Buffer Pool Practice Problems
- Why does a database system need a buffer pool manager? Under what conditions might its function be uncessary?1
- How does the buffer pool manager know when to write a page out to disk?2
- Why does the system need to be able to tell the buffer pool manager to pin pages?3
- It is important to be able to quickly find out if a block is present in the buffer, and if so where in the buffer it resides. Given that database buffer sizes are very large, what (in-memory) data structure would you use for this task?4
- Standard buffer managers assume each page is of the same size and costs the same to read. Consider a buffer manager that, instead of LRU (least recently used), uses the rate of reference to objects, that is, how often an object has been accessed in the last \(n\) seconds. Suppose we want to store in the buffer objects of varying sizes, and varying read costs (such as web pages, whose read cost depends on the site from which they are fetched). Suggest how a buffer manager may choose which page to evict from the buffer.5
- Give an example of a workload where a least-recently-used replacement policy for the buffer pool be a bad choice.6
Footnotes:
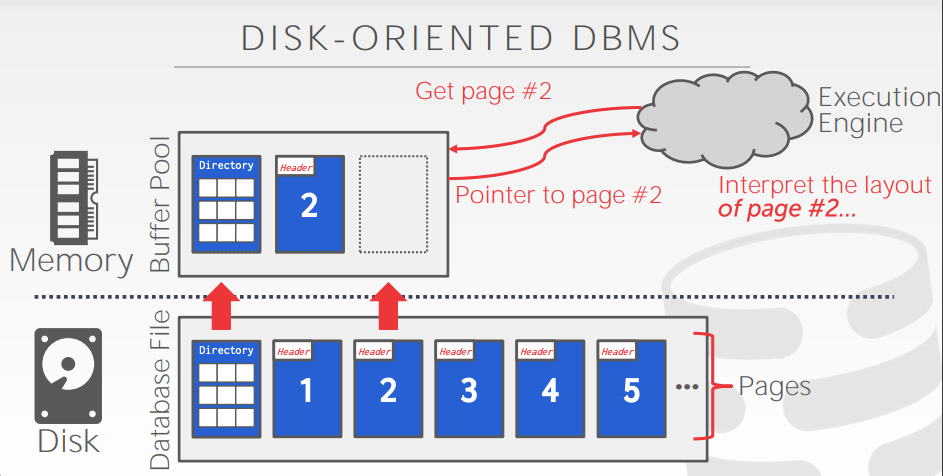
The data for the typical database will exist on non-volatile storage (SSD, HDD, etc.). Since access to this storage is much slower than memory, we want to bring data that the system is working with into memory. A DBMS needs a component to manage moving data to and from disk—this is the job of the buffer pool manager. If our entire database fits in memory, we can just load the entire thing once, and a lot of the management the buffer pool is doing becomes unnecessary. That said, we still have considerations around when to write pages back out to disk, and the DBMS probably still benefits from managing this itself.
The buffer pool maintains a dirty bit per page. This bit indicates whether a page has been modified since being loaded into memory. When the buffer pool would evict a page from memory, it uses the dirty bit to tell whether that page needs to be written out to disk at that time.
The buffer pool manager will replace pages in memory to make room for new pages that the DBMS requests. If some part of the system is currently using a page, it's important that page remain in memory. Thus, a page can be pinned in order to prevent it from being replaced.
A hash table would be an ideal data structure for this task. It provides constant time lookups even for very large amounts of data.
A good solution would make use of a priority queue to evict pages, where the priority (\(p\)) is ordered by the expected cost of re-reading a page given it’s past access frequency (\(f\)) in the last \(n\) seconds, it's re-read cost (\(c\)), and its size \(s\):
\begin{equation} p=f∗c∕s \end{equation}The buffer manager should choose to evict pages with the lowest value of \(p\), until there is enough free space to read in a newly referenced object.
If we are performing a sequential scan over the tuples of a relation \(R\) (i.e., looping through them once), the tuples we just referenced will not be needed again. Under an LRU policy, however, their page would be the last to be replaced. This is an example where a toss-immediate (free a page as soon as we're done with it) or most-recently-used policy would be more appropriate than LRU.