CS 208 s22 — The Memory Hierarchy and Caching
Table of Contents
1 CPU-Memory Bottleneck
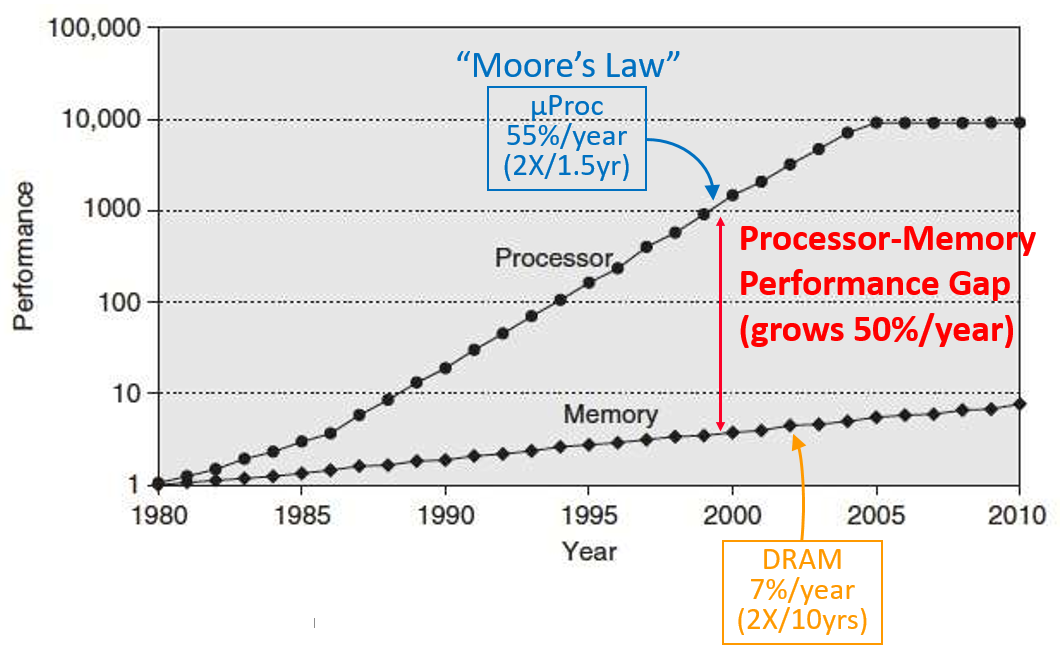
- processor speed has increased at a much faster rate than memory speed
- this creates an increasing bottleneck when the CPU needs to access memory
