CS 208 w20 lecture 18 outline
1 Poll
Which pair of address conflict?
1.1 Conflict
- what happens if we access these two addresses in alternation?
- every access is a cache miss, rest of the cache goes unused
2 Associativity
- each address maps to exactly one set
- each set can store a block in more than one way (in more than one line)
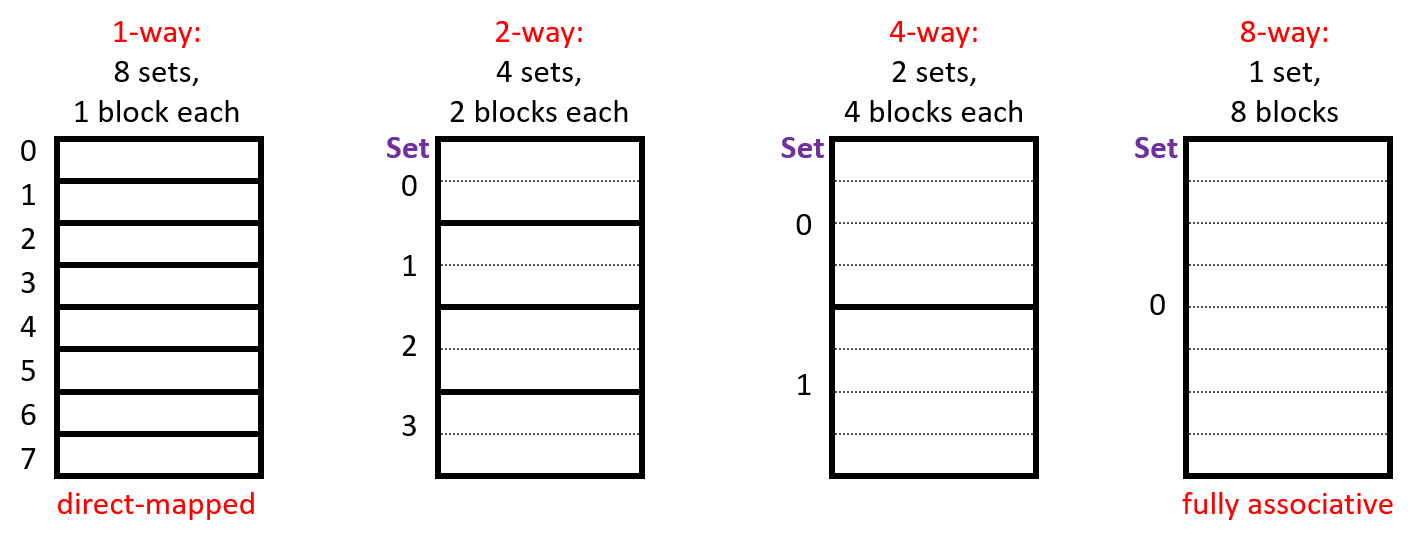
- capacity of a cache (\(C\)) is number of sets (\(S\)) times the number of lines per set (\(E\)) times the block size (\(B\), number of bytes stored in a line)
- \(C = S \times E \times B\)
2.1 Example
| block size | capacity | address width |
|---|---|---|
| 16 bytes | 8 blocks | 16 bits |
Where would data from address 0x1833 be placed?
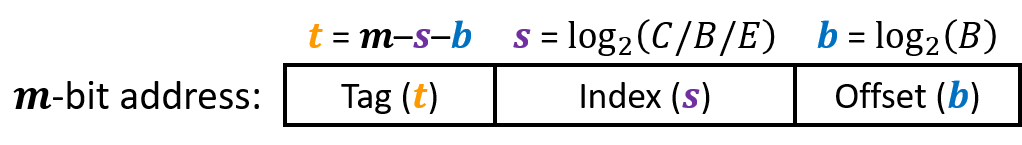
2.2 Placement
- any empty block in the correct set may be used to store block
- if there are no empty blocks, which one should we replace?
