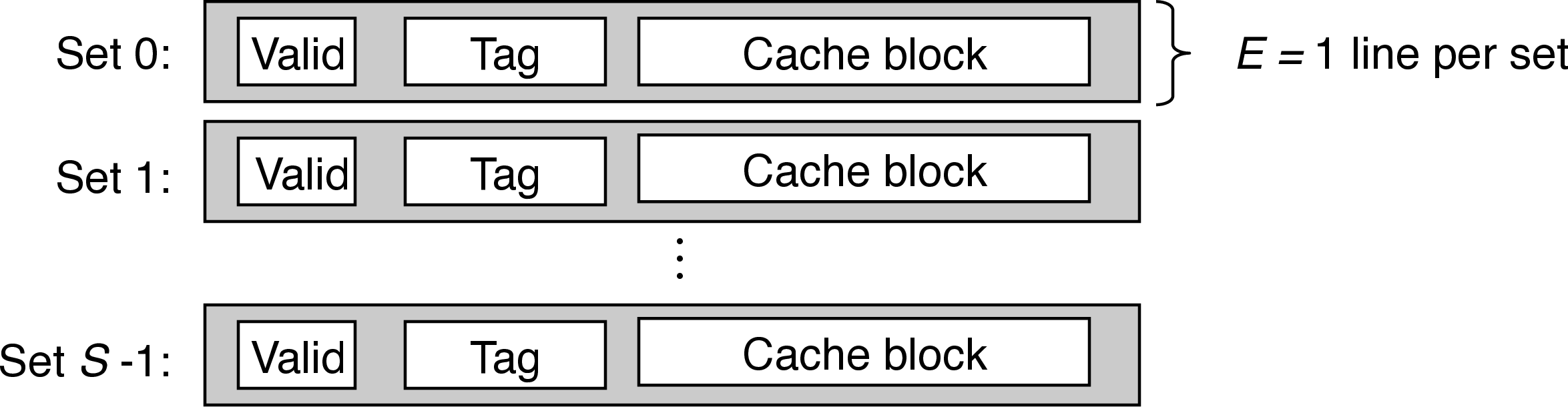
- when there is one line per set (\(E=1\)), the cache is a direct-mapped cache
- three cache resolution steps: set selection, line matchting, word extraction
5.0.1 Set Selection
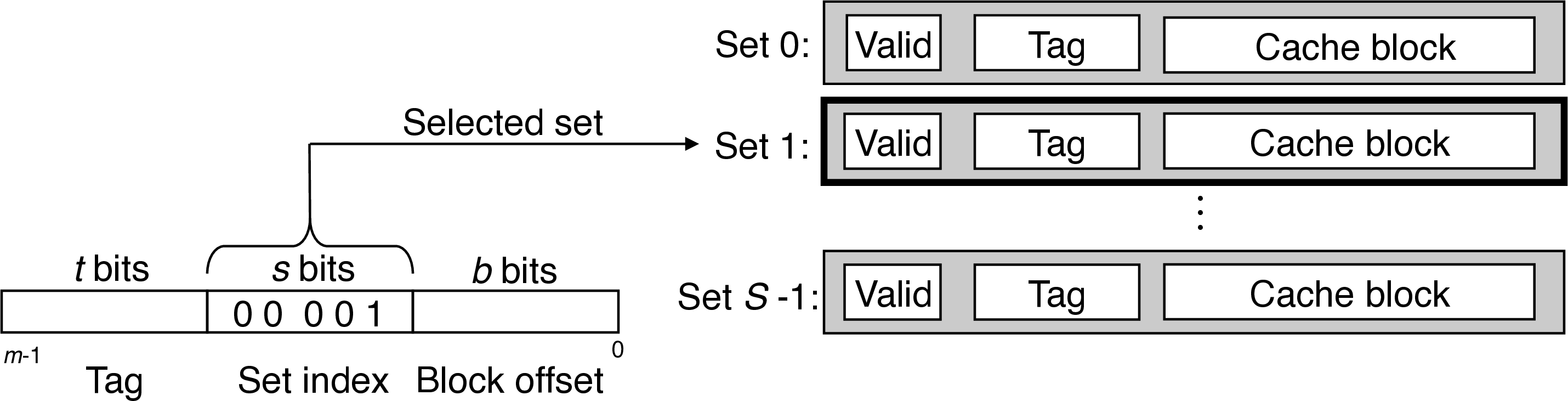
- interpret set bits an unsigned integer index
5.0.2 Line Matching
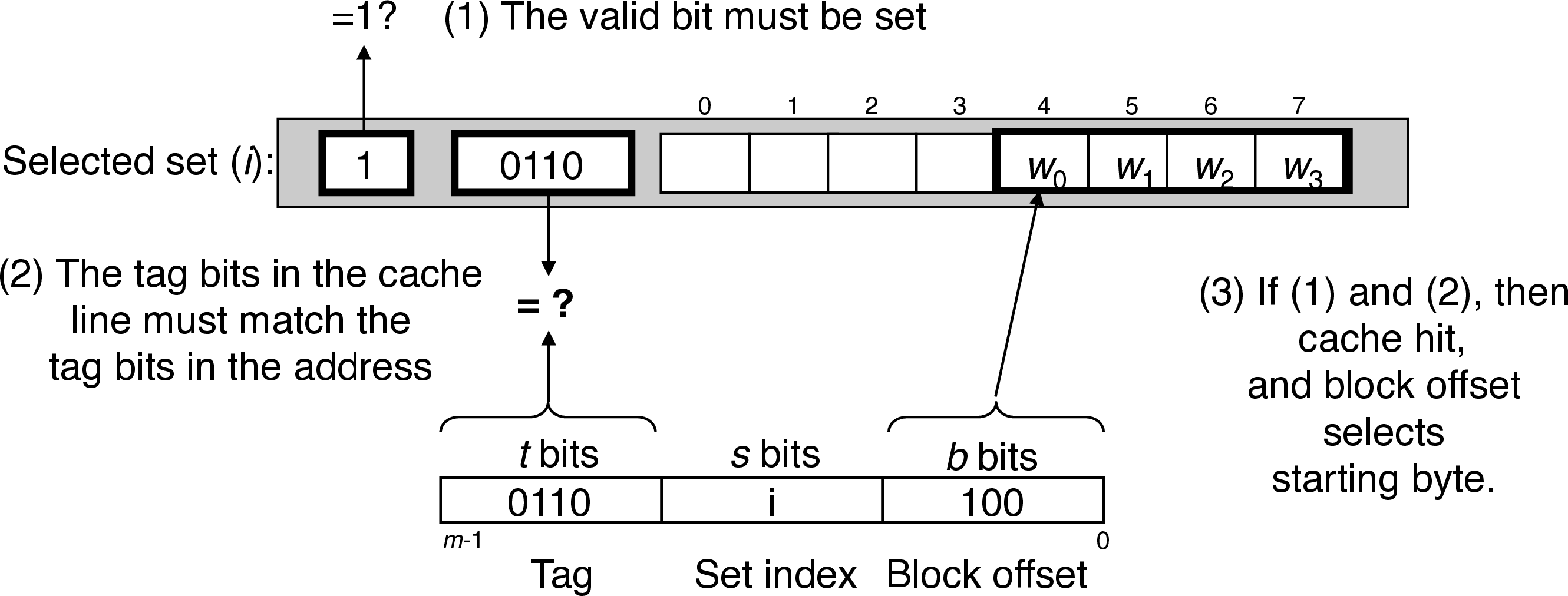
5.0.3 Word Selection
- block offset bits indicate the offset of the first byte of the target word
5.0.4 Line Replacement
- on a cache miss, replace the line in the set with the newly retrieved line (since there's only one in a direct-mapped cache)
5.0.5 Conflict Misses
- thrashing between blocks that index to the same set is common and can cause significant slowdown
- often when array sizes are powers of two
- easy solution is to add padding between data to push temporally local values into different sets
6 Set Associative Caches
- spreadsheet example (8 byte blocks, accessing
short)- use \(s\) bits to find set
- valid? + tag match = hit (have to compare to both tags)
- no match? one line is selected for evictiong (random, LRU, etc.)