- the CPU wastes time waiting around
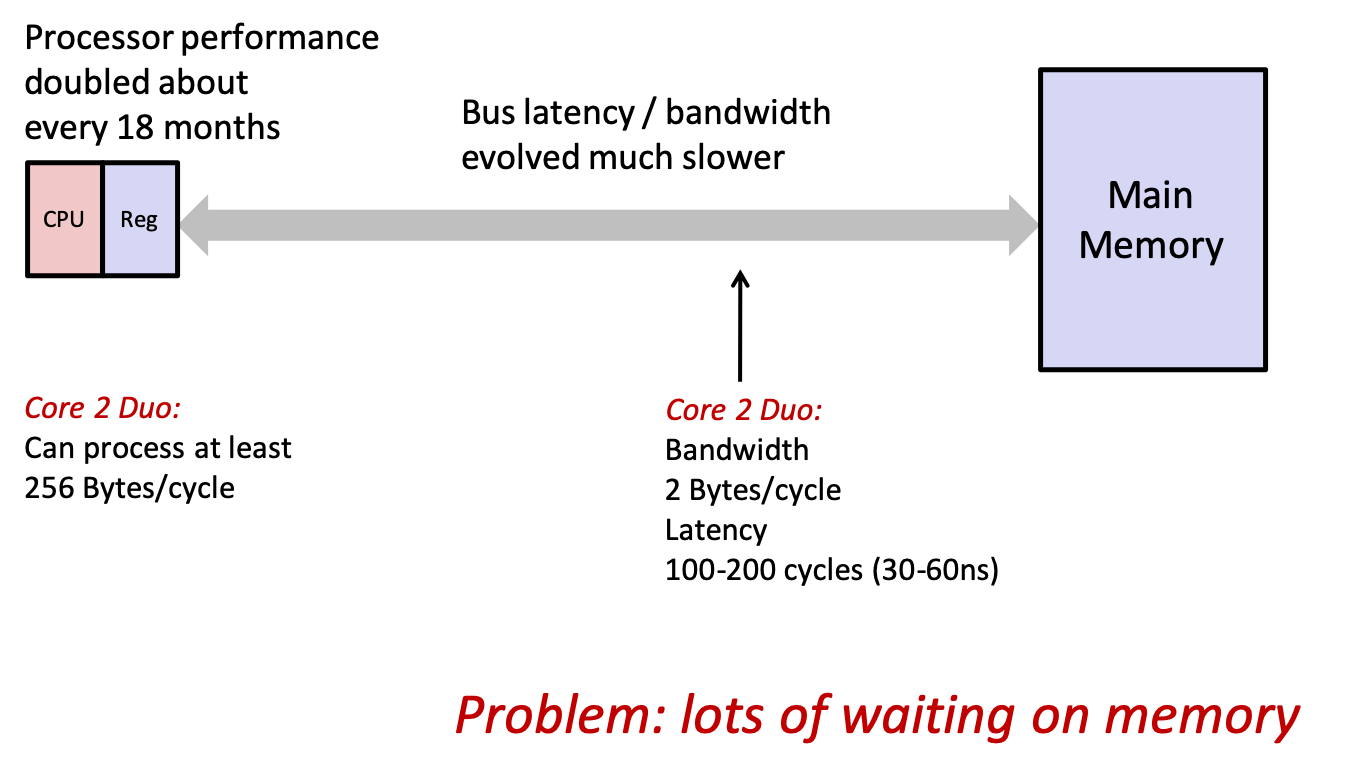
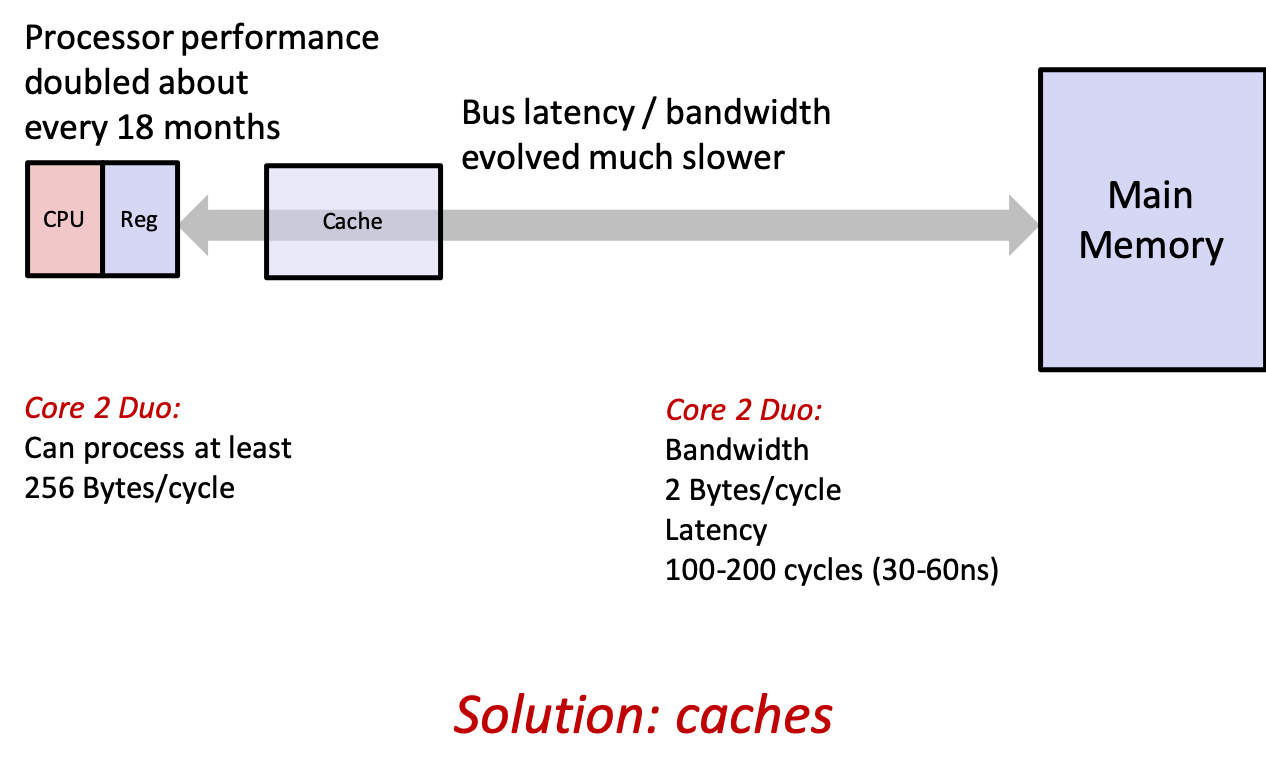
- what if we could add additional memory that was much smaller, but much faster to access (i.e., closer to the CPU)?