- no choice for direct-mapped caches
- caches typically use something close to least recently used (LRU)
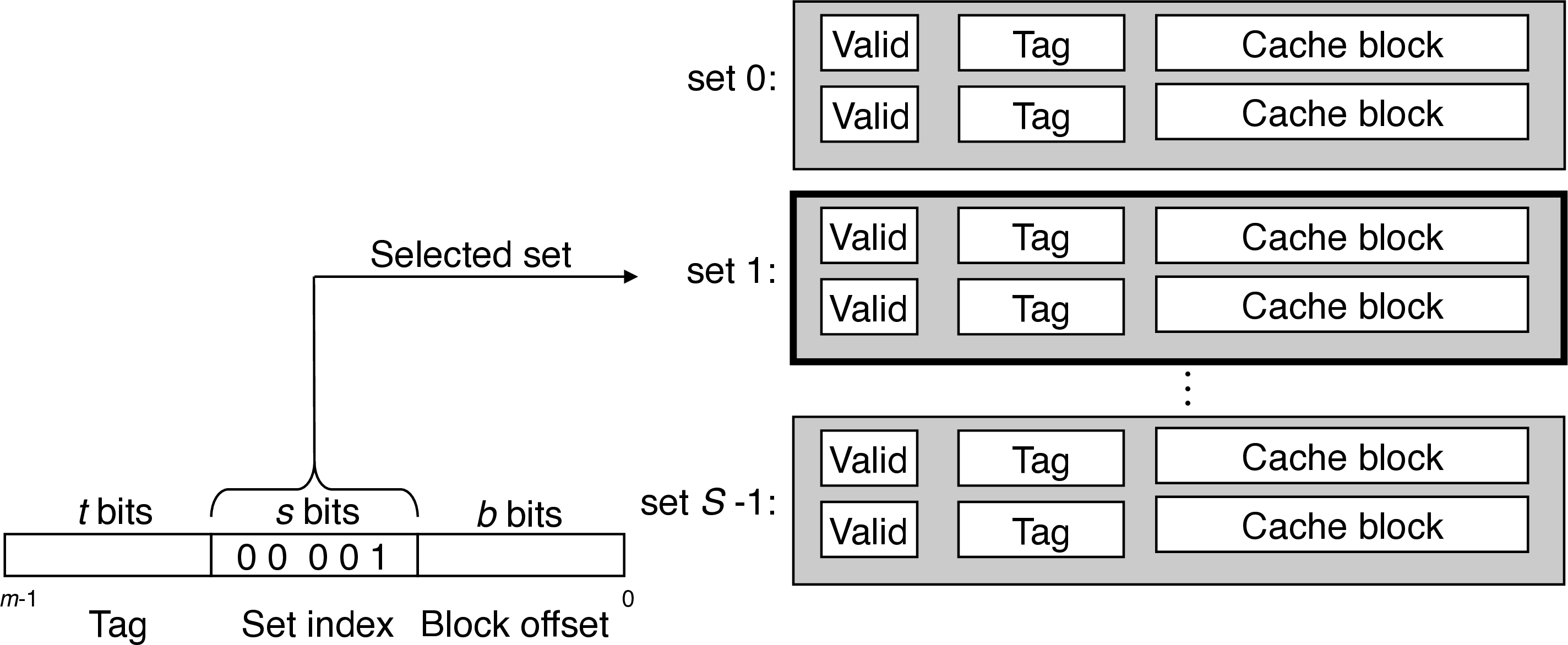
3 Generic Cache Memory Organization
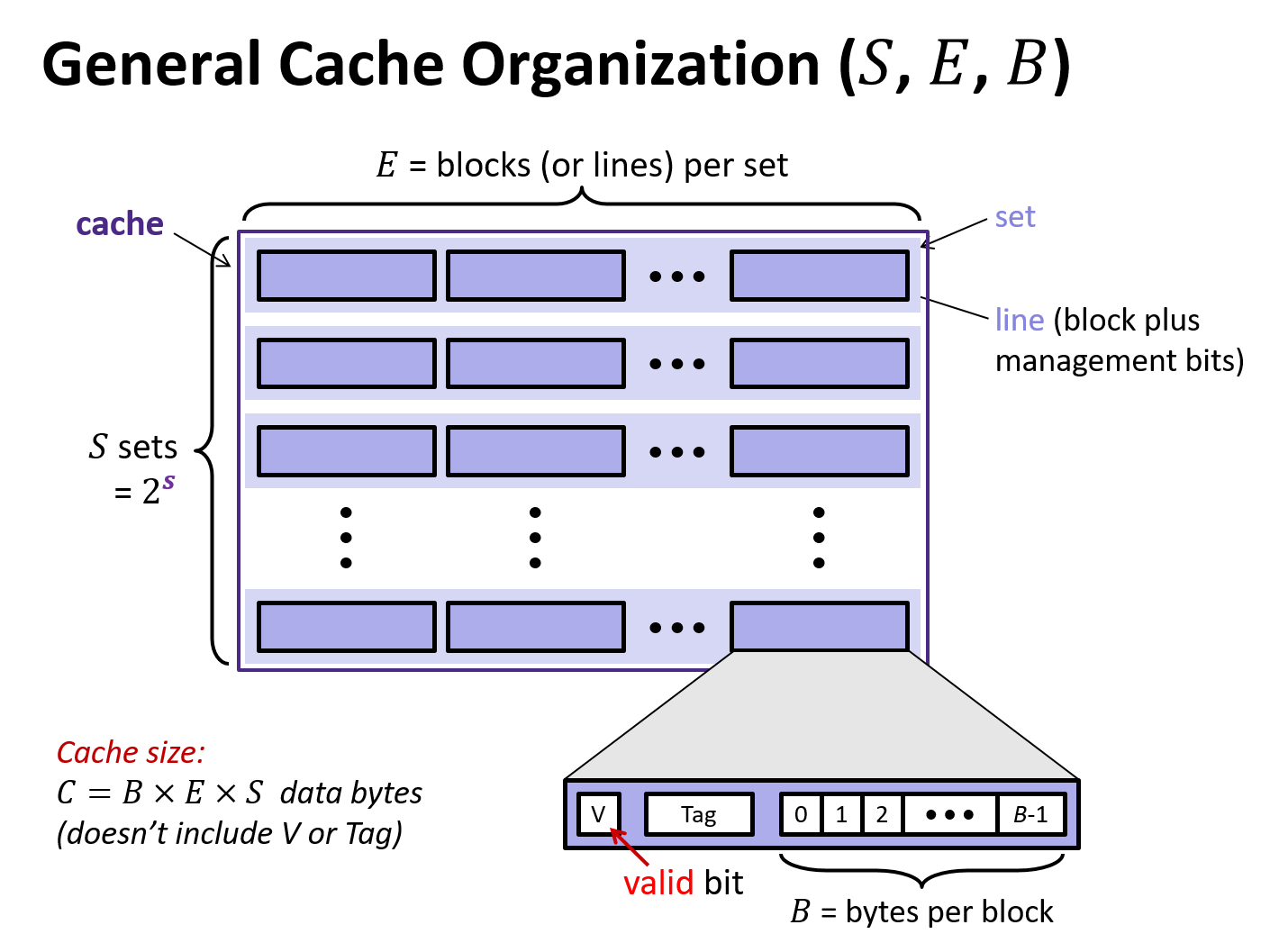
- a cache has an array of \(S = 2^s\) cache sets, each of which contain \(E\) blocks or cache lines
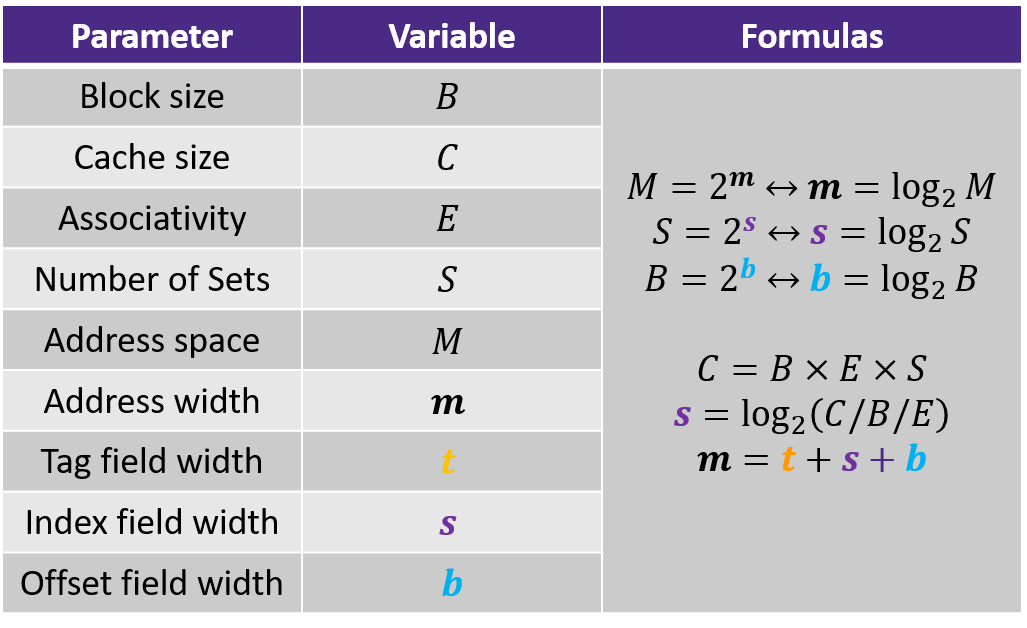
- each line consists of a valid bit to indicate whether the line contains meaningful information, \(t=m-(b+s)\) tag bits to indentify a block within the cache line, and a data block of \(B=2^b\) bytes
- management bits (valid bit and tag) plus block data
- hence, the cache organization is parameterized by the tuple \((S, E, B)\) with a capacity (excluding tag and valid bits) of \(C = S\times E\times B\)
- instruction to load m-bit address \(A\) from memory, CPU sends \(A\) to the cache
