Indexes and B+ Tree Practice Problems
- Indices speed query processing, but it is usually a bad idea to create indices on every attribute, and every combination of attributes, that are potential search keys. Explain why.1
- Is it possible in general to have two clustering indices on the same relation for different search keys? Explain your answer.2
- What is the difference between a clustering index and a secondary index?3
- Construct a B+ tree for the following set of key values: 2, 3, 5, 7, 11, 17, 19, 23, 29, 31. Assume that the tree is initially empty and values are added in ascending order. Construct B+ trees for the cases where the number of pointers that will fit in one node (i.e., number of children per node) is as follows:4
- \(M = 4\)
- \(M = 6\)
- \(M = 8\)
- Suppose you are given a database schema and some queries that are executed frequently. How would you use the above information to decide what indices to create?5
- For each B+ tree from problem 3, show the steps involved in the following queries:6
- Find records with a search-key value of 11.
- Find records with a search-key value between 7 and 17, inclusive.
Footnotes:
Reasons for not keeping indices on every attribute include:
- Every index requires additional overhead (CPU time, disk I/O) during inserts and deletes
- Indices on non-primary keys might have to be changed on updates, although an index on the primary key might not (since primary keys are typically not modified)
- Extra indices require extra storage space
- For queries that involve conditions on several search keys, efficiency might not be impacted even if only some of the keys have indices on them. Therefore, additional indices may have diminishing returns for database performance.
In general, it is not possible to have two primary indices on the same relation for different keys because the tuples in a relation would have to be stored in different orders to match each index. We could accomplish this by storing the relation twice and duplicating all values, but for a centralized system, this is not efficient.
The clustering index is on the attribute which specifies the sequential order of the file. There can be only one clustering index, while there can be many secondary indices.
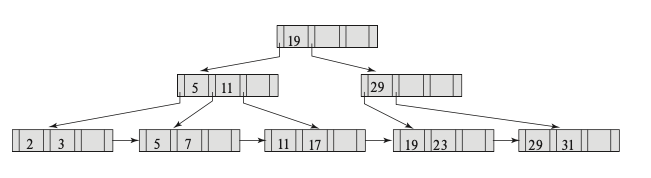
\(M = 4\)
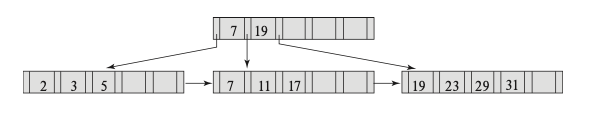
\(M = 6\)
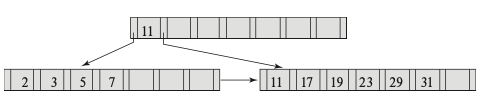
\(M = 8\)
Use the queries to identify attributes where are involved in selection conditions (e.g., WHERE predicates). These are good candidates for indices. Creating indices for primary-key and foreign-key attributes, especially those involved in join conditions, could also improve performance.
For the \(M = 4\) tree:
- Find records with a value of 11
- Search the first-level index; follow the first pointer.
- Search next level; follow the third pointer.
- Search leaf node; follow first pointer to records with key value 11.
- Find records with value between 7 and 17 (inclusive)
- Search top index; follow first pointer.
- Search next level; follow second pointer.
- Search third level; follow second pointer to records with key value 7, and after accessing them, return to leaf node.
- Follow next pointer to next leaf block in the chain.
- Follow first pointer to records with key value 11, then return.
- Follow second pointer to records with with key value 17.
For the \(M = 6\) tree:
- Find records with a value of 11
- Search top level; follow second pointer.
- Search next level; follow second pointer to records with key value 11.
- Find records with value between 7 and 17 (inclusive)
- Search top level; follow second pointer.
- Search next level; follow first pointer to records with key value 7, then return.
- Follow second pointer to records with key value 11, then return.
- Follow third pointer to records with key value 17.
For the \(M = 8\) tree:
- Find records with a value of 11
- Search top level; follow second pointer.
- Search next level; follow first pointer to records with key value 11.
- Find records with value between 7 and 17 (inclusive)
- Search top level; follow first pointer.
- Search next level; follow fourth pointer to records with key value 7, then return.
- Follow eighth pointer to next leaf block in chain.
- Follow first pointer to records with key value 11, then return.
- Follow second pointer to records with key value 17.