- these additional memories are called caches
- if the data we need happens to be in the cache, the CPU will avoid the long wait to go all the way to main memory
2 Program's View of Memory
- from the program's perspective, there's
- registers
- memory
- disk
- (possibly) remote storage
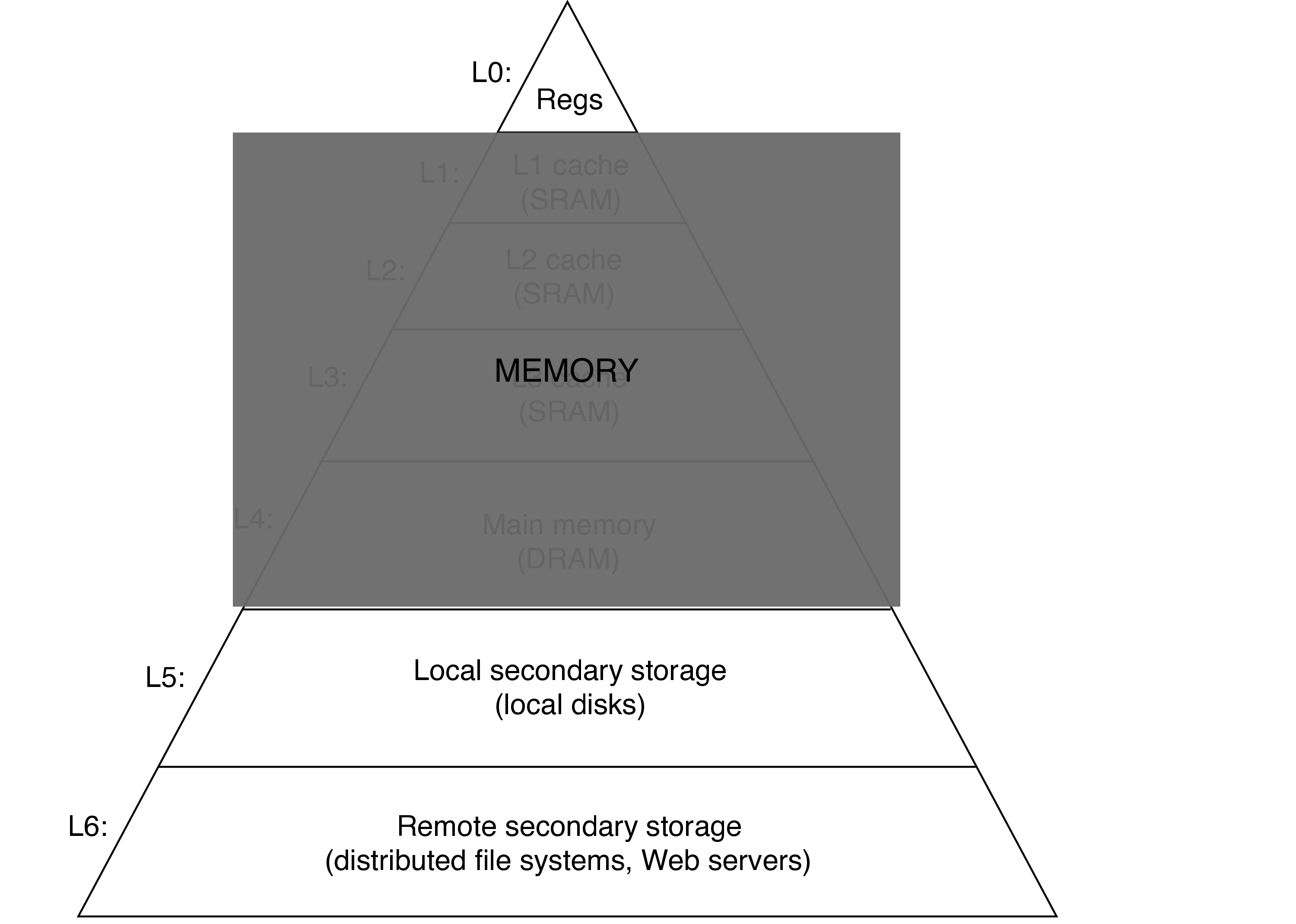
- so the programmer will never explicitly interact with caches—they will be transparent to the program
- however, adding different levels of memory will make accessing some data much faster
3 Locality
- first, the principle that enables adding new levels of memory to increase performance: locality
- essentially: referencing data that was recently referenced or that is nearby recently referenced data
- if we assume recently referenced data will be referenced again, it's worth it to do some extra work after the first reference to make future references much faster
- temporal locality: a referenced memory location is likely to be referenced again in the near future
- spatial locality: if a memory location is referenced, nearby locations are likely to be referenced in the near future
- in general, programs with good locality run faster, as all levels of the system are designed to exploit locality
- hardware cache memories, OS caching recently referenced chunks of virtual address space and disk blocks, web browsers caching recent documents
3.1 Nested Arrays
T A[R][C]- 2D array to data type
T Rrows,Ccolumns- What's the array's total size?