- similar to a hash table with a simple hash function, the cache just inspects the bits of \(A\) to determine if it is present
- \(S\) and \(B\) define the partition of the bits of \(A\)
- \(s\) set bits index into the array of \(S\) sets
- \(t\) tag bits indicate which line (if any) within the set contains the target word
- a line contains the target word if and only if the valid bit is set and the tag bits match
- \(b\) block offset bits give the offset of the word in the $B$-byte data block
3.1 Cache Parameter Poll
4 Direct Mapped Caches
- spreadsheet example (8 byte blocks, accessing
int)- use \(s\) bits to find set
- valid? + tag match = hit
- no match? old line gets envicted and overwritten
- use block offset to find starting byte to read
int - what if we were reading a long? we'd need bytes past the end of the block
- would be slow and messy to read across block boundaries
- this is why we want everything aligned to an address that's a multiple of its size!
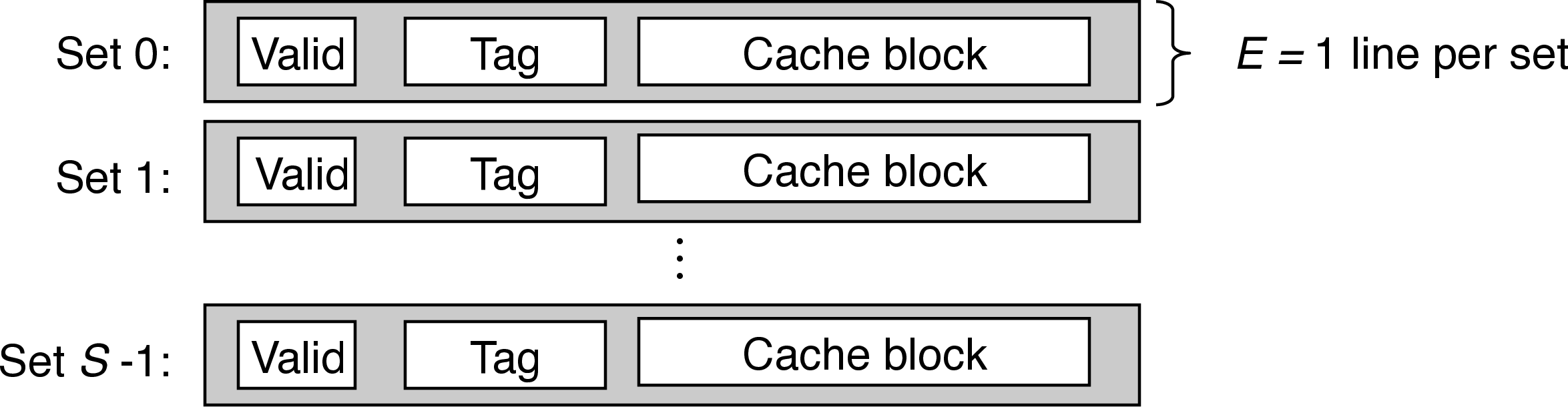
- when there is one line per set (\(E=1\)), the cache is a direct-mapped cache
- three cache resolution steps: set selection, line matchting, word extraction
4.0.1 Set Selection
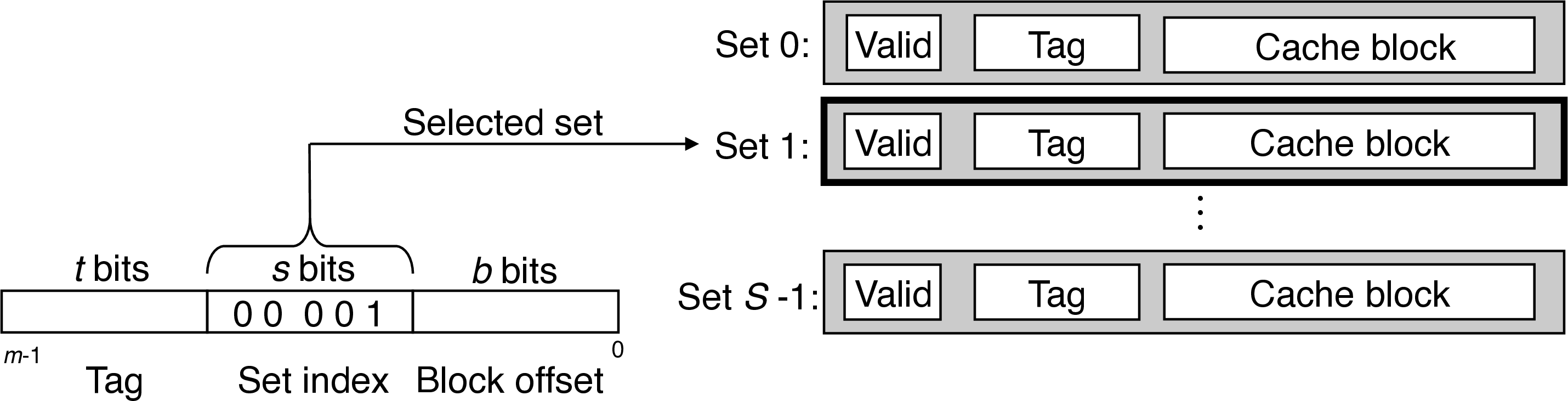
interpret set bits an unsigned integer index
4.0.2 Line Matching
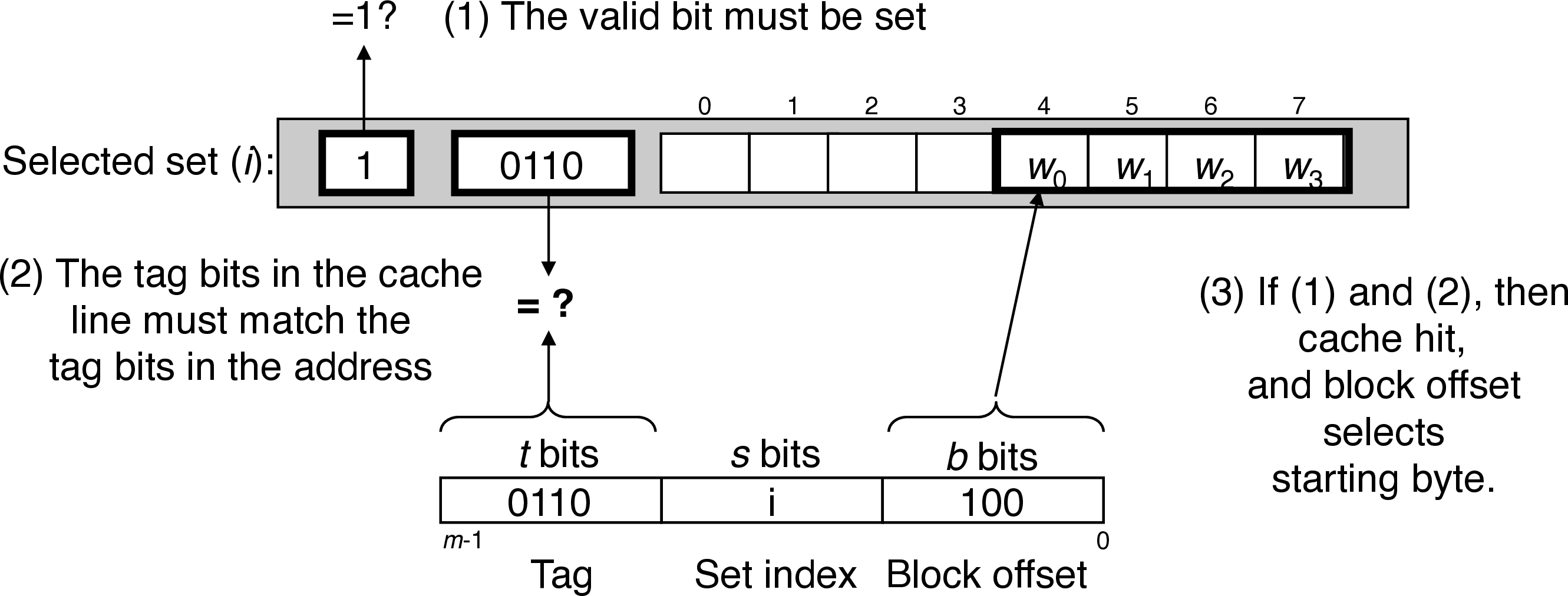
4.0.3 Word Selection
block offset bits indicate the offset of the first byte of the target word
4.0.4 Line Replacement
on a cache miss, replace the line in the set with the newly retrieved line (since there's only one in a direct-mapped cache)
4.0.5 Conflict Misses
- thrashing between blocks that index to the same set is common and can cause significant slowdown