- use block offset to find starting byte to read
short
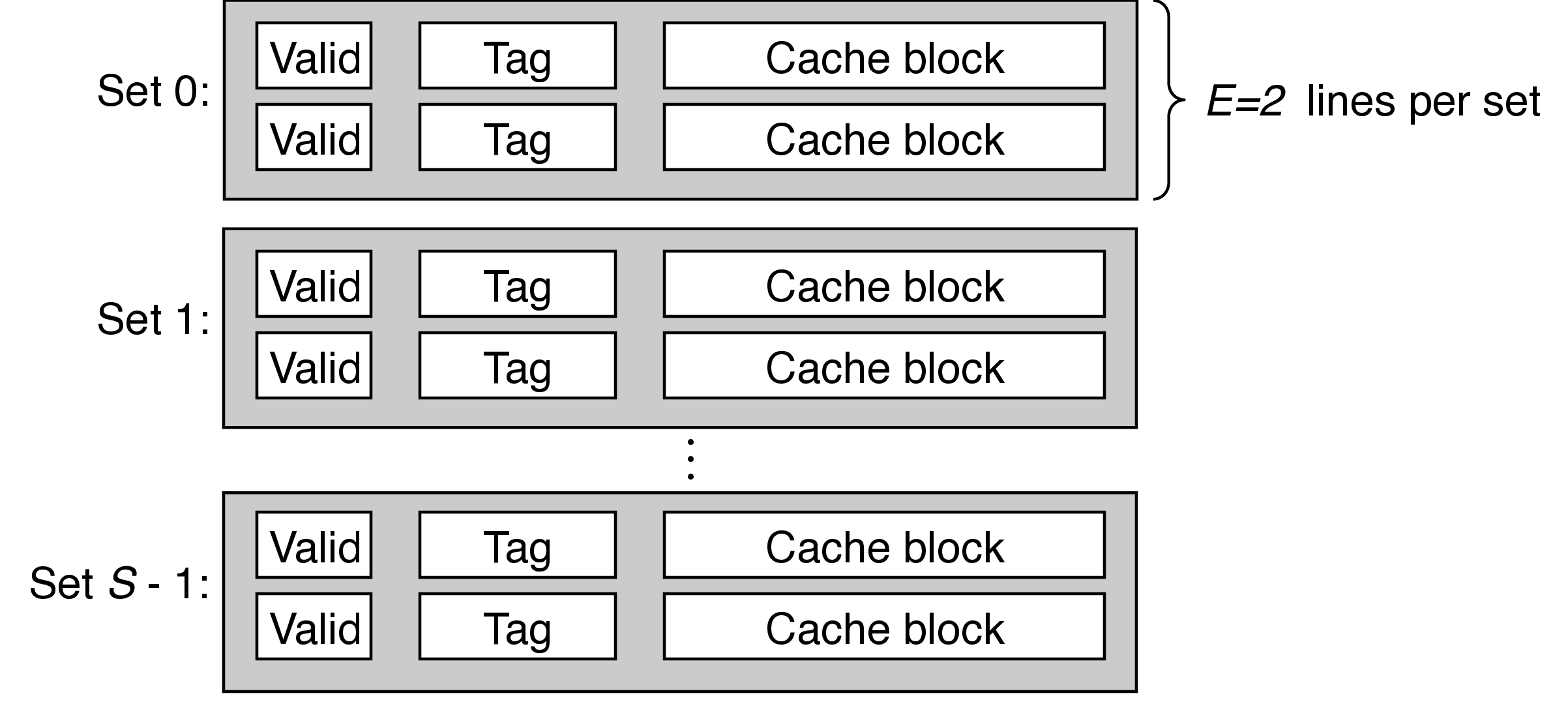
- A cache with \(1 < E < C/B\) is called an $E$-way associative cache
6.0.1 Set Selection
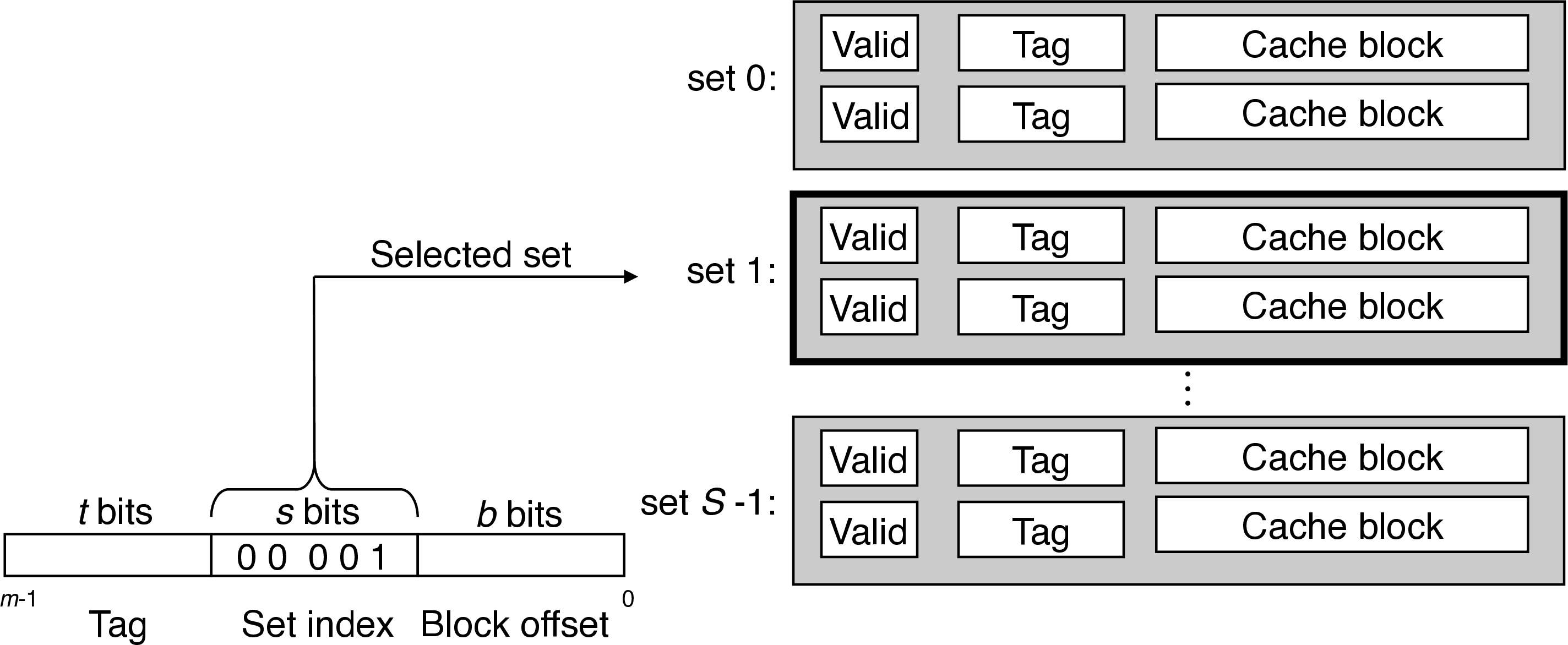
- interpret set bits an unsigned integer index
6.0.2 Line Matching & Word Selection
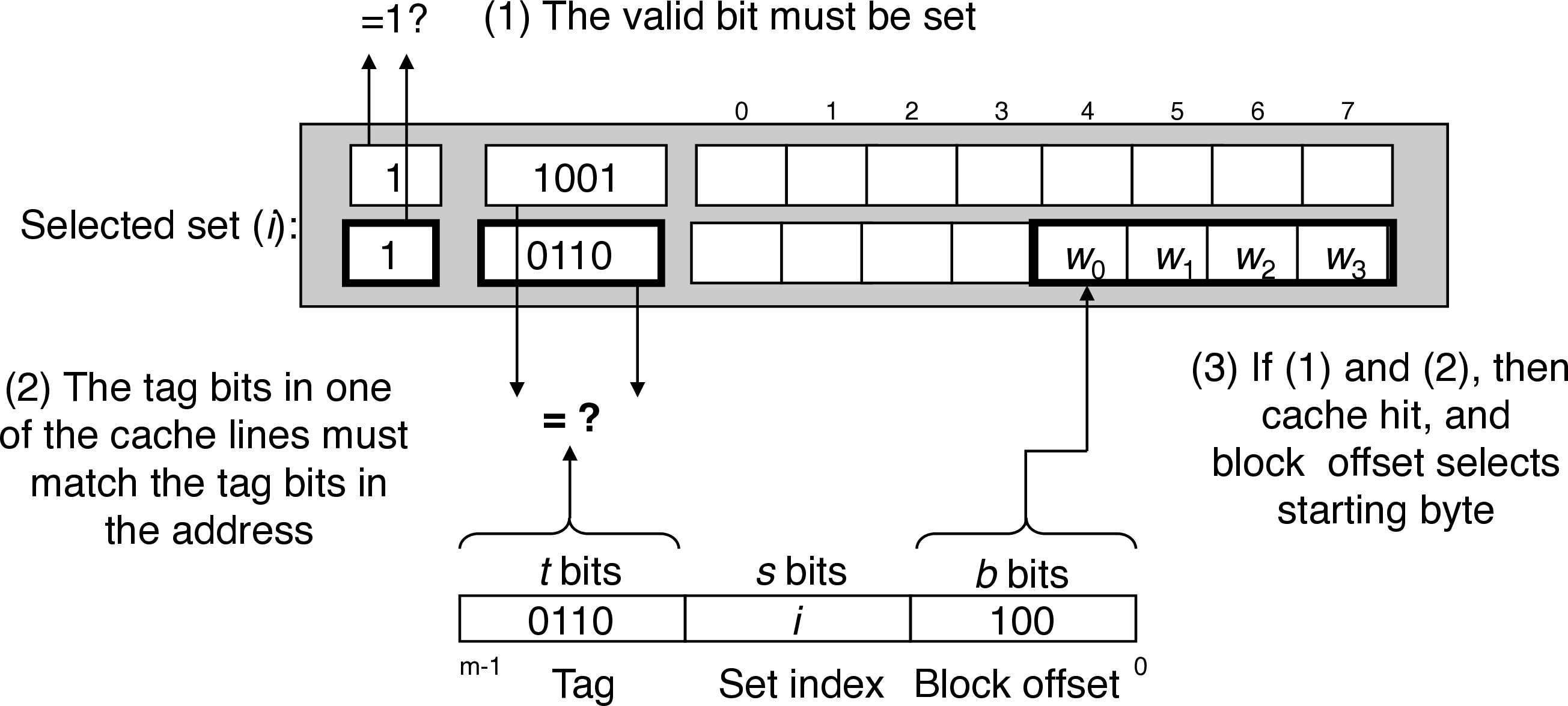
- has to compare tag bits with multiple lines
- conventional memory takes an address and returns the value there vs associative memory that takes a key and returns a value from a matching (key, value) pair
- each set acts like a small associative memory
6.0.3 Line Replacement
- replace empty lines first
- random, least frequently used (LFU), and least recently used (LRU) possible policies