R*C*sizeof(T)
- 2D array to data type
- single contigious block of memory
- stored in row-major order
- all elements in row 0, followed by all elements in row 1, etc.
- address of row
iisA + i*(C * sizeof(T))
- Arrays can have more than 2 dimensions
int data[100][100][100]is a 3D array with 1,000,000 (100*100*100) contiguous ints
3.2 Code With Good Locality Accesses Adjacent Elements
int sum_array_rows(int a[M][N]) { int i, j, sum = 0; for (i = 0; i < M; i++) for (j = 0; j < N; j++) sum += a[i][j]; return sum; }

This is a stride 1 access pattern because we shift by 1 element each access. In general, the lower the stride, the better the locality.
int sum_array_rows(int a[M][N]) { int i, j, sum = 0; for (j = 0; j < N; j++) for (i = 0; i < M; i++) sum += a[i][j]; return sum; }

This is a stride N access pattern because we shift by N elements each access.
Recall the example from our first class where switching the order of nested loops caused summing an array to take almost 40 times longer. That was exactly this difference—going from a stride 1 access pattern to a stride N access pattern.
3.3 Practice
Which of the following are examples of spatial or temporal locality?1
- the loop variable in a for loop
- accessing elements of an array in order
- printing how long a program took to run
- reusing a temporary array
- combining multiple related variables into an object or struct
- passing function arguments as pointers
CSPP practice problem 6.8 (p. 609)2
#define N 1000 typedef struct { int vel[3]; int acc[3]; } point; point p[N];
The three functions below perform the same operation with varying degrees of spatial locality. Rank the functions with respect to the spatial local enjoyed by each. Explain how you arrived at your ranking.
void clear1(point *p, int n) { int i, j; for (i = 0; i < n; i++) { for (j = 0; j < 3; j++) { p[i].vel[j] = 0; } for (j = 0; j < 3; j++) { p[i].acc[j] = 0; } } } void clear2(point *p, int n) { int i, j; for (i = 0; i < n; i++) { for (j = 0; j < 3; j++) { p[i].vel[j] = 0; p[i].acc[j] = 0; } } } void clear3(point *p, int n) { int i, j; for (j = 0; j < 3; j++) { for (i = 0; i < n; i++) { p[i].vel[j] = 0; } for (i = 0; i < n; i++) { p[i].acc[j] = 0; } } }
4 Caches!
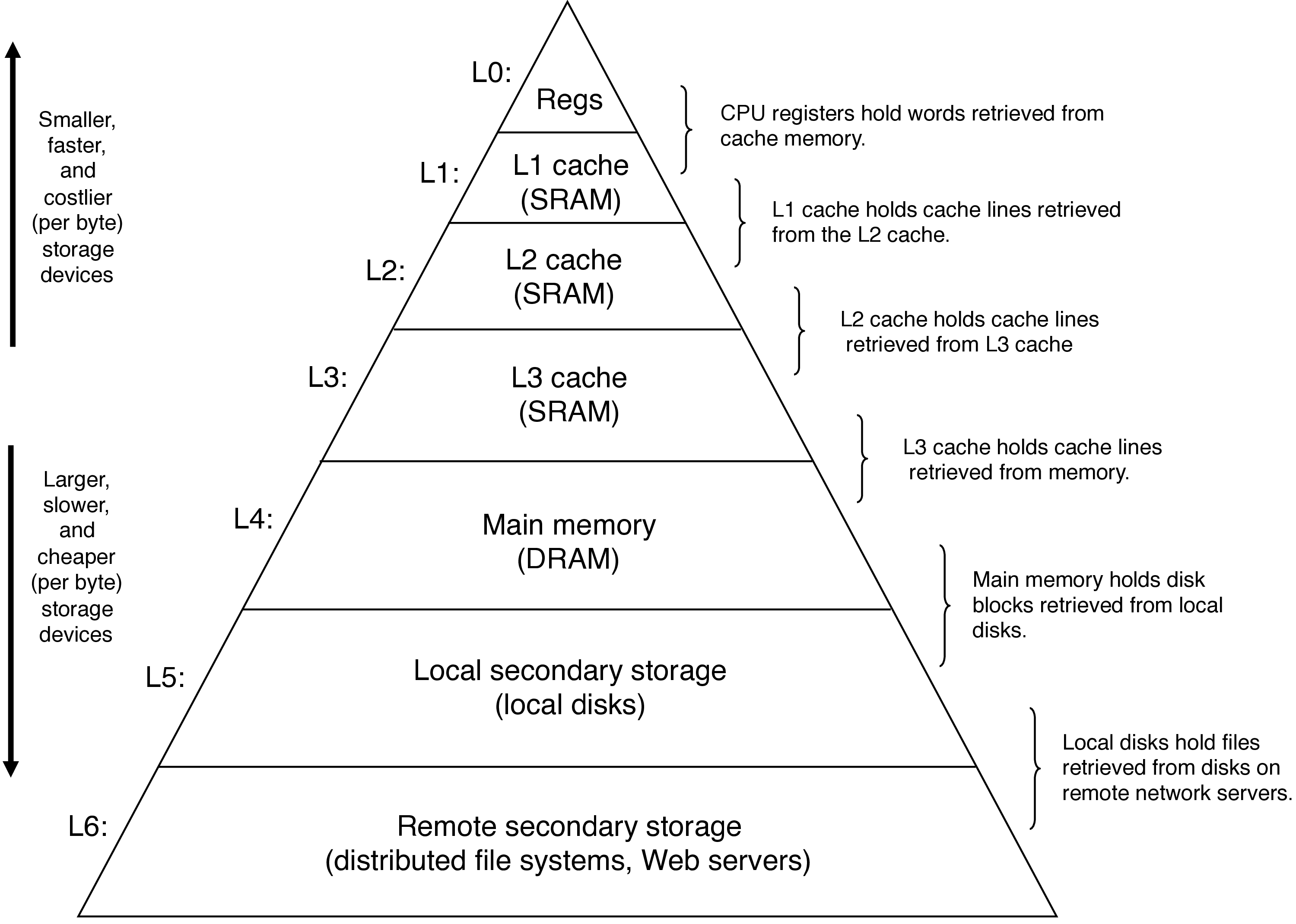