- often when array sizes are powers of two
- easy solution is to add padding between data to push temporally local values into different sets
5 Set Associative Caches
- spreadsheet example (8 byte blocks, accessing
short)- use \(s\) bits to find set
- valid? + tag match = hit (have to compare to both tags)
- no match? one line is selected for evictiong (random, LRU, etc.)
- use block offset to find starting byte to read
short
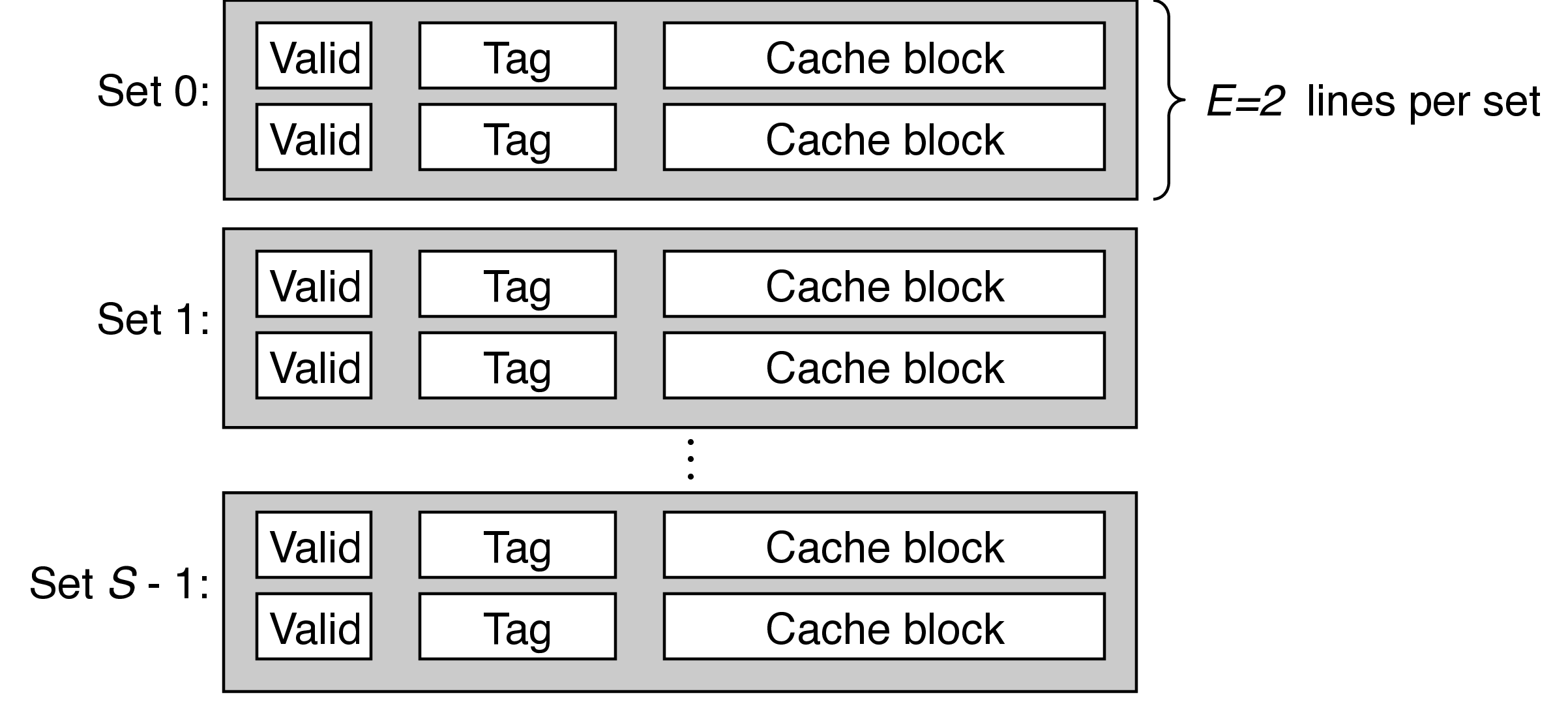
- A cache with \(1 < E < C/B\) is called an $E$-way associative cache
5.0.1 Set Selection
interpret set bits an unsigned integer index
5.0.2 Line Matching & Word Selection
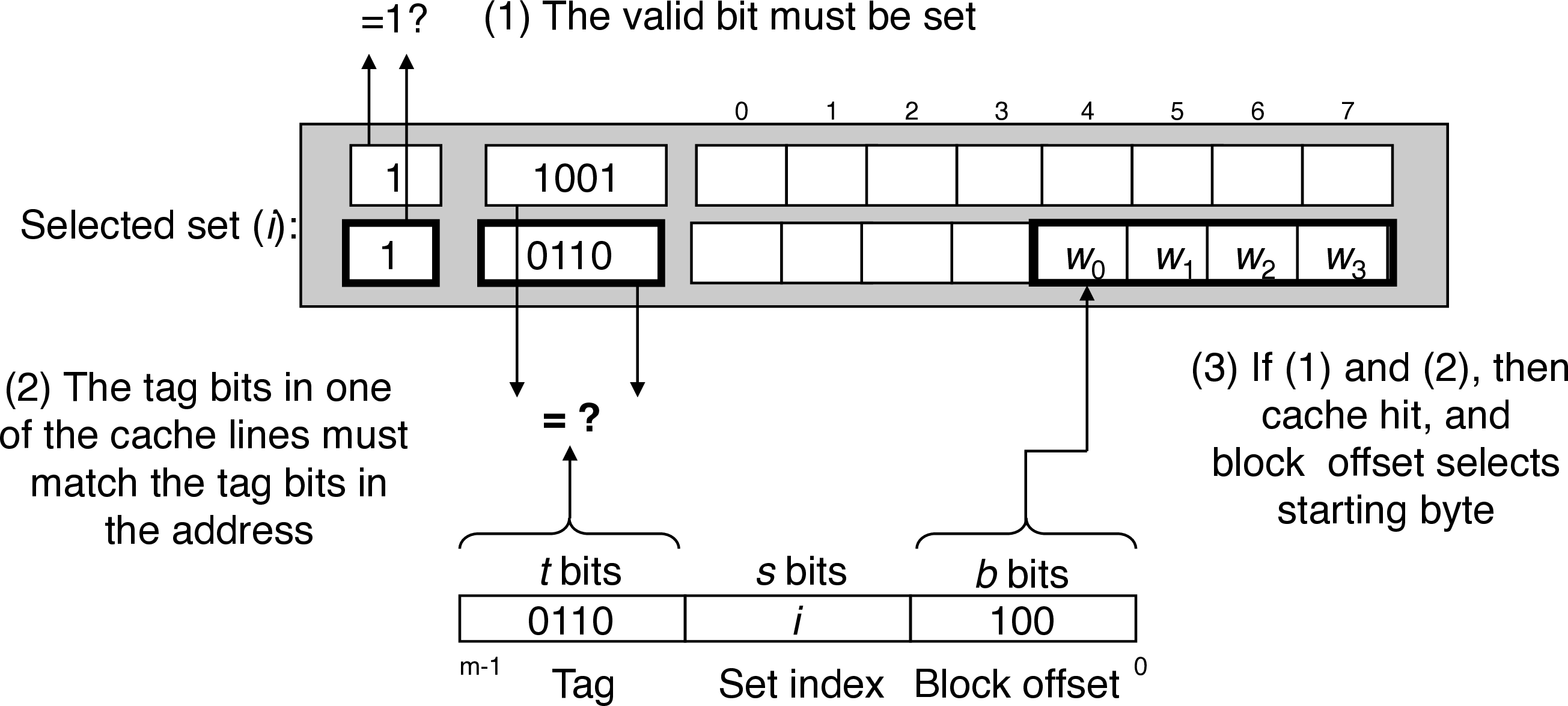
- has to compare tag bits with multiple lines
- conventional memory takes and address and returns the value there vs associative memory that takes a key and returns a value from a matching (key, value) pair