7 Fully Associative Caches
- when a single set contains all the cache lines (\(E = C/B\))
- difficult to scale line matching, so only appropriate for small caches
8 Lab 4 Advice
- we only care about simulating hits/misses/evictions, so we don't need to simulate data blocks or use the block offset
- general lookup algorithm:
- extract set index and tag from address
- iterate over lines in corresponding set
- check valid bit in each line
- if valid, compare tag from address to tag stored in line
- on a match, result is cache hit
- if no lines match, result is a cache miss
- replace least recently used line with tag from address, set valid to true
- least recently used:
- each line has an integer counter
- every time a set is accessed, increment the counter for each line in the set
- when a line matches or is replaced, set its
lru_counterto 0 - thus, the line with the highest
lru_countervalue is the least recently used
9 Homework
- CSPP practice problems 6.12–6.16 (p. 628–630) will be a good warmup for implementing lab 4
- Lab 4 check-in post due 9pm Monday, May 25
- The week 7 quiz is due 9pm Wednesday, May 27
Footnotes:
0x0a and 0x28, both have set index bits 10
See exercise on the spreadsheet.
32-byte block size means 5 block offset bits. \(C = 256\), \(B = 32\) and \(E = 2\) (2-way associative), so \(S = C / B / E = 4\). \(s = \log_2 S = 2\) set index bits. That leaves \(12 - 5 - 2 = 5\) tag bits.