- 0 cycles to access a register (16×8 bytes)
- 4–75 cycles to access a cache (~10 MB)
- 100s to access main memory (GBs)
- 10s of millions to access disk (TBs)
4.1 Aside: SRAM vs DRAM
4.1.1 Static RAM (SRAM)
- bistable memory cell, 6 transitors per bit
- stable in two states, any other state quickly moves into a stable one
- resiliant to disturbance
4.1.2 Dynamic RAM (DRAM)
- single transitor and capacitor per cell, can be very dense
- sensitive to disturbance
- drains on a timescale of 10 to 100 ms, must be refreshed (read and re-written)
- error-correcting codes (extra bits associated with each word) can also be used
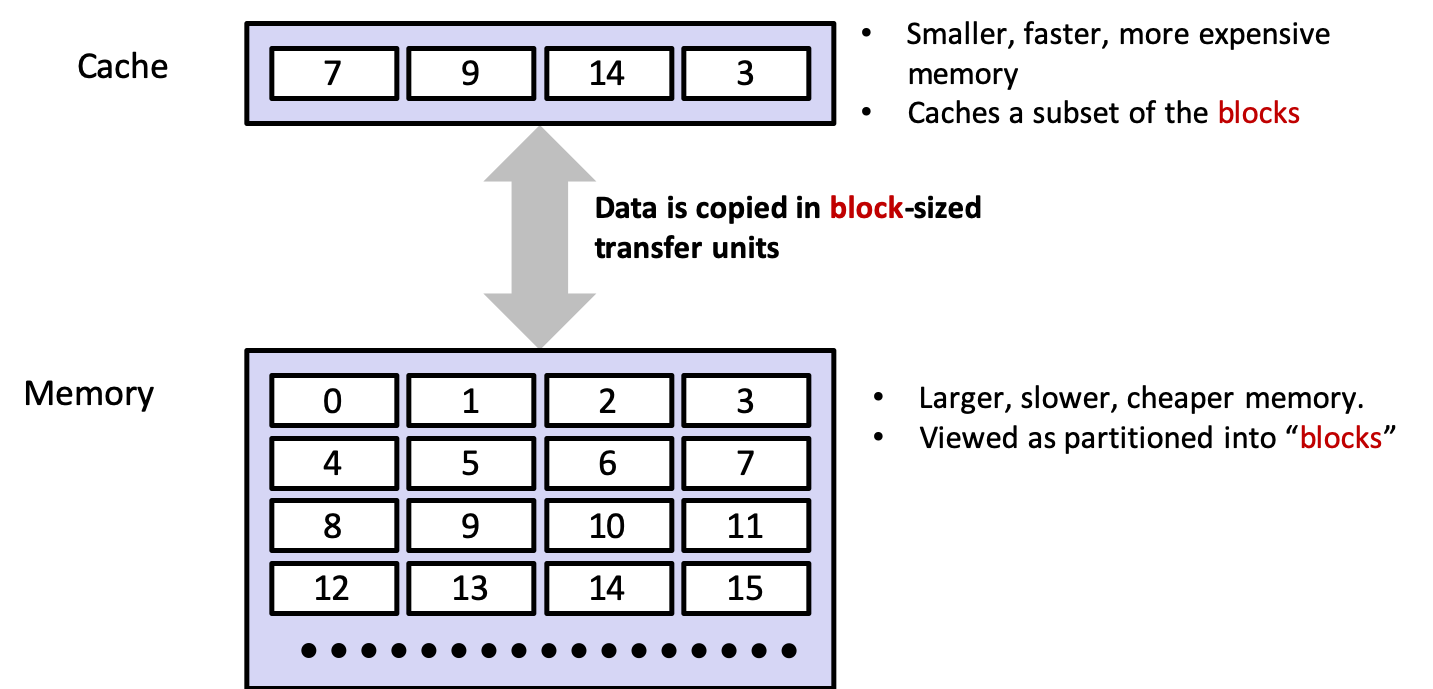
4.2 Basic Idea
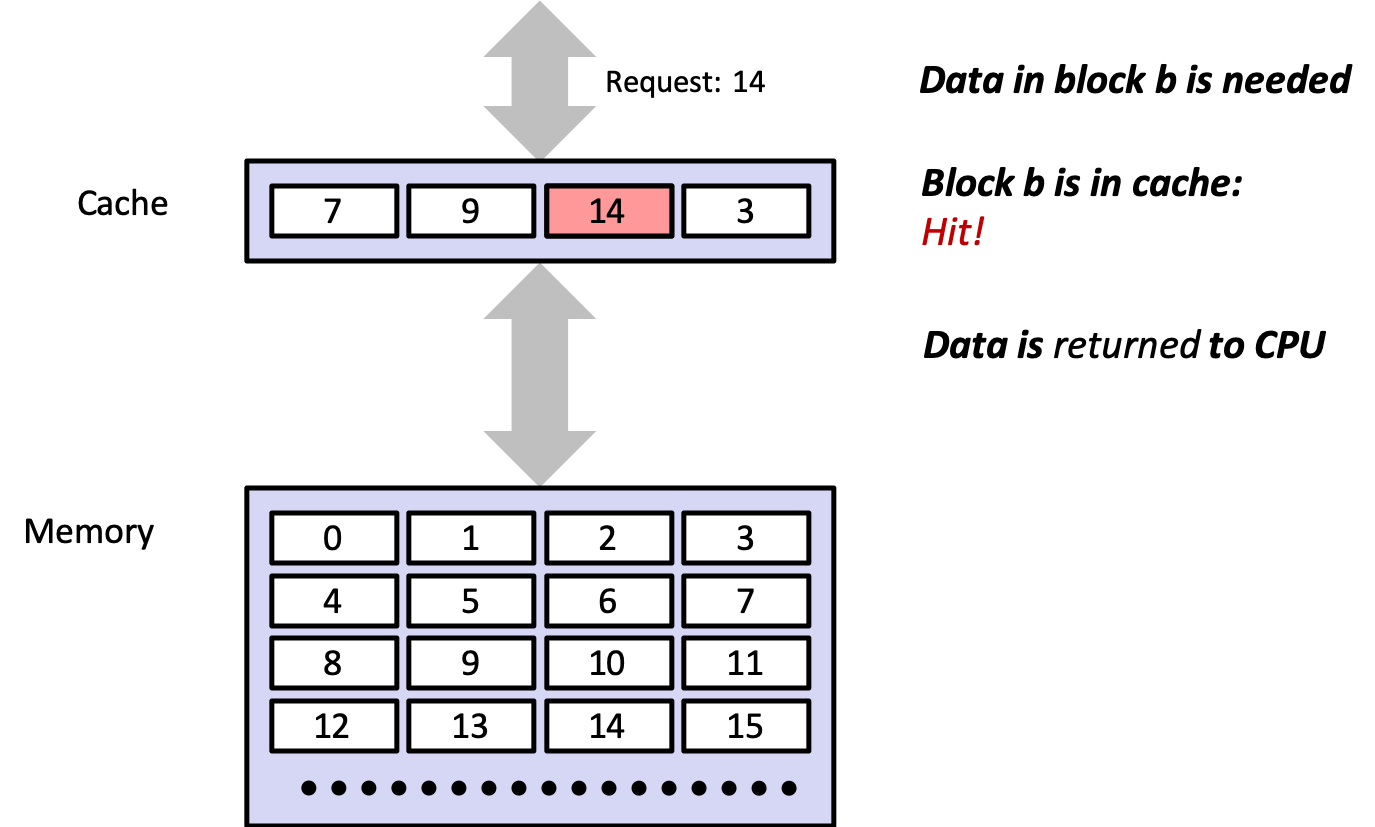
4.2.1 Cache Hit
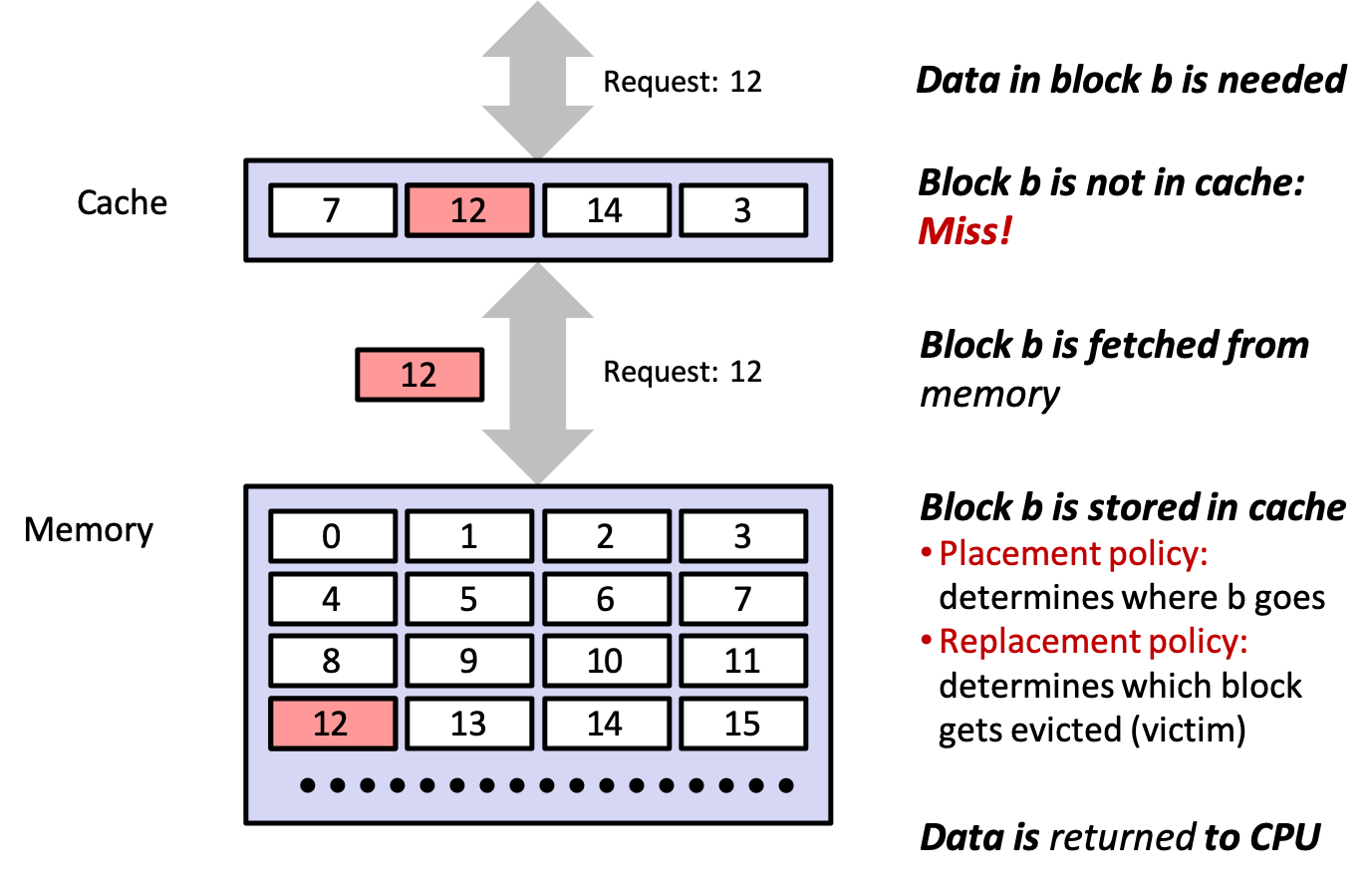
4.2.2 Cache Miss
4.3 Terminology
4.3.1 cache hits
- finding needed data in level \(k\) instead of \(k + 1\)
4.3.2 cache misses
- having to go to level \(k+1\) because the data is not in level \(k\)
- cache at level \(k\) now contains the data
- if level \(k\) cache is full, it will overwrite an existing block (replacing or evicting)