- each set acts like a small associative memory
5.0.3 Line Replacement
- replace empty lines first
- random, least frequently used (LFU), and least recently used (LRU) possible policies
6 Fully Associative Caches
- when a single set contains all the cache lines (\(E = C/B\))
- difficult to scale line matching, so only appropriate for small caches
7 Issues with Writes
- writing to a cached word is a write hit
- what happens after the cache updates its copy?
- write-through: immediately write block containing the update to the next lower level (simple, but causes bus traffic with every write)
- write-back: defer further writes until updated block is evicted (reduces bus traffic, but cache must maintain a dirty bit to track which lines have been written to)
- what happens after the cache updates its copy?
- miss policies:
- write-allocate: load the block, then write (usually goes with write-back)
- no-write-allocate: bypass, write directly to next lower level (usually goes with write-through)
8 Writing Cache-Friendly Code
- cache-friendly practices: repeated references to local variables (can store in registers) and stride-1 reference patterns (caches store contiguous blocks)
- minimize the number of cache misses in each inner loop
8.1 Blocking
- strategy for making matrix operations cache-friendly
9 EXTRA Cache Performance
- miss rate: fraction of memory references that result in a cache miss
- hit rate: fraction of memory references that result in a cache hit (\(1 - miss rate\))
- hit time: time to deliver a resident word to the CPU
- miss penalty: additional time required due to a miss
9.0.1 Impact of Cache Size
large cache results in higher hit rate, but increased hit time (larger memories tend to run slower)
9.0.2 Impact of Block Size
larger blocks favor spatial locality over temporal locality, and increase the miss penalty due to longer transfer times (64 byte block size of Core i7 and other modern systems is a compromise)
9.0.3 Impact of Associtivity
- higher associtivity protects against thrashing by providing more lines per set
- but higher associtivity is expensive and hard to make fast (more tag bits per line, additional LRU state bits per line, additional control logic)
- can also increase hit time and miss penalty
9.0.4 Impact of Write Strategy
- write-through is simpler, can use a write buffer that works independently of the cache to update memory, and read misses don't trigger writes
- write-back frees up bandwidth for I/O by reducing transfers (also important lower in the hierachry where transfer times are long)