- which block gets ovewritten governed by the cache's replacement policy
- a random replacement policy would choose randomly
- a least recently used (LRU) policy would choose the block with the oldest last access
5 Anatomy of a Real Cache Hierarchy
The Intel Core i7 processor:
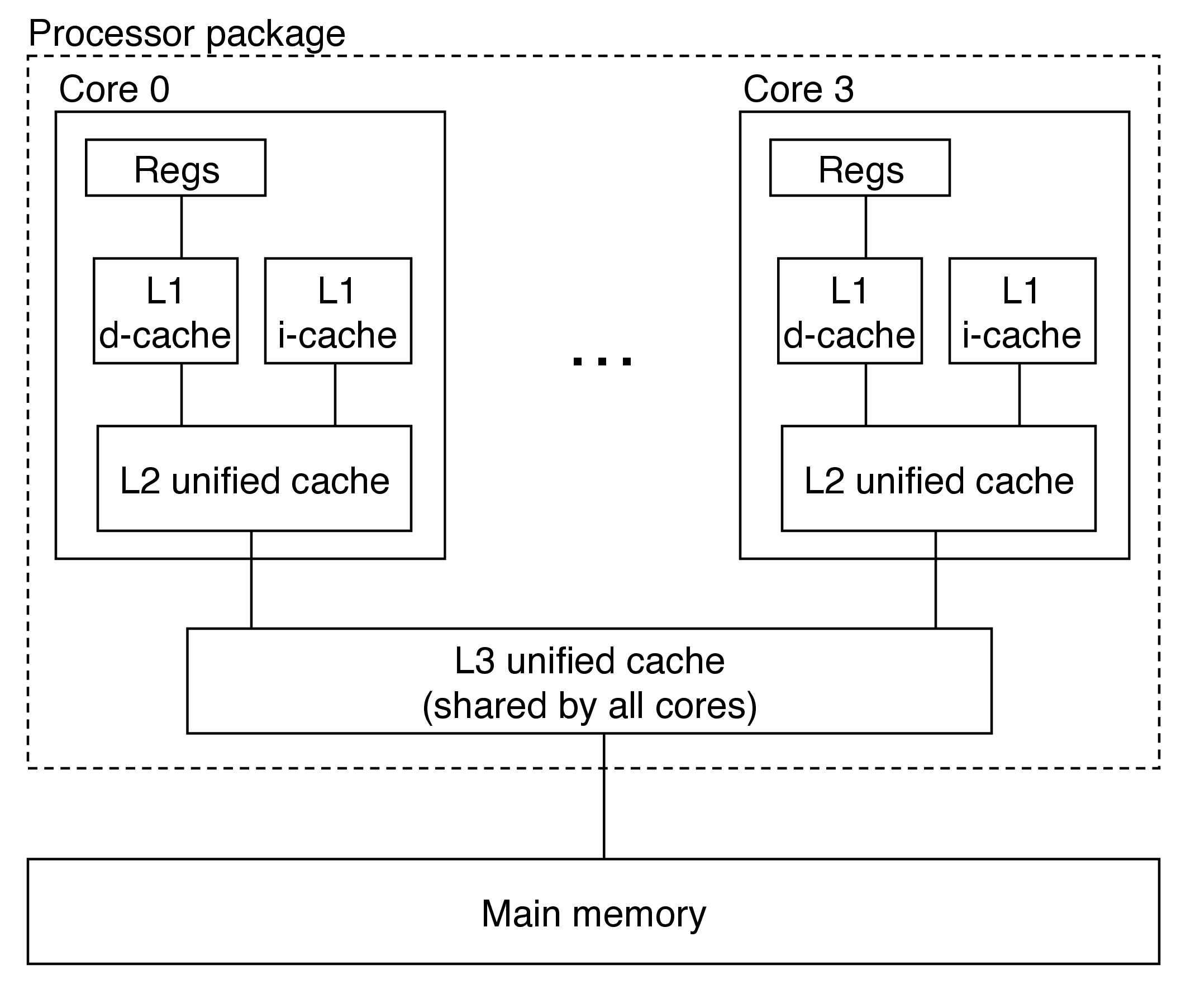
- caches that hold only instructions are i-caches
- caches that hold only data are d-caches
- caches that hold both are unified caches
- modern processors include separate i- and d-caches
- can read an instruction and data at the same time
- caches are optimized to different access patterns
- trades off fewer conflict misses (data and instructions won't conflict) for potentially more capacity misses (smaller caches)
5.1 cache management
- each level must have some managing logic provided by software or hardware
- compiler manages registers
- L1/2/3 managed by hardware logic built into the caches
- usually no action is required on the part of the program to manage caches
Footnotes:
- the loop variable in a for loop: TEMPORAL (accessing the same data each loop iteration)
- accessing elements of an array in order: SPATIAL (accessing adjacent memory locations)
- printing how long a program took to run: NEITHER (unrelated to data access)
- reusing a temporary array: TEMPORAL (memory already in cache)
- combining multiple related variables into an object or struct: SPATIAL (variables are made to be adjacent in memory)
- passing function arguments as pointers: NEITHER (may avoid unnecessary copying of memory, but not directly related to locality)
The key to solving this problem is to visualize how the array is laid out in memory and then analyze the reference patterns. Function clear1 accesses the array using a stride-1 reference pattern and thus clearly has the best spatial locality. Function clear2 scans each of the N structs in order, which is good, but within each struct it hops around in a non-stride-1 pattern at the following offsets from the beginning of the struct: 0, 12, 4, 16, 8, 20. So clear2 has worse spatial locality than clear1. Function clear3 not only hops around within each struct, but also hops from struct to struct. So clear3 exhibits worse spatial locality than clear2 and clear1.